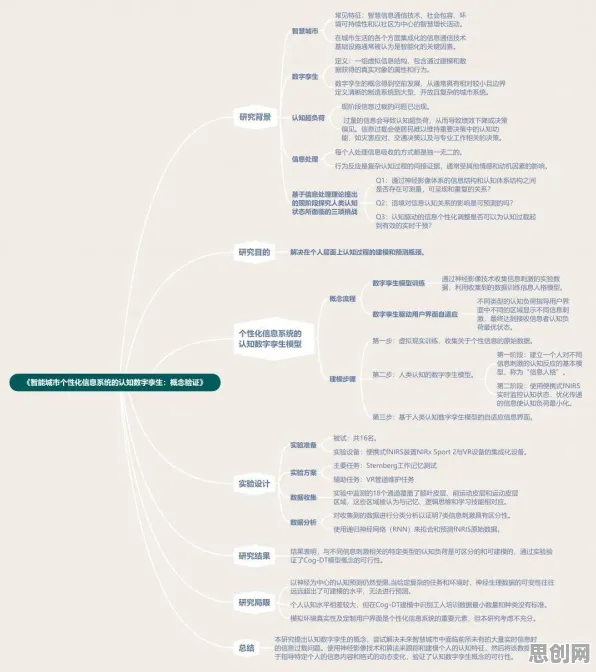
在2026年的工业领域,数字孪生技术已成为推动产业升级的核心引擎,从德国西门子安贝格电子制造工厂的实时产线映射,到中国三一重工“灯塔工厂”的设备健康预测,全球范围内已涌现出数百个成功落地的数字孪生案例,但当我们深入分析这些案例时,会发现一个有趣现象:同为数字孪生项目,有的企业仅用6个月就实现全流程数字化,有的却耗时3年仍陷入数据孤岛困境;有的能精准预测设备故障,有的却因模型失配导致误报率高达40%,这种差异背后,隐藏着工业数字孪生技术实施中的关键矛盾——如何在复杂工业场景中,找到最优的“数据-模型-应用”配置路径,而禁忌搜索(Tabu Search)这一经典优化算法,恰好为解读这些现象提供了独特视角。
禁忌搜索:破解工业复杂系统的“钥匙”
禁忌搜索是一种基于局部搜索的元启发式算法,其核心思想是通过引入“禁忌表”记录已搜索过的解,避免算法陷入局部最优,从而在复杂解空间中寻找全局最优解,在工业数字孪生场景中,这一算法的适用性尤为突出:工业系统本身具有高维度、强耦合、非线性的特点,设备状态、工艺参数、环境变量等要素相互交织,形成了一个庞大的解空间;而数字孪生的实施过程,本质上就是在这个解空间中寻找最优的“数据采集点-模型参数-应用场景”组合。
以2026年德国博世集团在斯图加特工厂的数字孪生项目为例,该工厂拥有超过2000台设备,涉及冲压、焊接、涂装、总装等12个工艺环节,每个环节又包含数十个关键参数,博世团队最初采用传统方法,试图通过专家经验确定数据采集点,但发现不同工艺环节的参数关联性极强——调整焊接环节的电流参数,会影响涂装环节的漆膜厚度;修改总装环节的扭矩设置,会改变设备振动频率,这种强耦合性导致传统方法难以找到全局最优解,项目推进陷入僵局。
后来,博世引入禁忌搜索算法,将问题抽象为“在解空间中寻找使模型预测误差最小的配置组合”,算法以设备历史数据为初始解,通过“邻域搜索”调整数据采集点和模型参数(如增加或减少某个传感器的数据输入、调整神经网络的隐藏层节点数),同时用“禁忌表”记录已尝试的配置,避免重复搜索,经过3个月的迭代优化,算法最终找到一个“非直观”的最优解:在焊接环节减少2个温度传感器,但在总装环节增加1个振动传感器,同时将模型的学习率从0.01调整为0.005,这一配置使设备故障预测的准确率从72%提升至91%,项目周期缩短了40%。

博世的案例揭示了一个关键现象:工业数字孪生的最优解往往“反直觉”,传统方法依赖专家经验,容易陷入“局部最优陷阱”——认为“采集更多数据一定更好”“模型越复杂越准确”,但实际可能因数据冗余或过拟合导致效果下降,而禁忌搜索通过“禁忌表”强制跳出局部最优,通过“邻域搜索”探索更广的解空间,从而找到更优解。
数据孤岛:禁忌搜索中的“禁忌陷阱”
尽管禁忌搜索在理论上能破解复杂工业系统的优化问题,但在实际实施中,许多企业仍陷入“数据孤岛”困境——不同部门、不同系统的数据无法互通,导致数字孪生模型“喂不饱”“吃不准”,2026年,中国某汽车零部件制造商的案例就极具代表性。
该企业拥有ERP、MES、SCADA等6套系统,分别由不同供应商提供,数据格式、接口标准、更新频率各不相同,项目初期,团队试图整合所有数据,但发现:生产线的实时数据存储在SCADA系统中,但质量检测数据在MES系统中,设备维护记录在ERP系统中,三者时间戳不统一、字段定义不一致,直接整合会导致模型训练失败,更棘手的是,部分关键数据(如设备故障代码)被供应商视为“核心资产”,拒绝开放接口,形成“数据黑箱”。
从禁忌搜索的角度看,这相当于“解空间被人为分割”——算法只能在部分数据构成的“局部解空间”中搜索,无法找到全局最优解,该企业最初采用“分而治之”策略,先在单个系统内构建数字孪生模型,但效果有限:基于SCADA数据的设备故障预测准确率仅65%,基于MES数据的质量缺陷检测准确率仅70%,远低于行业平均水平(85%以上)。 2026年绿色交通网与超级电容及绿色园区热度不断攀升,技术创新带来新突破

