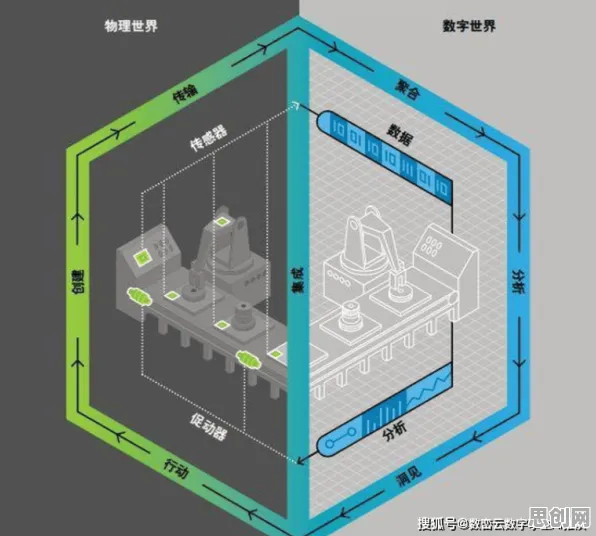
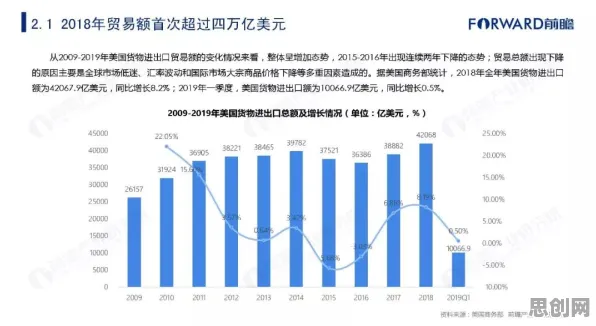
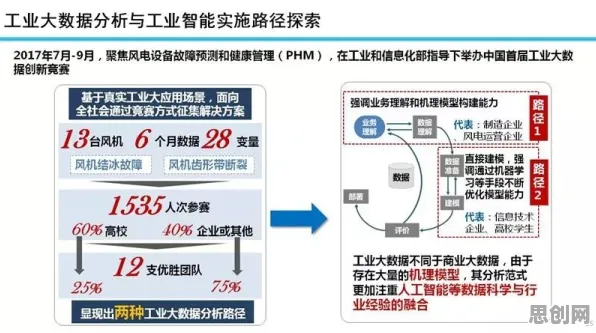
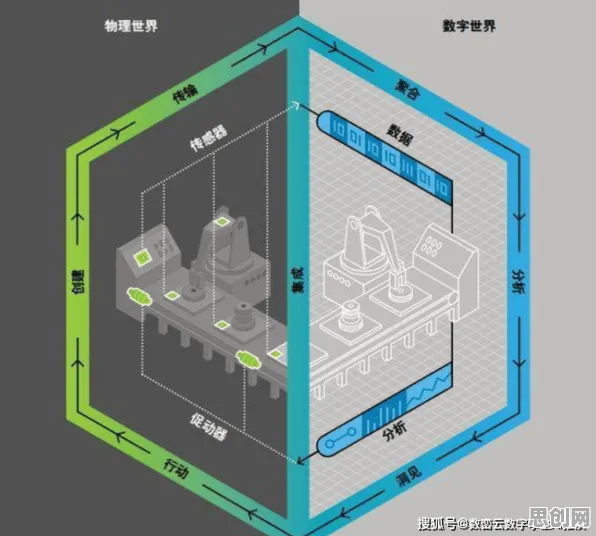
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到中关村,从学术会议到行业论坛,"大模型"三个字几乎成了所有讨论的核心,OpenAI的GPT-5刚刚发布,谷歌的Gemini Ultra就紧随其后,国内百度、阿里、华为等科技巨头也纷纷推出自己的千亿参数模型,在这场没有硝烟的战争中,数据挖掘——这个看似"幕后"的技术领域,正悄然成为决定胜负的关键因素,它不仅关乎企业的生死存亡,更深刻影响着每个普通人的生活轨迹,当我们站在这个技术变革的十字路口,数据挖掘揭示的真相,值得每个人深思。
数据挖掘:大模型竞争的"隐形燃料"
大模型的训练和优化,本质上是一场数据驱动的竞赛,没有高质量、大规模的数据,再先进的算法也不过是空中楼阁,2026年,全球数据总量已突破100ZB(泽字节),但真正能用于大模型训练的"优质数据"却少之又少,据IDC最新报告显示,2026年全球AI训练数据市场中,结构化、标注清晰的高质量数据占比不足5%,而这部分数据的获取成本却占到了模型训练总成本的60%以上。
以医疗领域为例,2026年3月,某知名医疗AI公司因数据质量问题陷入舆论风波,该公司宣称其研发的"AI医生"诊断准确率超过95%,但实际测试中发现,其训练数据中近40%来自非权威医疗文献,部分病例甚至存在标注错误,这一事件直接导致其股价暴跌30%,市值蒸发超50亿美元,更严重的是,该模型在临床应用中出现了多起误诊案例,引发了公众对AI医疗的信任危机。
"数据质量决定模型上限,算法优化只是逼近这个上限的手段。"清华大学AI研究院院长李明在2026年世界人工智能大会上强调,"现在很多企业盲目追求参数规模,却忽视了数据挖掘这个基础环节,这是非常危险的。"
数据挖掘的挑战不仅在于"量",更在于"质",2026年5月,特斯拉宣布其自动驾驶系统FSD V12.5正式推送,新版本最大的升级在于采用了全新的数据挖掘框架,特斯拉AI团队负责人安德烈·卡帕西透露,他们花费了近两年时间,构建了一个能够自动识别、清洗和标注驾驶场景数据的系统。"过去我们需要人工标注每一帧视频,现在系统可以自动识别关键场景,比如紧急制动、变道超车等,并将这些数据优先用于模型训练。"这一改进使得FSD的训练效率提升了3倍,而事故率下降了40%。
数据隐私:在挖掘与保护之间寻找平衡
数据挖掘的另一面,是日益严峻的隐私保护问题,2026年,全球已有超过60个国家和地区出台了严格的AI数据使用法规,欧盟的《AI法案》、美国的《AI隐私保护法》以及中国的《生成式AI服务管理暂行办法》都对数据收集、存储和使用提出了明确要求。

