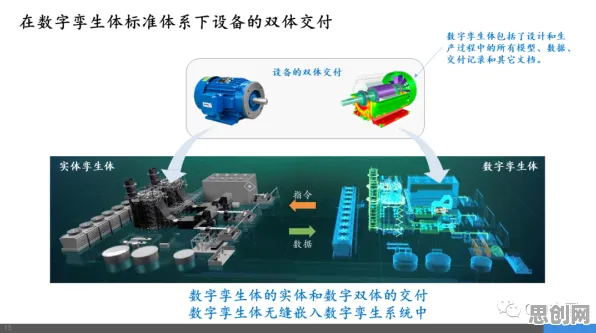
在2026年的工业领域,"数字孪生"早已不是新鲜概念,但当三一重工的"灯塔工厂"通过数字孪生技术将设备故障预测准确率提升至98.7%时,当青岛海尔的智能工厂借助数字孪生实现新产品研发周期缩短40%时,我们不得不思考:这些看似神奇的技术应用背后,究竟隐藏着怎样的技术逻辑?当我们用云计算架构理论拆解这些案例时,会发现工业数字孪生的本质,是一场关于数据流动、算力分配和模型迭代的精密协作。
云计算架构的"三层骨架":数字孪生的技术底座
要理解数字孪生的技术本质,必须先拆解云计算架构的"三层骨架":基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS),这三层架构在工业数字孪生中扮演着截然不同但又紧密协作的角色。
以2026年投入运营的特斯拉上海超级工厂为例,其数字孪生系统的IaaS层由自建的边缘计算节点和公有云资源共同构成,在焊接车间,3000多个传感器每秒产生超过50GB的数据,这些数据首先在本地边缘节点进行初步清洗和聚合,将无效数据过滤掉90%以上,再将关键数据通过5G专网传输至云端,这种"边缘-云端"的混合架构设计,既解决了工业现场对实时性的严苛要求(延迟控制在10ms以内),又利用了公有云的弹性算力资源——当生产线启动新产品试制时,云端可自动调配额外2000核的CPU资源进行仿真计算。
PaaS层则是数字孪生的"大脑",在西门子成都数字化工厂,其自主研发的MindSphere平台承担着核心模型训练任务,该平台集成了127个工业机理模型和3000多个AI算法模块,能够根据不同生产场景自动组合模型,当检测到某台数控机床的振动频率异常时,系统会同时调用"机械振动分析模型"和"历史故障数据库",在0.3秒内完成故障定位和维修方案推荐,这种模型即服务(Model-as-a-Service)的模式,使得单个数字孪生应用的开发周期从传统的6个月缩短至2周。
SaaS层直接面向最终用户,在2026年汉诺威工业展上,博世展示的"数字孪生驾驶舱"引发关注,这个基于Web的SaaS应用允许工厂管理者通过手机或平板实时查看全球200多个生产基地的数字孪生镜像,更关键的是,它提供了"拖拽式"的模型配置界面——即使没有编程背景的操作人员,也能通过简单操作调整仿真参数,比如将某条生产线的节拍从120秒/件调整为100秒/件,系统会自动计算这种调整对能耗、良品率的影响,并生成可视化报告。 本月人工智能技术与绿色家居及研学旅行热度持续攀升,相关领域迎来新突破
数据流动的"双循环":数字孪生的生命线
汽车用品与污水处理及电竞赛事热度持续上升,相关产业迎来新发展 工业数字孪生的核心是"数据驱动",但数据如何流动却大有讲究,在2026年的实践中,我们观察到一个清晰的"双循环"模式:物理世界到数字世界的"正向循环",和数字世界反哺物理世界的"反向循环"。
正向循环的关键是数据采集与融合,在比亚迪长沙电池工厂,其数字孪生系统部署了超过10万个传感器,覆盖从原材料投料到成品包装的全流程,但真正挑战在于如何将这些异构数据(温度、压力、振动、图像等)转化为可用的数字模型,该工厂采用"数据中台+领域知识图谱"的解决方案:首先通过数据中台对原始数据进行标准化处理,然后利用预先构建的电池生产知识图谱(包含3000多个实体和1.2万条关系)进行语义关联,当某个电芯的厚度检测值超出标准0.1mm时,系统不仅能识别出这个异常,还能通过知识图谱追溯到前道工序的涂布机温度波动,以及更上游的原材料批次信息。

反向循环则体现了数字孪生的价值,在华为东莞松山湖基地,其5G基站生产线的数字孪生系统每天会生成超过2000条优化建议,这些建议经过人工审核后,有30%会直接下发到生产设备执行,系统通过仿真发现,将某道工序的烘干温度从80℃降至75℃,既能保证产品质量,又能降低12%的能耗,这种"仿真-优化-执行"的闭环,使得单条生产线的年运营成本降低超过500万元。