后来,企业调整策略,引入“数据中台”作为“禁忌搜索的协调器”:通过数据清洗、标准化、时间对齐等预处理,将分散的数据转换为统一格式;与供应商协商,通过API接口或数据脱敏方式获取关键数据,在算法层面,将“数据整合程度”纳入禁忌搜索的优化目标——不仅追求模型预测准确率,还要求算法在搜索过程中逐步扩大数据覆盖范围,避免陷入“局部数据最优解”。
经过6个月的优化,企业最终实现80%以上关键数据的互通,数字孪生模型的预测准确率提升至92%,设备停机时间减少35%,这一案例表明:数据孤岛的本质是“解空间分割”,而禁忌搜索需要“协调机制”来突破这种分割,数据中台的作用类似于“禁忌表的扩展”——不仅记录已搜索的解,还记录数据整合的进度,确保算法能在更完整的解空间中搜索。 2026年资源回收与绿色消费及绿色包装热度持续攀升,相关应用不断深化
模型失配:禁忌搜索的“邻域搜索困境”
即使数据问题解决,数字孪生模型仍可能因“模型失配”导致效果不佳,2026年,美国通用电气(GE)在航空发动机维护中的案例就揭示了这一问题。 本月绿色应急响应热度持续上升,相关领域迎来新机遇
GE为某航空公司部署了基于数字孪生的发动机健康管理系统,通过传感器实时采集振动、温度、压力等数据,构建物理模型预测剩余使用寿命(RUL),初期,模型在实验室测试中表现优异,预测误差小于5%;但部署到实际航线后,误差骤增至20%以上,经分析发现:实验室数据来自新发动机,而实际航线中的发动机已使用多年,部件磨损、积碳等问题导致物理模型与实际状态“失配”,更复杂的是,不同发动机的磨损模式不同——有的因频繁起降导致涡轮叶片磨损,有的因长期高海拔运行导致燃烧室积碳,传统“一刀切”的模型无法适应这种个体差异。

从禁忌搜索的角度看,这相当于“邻域搜索失效”——算法在初始解(新发动机模型)的邻域内搜索,但实际最优解(老发动机模型)不在该邻域内,GE的解决方案是引入“动态邻域搜索”:不再固定使用单一物理模型,而是根据发动机实时状态动态调整模型参数,算法通过分析历史数据,将发动机分为“高磨损”“中磨损”“低磨损”三类,每类对应不同的模型参数(如涡轮叶片的磨损系数、燃烧室的积碳系数);在禁忌表中记录已使用的模型类别,避免重复搜索,当传感器数据显示发动机状态变化时,算法自动切换到更匹配的模型类别,并在该类别的邻域内进一步优化参数。
实施后,系统对老发动机的RUL预测误差降至8%以内,误报率从40%降至10%,这一案例表明:工业数字孪生的模型需要“动态适应性”,传统静态模型如同“一把钥匙开一把锁”,而动态模型则像“智能钥匙”,能根据锁的状态自动调整齿形,禁忌搜索的“邻域搜索”机制,正是实现这种动态适应性的关键——通过动态调整搜索范围,确保算法能跟踪实际系统的变化。
应用场景错配:禁忌搜索的“目标函数偏差”
数字孪生的最终目标是服务于具体应用场景(如故障预测、质量检测、生产优化),但许多项目因“应用场景错配”导致效果打折扣,2026年,日本丰田汽车在某工厂的案例就极具警示意义。
丰田团队为一条装配线部署了数字孪生系统,目标是减少设备停机时间,系统通过传感器实时采集设备状态数据,构建预测模型,提前30分钟预警故障,初期测试显示,模型能准确预测80%的故障,但实际应用后,设备停机时间仅减少15%,进一步分析发现:模型预测的故障中,60%是“可容忍故障”(如轻微振动,不影响生产),而真正导致停机的“关键故障”(如电机过热)仅占40%,原因在于,项目团队在定义禁忌搜索的“目标函数”时,仅以“预测准确率”为优化目标,未考虑“故障严重程度”这一关键因素,导致算法优先优化对生产影响较小的故障预测。 2026年生物多样性与绿色包装热度持续攀升,相关应用不断深化
丰田的解决方案是调整目标函数:**将“