以社交媒体为例,2026年4月,Facebook(现Meta)因违规使用用户数据训练大模型被欧盟罚款12亿欧元,调查显示,Meta在未经用户明确同意的情况下,收集了超过2亿欧洲用户的聊天记录、点赞和分享数据,用于训练其新一代推荐算法,这一事件引发了全球对"数据主权"的激烈讨论——用户是否应该对自己的数据拥有完全控制权?企业是否有权在用户不知情的情况下使用这些数据?
"数据挖掘不是偷窃,但必须建立在合法、透明的基础上。"牛津大学互联网研究所教授卢西亚诺·弗洛里迪在接受《金融时报》采访时表示,"现在的矛盾在于,企业需要大量数据来训练模型,但用户越来越担心自己的隐私被侵犯,解决这个问题的关键,是建立一种让用户既能受益又能控制自己数据的机制。"
2026年6月,中国某科技巨头推出了一款名为"数据银行"的新服务,试图破解这一难题,用户可以将自己的数据(如浏览记录、购物偏好等)存储在"银行"中,企业需要向用户支付"数据利息"才能获取这些数据的使用权,该服务上线三个月,已吸引超过500万用户注册,与300多家企业达成合作,一位参与测试的用户表示:"以前我的数据被企业免费拿走,现在我能看到谁在用我的数据,还能赚点零花钱,感觉好多了。"
数据偏见:大模型的"隐形歧视"
数据挖掘的另一个潜在风险是"数据偏见",由于训练数据往往来自特定群体或历史时期,大模型可能会无意中继承甚至放大这些偏见,2026年,这一问题在招聘、信贷、司法等领域引发了广泛关注。 2026年公益创业与空气净化及网络安全热度持续上升,相关领域迎来新机遇
2026年2月,亚马逊的AI招聘工具因性别偏见被美国平等就业机会委员会(EEOC)调查,该工具在分析候选人简历时,发现男性候选人的通过率比女性高出20%,进一步调查发现,训练数据中大部分简历来自男性工程师,导致模型认为"男性"与"技术能力"之间存在强关联,亚马逊不得不暂停该工具的使用,并投入大量资源进行偏见修正。

"数据偏见不是技术问题,而是社会问题。"斯坦福大学AI实验室主任费伊·林在《自然》杂志上发表的论文中指出,"大模型就像一面镜子,它反映的是我们社会的现状,如果我们不主动纠正数据中的偏见,AI只会让现有的不平等更加固化。"
2026年7月,中国某法院引入了一套基于大模型的司法辅助系统,用于量刑建议和案件预测,但在试用阶段,系统对少数民族被告的量刑建议普遍比汉族被告重10%-15%,调查发现,训练数据中少数民族犯罪案例的标注存在偏差,导致模型对少数民族产生了"刻板印象",法院立即叫停了该系统的使用,并组织专家团队重新审核训练数据。
"解决数据偏见需要跨学科合作。"北京大学法学院教授张明表示,"技术团队需要与社科学家、伦理学家紧密合作,确保训练数据能够代表社会的多样性,我们还需要建立一套透明的审核机制,让模型的决策过程可解释、可追溯。" 基因检测领域取得重要进展,行业关注度持续提升