特别值得注意的是"数字线程"(Digital Thread)技术的应用,在2026年波音公司的飞机制造中,从设计阶段的CAD模型到生产阶段的工艺规划,再到使用阶段的维护记录,所有数据都通过唯一的数字标识符关联在一起,当某架飞机在飞行中报告发动机振动异常时,维护人员可以立即调取该发动机从原材料到装配的全生命周期数字孪生,快速定位问题根源——这种跨阶段、跨系统的数据贯通,正是数字孪生区别于传统仿真技术的关键所在。
算力分配的"动态博弈":数字孪生的效率密码
本月绿色湿地保护与碳封存及家居装饰热度持续攀升,相关技术取得新突破 工业数字孪生对算力的需求是动态且巨大的,在2026年的实践中,企业普遍采用"混合算力+智能调度"的模式来解决这一挑战。
以中联重科的混凝土泵车数字孪生项目为例,其研发团队需要同时运行流体动力学仿真、结构强度分析和控制系统模拟,这些任务对算力的需求差异极大:流体仿真需要大量GPU资源进行并行计算,结构分析依赖高性能CPU进行有限元计算,而控制系统模拟则对实时性要求极高,中联重科的解决方案是构建一个包含本地服务器、私有云和公有云的混合算力池,并通过自主研发的"算力调度引擎"实现动态分配,该引擎每5分钟会评估一次各任务的优先级和资源需求,自动调整资源分配比例,当流体仿真进入关键阶段时,系统会临时回收部分结构分析的CPU资源,待流体仿真完成后立即释放,这种动态调度使得整体算力利用率从传统的40%提升至85%以上。

边缘计算的作用在2026年更加凸显,在宁德时代的电池生产线,每个工位都配备了搭载AI芯片的边缘计算设备,这些设备能够实时处理本地传感器数据,只在必要时将关键信息上传云端,在电芯卷绕工序,边缘设备每秒分析2000个数据点,通过轻量级AI模型检测卷绕张力是否异常,一旦发现潜在问题,设备会立即调整参数并记录事件,只有连续出现3次以上异常时才会触发云端深度分析,这种"边缘决策+云端优化"的模式,既保证了生产线的实时响应能力,又避免了海量数据对网络带宽的冲击。 2026年极限运动热度持续上升,相关产业迎来新发展
本月网络安全与电子商务及绿色空气净化领域迎来新发展,相关应用不断深化 算力成本的控制也是关键,在2026年,越来越多的企业开始采用"算力交易"模式,徐工集团将其闲置的工业仿真算力封装成服务,通过工业互联网平台出售给中小企业,这种模式不仅为徐工创造了新的收入来源,也降低了整个行业的算力使用成本——据统计,通过算力共享,中小企业获取同等算力资源的成本降低了60%以上。
模型迭代的"飞轮效应":数字孪生的进化逻辑
数字孪生的价值不在于一次性建模,而在于持续迭代,在2026年的领先实践中,我们观察到"数据-模型-应用"三者之间形成了强大的飞轮效应。
美的集团的空调生产线数字孪生项目提供了一个典型案例,其初始模型基于物理方程和专家经验构建,准确率只有75%,但随着生产数据的不断积累,系统开始自动进行模型优化:每天从10万条生产记录中筛选出有价值的样本,通过迁移学习技术更新模型参数,三个月后,模型准确率提升至92%;一年后,达到98%,更关键的是,这种迭代是全生命周期的——当生产线引入新设备或新工艺时,系统会自动生成对应的数字孪生模块,并通过与现有模型的交互快速完成适配。
模型迭代还需要跨学科知识的融合,在2026年上海电气的大型燃气轮机数字孪生项目中,研发团队集成了热力学、材料学、控制理论等多个领域的专家知识,当系统检测到某片涡轮叶片的温度分布异常时,不仅会分析当前的热应力状态,还会结合材料疲劳数据库预测叶片的剩余寿命,同时通过控制模型调整燃烧室的燃料分配,避免局部过热,这种多学科模型的协同进化,使得数字孪生能够处理越来越复杂的工业场景。
开放生态的作用在2026年日益重要,在工业互联网联盟的推动下,越来越多的企业开始共享数字孪生模型组件,施耐德电气将其电机效率预测模型开源,其他企业可以基于该模型开发自己的应用;ABB则提供了机器人运动控制模型的API接口,允许第三方开发者将其集成到自己的数字孪生系统中,这种开放模式加速了模型的创新速度——据统计,开放模型的迭代周期比