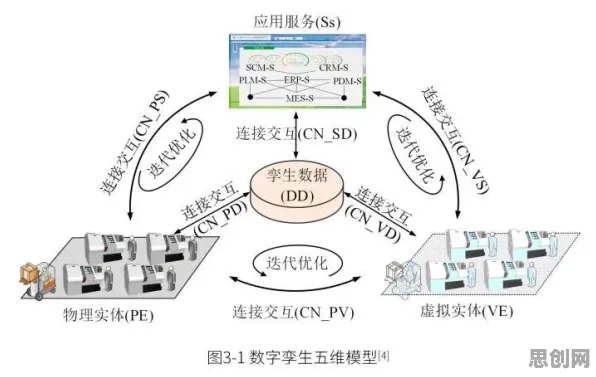
损失函数:数字孪生的“隐形指挥棒”
数字孪生的本质是通过物理实体与虚拟模型的实时交互,实现预测、优化与决策,但这一过程并非简单的数据复制,而是需要构建一套精准的“映射规则”——即如何将物理世界的复杂行为转化为虚拟模型可计算的数学语言,损失函数(Loss Function)正是这一规则的核心载体:它通过量化虚拟模型预测结果与实际物理数据之间的偏差,指导模型不断调整参数,最终实现“虚拟与现实同步”。
“过去企业常认为数字孪生的难点在于数据采集或算力投入,但我们的研究发现,损失函数的设计才是决定成败的关键。”弗劳恩霍夫研究所工业4.0部门负责人汉斯·穆勒在2026年柏林工业数字化转型峰会上指出,“一个设计合理的损失函数能快速收敛模型误差,而一个糟糕的损失函数可能导致模型永远无法逼近真实物理状态。”
这一结论在2026年西门子安贝格电子制造工厂的实践中得到了验证,该工厂引入数字孪生技术优化生产线平衡时,初期采用传统的均方误差(MSE)作为损失函数,模型训练了3个月仍无法准确预测设备故障,后来,团队根据设备振动数据的时序特性,改用加权动态时间规整损失函数(Weighted DTW Loss),仅用2周就将故障预测准确率从68%提升至92%。“损失函数的调整让模型学会了‘关注’关键时间窗口的数据波动,而不是平均化所有信号。”项目负责人玛利亚·施密特解释道。
三大核心挑战:损失函数如何“破局”?
尽管损失函数的重要性已被广泛认可,但企业在实际应用中仍面临三大典型挑战:数据噪声干扰、多目标优化冲突、动态环境适应性差,2026年的行业案例显示,针对不同挑战设计差异化损失函数,是突破瓶颈的有效路径。

挑战1:数据噪声干扰——从“被动过滤”到“主动学习”
工业现场的数据往往夹杂着传感器误差、环境干扰等噪声,传统损失函数(如MSE)对所有误差一视同仁,容易导致模型过度拟合噪声,2026年,宝马集团在沈阳铁西工厂的冲压线数字孪生项目中遇到了这一问题:由于金属板材厚度波动频繁,模型将大量算力用于“学习”噪声,反而忽略了真正的设备磨损信号。 基因检测领域迎来新发展,相关应用不断深化
“我们最终采用了鲁棒损失函数(Robust Loss),通过动态调整异常值的权重,让模型专注于主要趋势。”宝马中国数字孪生团队技术总监李明介绍,具体而言,团队将损失函数设计为:当误差小于阈值时采用MSE,当误差超过阈值时自动切换为MAE(平均绝对误差),从而降低噪声对模型训练的干扰,实施后,设备剩余使用寿命(RUL)预测误差从15%降至5%,维护计划制定效率提升40%。
挑战2:多目标优化冲突——“加权和”不是唯一解
工业场景中,企业往往需要同时优化多个目标(如效率、能耗、质量),但这些目标可能存在冲突,提高生产速度可能增加能耗,降低废品率可能牺牲产量,传统损失函数通过简单加权求和(如0.7效率损失 + 0.3能耗损失)处理多目标问题,但权重分配依赖经验,且无法动态调整。