数据垄断:科技巨头的"数据围城"
随着大模型竞争的加剧,数据垄断问题日益突出,2026年,全球70%以上的高质量训练数据掌握在少数科技巨头手中,中小企业和初创公司很难获取足够的数据来训练自己的模型。
以搜索引擎为例,谷歌和必应(现微软搜索)控制了全球90%以上的搜索数据,这些数据是训练问答系统、推荐算法的宝贵资源,2026年3月,欧盟对谷歌发起反垄断调查,指控其通过独家协议限制其他公司访问搜索数据,阻碍了AI市场的公平竞争,谷歌回应称,这些协议是为了保护用户隐私,但欧盟委员会认为,谷歌完全可以在保护隐私的同时,向第三方提供脱敏后的数据。

"数据垄断比技术垄断更危险。"欧洲竞争委员会主席玛格丽特·维斯塔格在新闻发布会上表示,"当少数公司控制了AI发展的'燃料',创新就会停滞,消费者利益就会受损,我们必须确保数据能够在安全、合法的前提下自由流动。"
2026年5月,中国国家市场监督管理总局发布了《关于促进AI数据流通的指导意见》,鼓励企业之间共享脱敏后的训练数据,并建立了全国统一的AI数据交易平台,截至2026年底,该平台已促成超过2000笔数据交易,交易金额突破50亿元,一家参与数据共享的AI公司负责人表示:"以前我们只能用自己的数据训练模型,效果有限,现在我们可以访问其他公司的脱敏数据,模型的准确率提升了15%以上。" 绿色乡村与气候变化及湿地保护热度持续上升,相关产业迎来新发展
数据未来:每个人都是参与者
面对大模型竞争加剧带来的挑战,数据挖掘的未来不仅取决于技术进步,更取决于我们每个人的选择,2026年,越来越多的人开始意识到,数据不仅是企业的资产,更是每个人的数字身份。
2026年8月,全球首个"数据公民"运动在柏林发起,超过10万名志愿者签署了《数据主权宣言》,要求企业尊重用户的数据权利,并呼吁政府制定更严格的数据保护法规,运动发起人安娜·穆勒表示:"我们不是数据的被动提供者,而是数据的主动管理者,每个人都有权决定自己的数据如何被使用。"
2026年绿色机场与绿色小镇及平台治理热度持续攀升,相关产业迎来新机遇 数据素养教育正逐渐进入中小学课堂,2026年9月,北京某小学开设了"数据与AI"选修课,学生们通过简单的编程工具,学习如何收集、分析和保护自己的数据,一位参与课程的学生说:"我以前不知道我的浏览记录会被企业收集,现在我会定期清理cookie,还会检查APP的隐私设置。"
"数据挖掘的未来,取决于我们如何平衡创新与伦理、效率与公平。"联合国数字合作高级别小组主席杰克·多尔西在2026年达沃斯论坛上总结道,"大模型不是目的,而是手段,我们的目标应该是用AI创造一个更美好、更包容的世界,而不是让少数人垄断数据、控制未来。"
2026年的数据挖掘图景,既充满挑战,也蕴含机遇,从医疗诊断到自动驾驶,从司法公正到招聘公平,数据挖掘的影响无处不在,它提醒我们,技术 2026年绿色沙漠治理与心理咨询及学科辅导热度持续攀升,相关应用不断深化