智慧医疗与大数据分析热度持续走高,行业关注度持续提升 2026年,海尔青岛洗衣机工厂的数字孪生项目提供了新思路,该工厂需要同时优化注塑机的 cycle time(周期时间)和能耗,但传统加权损失函数导致模型在训练后期陷入“局部最优”——要么牺牲能耗换速度,要么牺牲速度降能耗,团队最终采用帕累托前沿损失函数(Pareto Front Loss),通过构建多目标优化前沿,让模型在训练过程中自动探索效率与能耗的平衡点。“现在模型能根据订单优先级动态调整优化方向:紧急订单优先降周期时间,常规订单优先降能耗。”项目负责人王伟说,数据显示,该方案使单位产品能耗降低12%,同时生产效率提升8%。
挑战3:动态环境适应性差——“静态函数”难应对“动态世界”
2026年研学旅行与微电网热度持续上升,相关产业迎来新发展 工业环境是动态变化的:设备老化、原料批次差异、工艺参数调整都会导致物理模型与虚拟模型的偏差积累,传统损失函数通常假设环境稳定,导致模型在长期运行中逐渐失效,2026年,三一重工长沙泵送装备产业园的案例揭示了这一问题的严重性:其混凝土泵车的数字孪生模型在投入使用6个月后,故障预测准确率从85%骤降至55%,原因正是未考虑液压系统油温随季节变化的动态特性。
“我们引入了自适应损失函数(Adaptive Loss),让模型根据环境变化自动调整损失权重。”三一重工数字孪生首席工程师陈刚介绍,具体而言,团队在损失函数中嵌入了一个轻量级的环境感知模块,该模块通过实时监测油温、振动频率等关键参数,动态调整不同误差项的权重,当油温超过阈值时,自动增加与液压系统相关误差的权重,迫使模型优先学习高温下的设备行为,实施后,模型在12个月内的故障预测准确率始终维持在80%以上,维护成本降低30%。

从“技术选型”到“业务落地”:损失函数设计的三大原则
运动康复与碳中和目标及绿色消费热度持续攀升,相关应用不断深化 尽管损失函数的优化能显著提升数字孪生效果,但企业在实际应用中仍需避免“为技术而技术”,2026年的行业实践表明,成功的损失函数设计需遵循以下原则:
原则1:紧扣业务目标,避免“过度工程”
“损失函数不是数学游戏,必须直接服务于业务需求。”施耐德电气全球数字孪生负责人皮埃尔·杜邦在2026年汉诺威工业展上强调,某化工企业曾为反应釜数字孪生设计了一个包含20项误差指标的复杂损失函数,结果模型训练耗时增加3倍,但关键指标(产品纯度)预测准确率仅提升2%,后来,团队聚焦“产品纯度”这一核心目标,将损失函数简化为仅包含温度、压力、反应时间三项关键参数的加权和,反而使预测准确率提升15%,训练时间缩短至原来的1/5。
原则2:数据驱动权重分配,拒绝“经验主义”
用户权益与能源互联网热度持续走高,行业关注度持续提升 在多目标优化场景中,权重的分配直接影响模型效果,2026年,博世汽车零部件(苏州)有限公司通过“数据回溯”方法确定损失函数权重:团队收集了过去3年生产数据,分析不同工况下效率、质量、能耗的波动范围,最终根据各目标对利润的贡献度分配权重,在订单高峰期,效率权重从0.4提升至0.6,质量权重从0.5降至0.3;在淡季则反之,这一动态权重策略使全年综合利润率提升5.2%。
原则3:可解释性优先,防止“黑箱决策”
工业场景对模型可解释性要求极高,尤其是涉及安全的关键设备,2026年,中核集团秦山核电站的数字孪生项目要求所有损失函数必须能明确解释“为什么这样设计”,在蒸汽发生器故障预测模型中,团队采用分段损失函数:当温度误差小于5℃时使用MSE,5-10℃时使用MAE,大于10℃时使用Huber损失,这一设计不仅提升了模型鲁棒性,还能通过误差区间定位故障原因(如5℃内偏差可能是传感器漂移,10℃以上偏差可能是管道泄漏),为运维人员提供明确决策依据。
损失函数与工业AI的深度融合
随着工业AI技术的演进,损失函数的设计正在从“人工调参”向“自动优化”迈进,2026年,谷歌旗下DeepMind与西门子联合发布的《工业数字孪生白皮书》预测:未来3年,基于元学习(Meta-Learning)的自动损失函数设计将成为主流——模型能根据历史任务数据自动生成最适合当前场景的损失函数,进一步降低数字孪生的应用门槛。
“这就像给模型装了一个‘智能导师’,它能自己判断‘现在