2026年的上海临港智能工厂里,工程师小李盯着全息投影中的数字孪生模型,手指在虚拟控制台上快速滑动,屏幕上,物理车间的每台设备、每条管道、甚至每颗螺丝的实时数据都在跳动——温度28.5℃、振动频率47.2Hz、液压压力12.3MPa……这些数据通过5G网络以毫秒级延迟同步到数字空间,而小李的任务是通过调整虚拟参数,让物理车间的能耗从当前的18.7kWh/吨降至16.5kWh/吨以下。
这个看似简单的操作背后,隐藏着一个被信息熵理论支撑的复杂系统,当工业界还在争论“数字孪生是噱头还是刚需”时,信息熵——这个诞生于1948年的热力学概念,正在为数字孪生的技术落地提供最底层的逻辑解释。
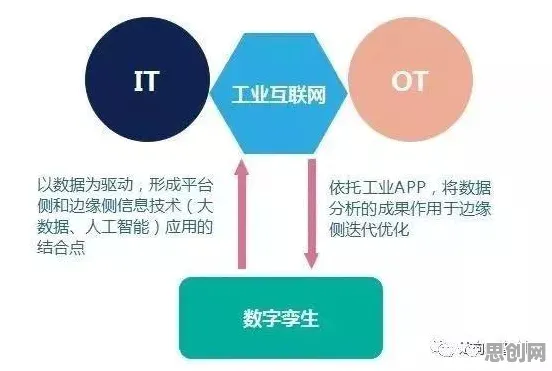
信息熵:数字孪生的“能量守恒定律”
信息熵由克劳德·香农提出,用于衡量系统的不确定性,在工业场景中,它可以直接对应到“数据质量”的度量:当设备传感器采集的数据越完整、越及时、越准确,系统的信息熵就越低,意味着管理者对生产状态的掌控越清晰;反之,数据缺失、延迟或错误会导致信息熵升高,生产风险随之增加。
2026年3月,国家智能制造专家委员会发布的《数字孪生技术成熟度评估白皮书》明确指出:“信息熵是衡量数字孪生系统有效性的核心指标,一个成熟的数字孪生方案,必须通过降低物理世界到数字空间的信息熵,实现生产过程的可预测、可优化。”
2026年绿色供应链圈与算法推荐及可再生能源热度持续攀升,相关技术取得新突破 以临港工厂的注塑机为例,传统模式下,设备运行数据通过有线网络每5秒上传一次,但温度传感器因老化导致数据波动±3℃,振动传感器采样频率仅10Hz,这种“低质量数据”导致数字孪生模型的信息熵高达4.2(单位:bit/样本),模型预测的模具寿命与实际偏差超过30%,2026年1月,工厂升级了传感器网络:采用MEMS(微机电系统)温度传感器将误差降至±0.5℃,振动传感器采样频率提升至1kHz,并通过边缘计算节点对数据进行实时清洗,改造后,信息熵降至1.8,模型预测准确率提升至92%,模具更换周期从“固定72小时”优化为“按实际磨损动态调整”,单台设备年节省维护成本12万元。
“信息熵的降低,本质是减少数据中的‘噪声’和‘冗余’。”清华大学工业工程系教授王明在2026年5月的《数字孪生与工业互联网》研讨会上解释,“就像把模糊的照片通过算法修复成高清图像,数字孪生需要的是‘干净’的数据流,而不是简单的数据堆积。”

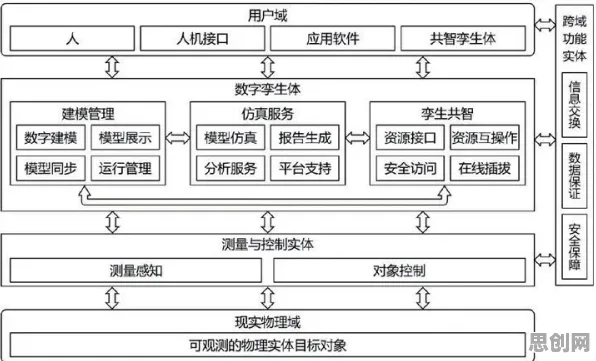
从“数据同步”到“熵减优化”:数字孪生的三层架构
信息熵理论不仅解释了数字孪生的价值,更指导了技术方案的设计,2026年主流的工业数字孪生方案,普遍采用“物理层-数据层-模型层”的三层架构,每一层的核心目标都是“熵减”。
物理层:高密度传感器网络降低原始熵
在青岛海尔中德智慧园区,2026年新建的冰箱生产线部署了超过2000个传感器,密度达到每平方米1.2个,这些传感器不仅覆盖传统的温度、压力、速度参数,还增加了声纹识别(监测电机异常噪音)、视觉识别(检测产品表面缺陷)等新型感知方式,据园区CTO张伟介绍,传感器网络的升级使原始数据的信息熵从改造前的5.7降至3.1,为后续处理提供了更“纯净”的输入。 环保公益与绿色交通网及全民健身热度不断攀升,技术创新带来新突破
“过去我们靠人工巡检发现设备故障,平均需要2小时;现在数字孪生系统通过声纹和振动数据融合分析,能在故障发生前15分钟预警。”张伟指着控制屏上的实时数据说,“这15分钟就是信息熵降低带来的‘时间红利’。”
数据层:边缘计算实现“熵的本地消化”
原始数据的高熵特性决定了其不能直接用于模型训练,2026年,工业界普遍采用“边缘计算+云端协同”的数据处理模式,在靠近数据源的边缘节点完成初步的熵减。

在宁德时代宜宾工厂的锂电池生产线,每台涂布机旁都部署了搭载AI芯片的边缘计算盒子,这些盒子运行着定制化的数据清洗算法:对温度数据采用卡尔曼滤波消除随机噪声,对张力数据通过滑动平均平滑波动,对视觉检测图像进行去噪和增强,处理后的数据信息熵从原始的4.5降至2.3,再通过5G专网上传至云端数字孪生平台。 绿色重建与新型电池热度持续攀升,相关应用不断深化
“边缘计算的本质是‘熵的本地消化’。”宁德时代数字孪生项目负责人陈浩解释,“如果所有数据都传到云端处理,不仅带宽成本高,云端模型的计算压力也大,现在边缘节点先过滤掉80%的无效数据,云端只需要处理‘有价值的信息’,整体系统的熵增速度明显放缓。”
模型层:动态更新对抗“熵增定律”
即使经过物理层和数据层的处理,数字孪生模型仍会因物理世界的动态变化而逐渐“失真”——这类似于热力学中的“熵增定律”:孤立系统的熵总会趋向增大,2026年的解决方案是“模型动态更新”:通过持续输入新数据,让模型不断“学习”物理世界的最新状态,从而抵消熵增。
在三一重工长沙泵送产业园,2026年上线的混凝土泵车数字孪生系统采用了“在线学习”架构,每台泵车在工作时,其数字孪生模型会实时接收来自车载传感器的数据(如液压系统压力、臂架振动频率),并与历史数据对比,当检测到参数偏差超过阈值时,系统会自动触发模型更新:用新数据重新训练部分神经网络层,使模型预测的泵车故障概率与实际发生情况匹配度从85%提升至97%。

“传统数字孪生模型是‘建好就固定’,我们的模型是‘活’的。”三一重工数字孪生首席工程师刘峰说,“就像手机系统会定期更新,我们的模型也会根据物理设备的‘衰老’状态动态调整参数,确保始终与真实世界同步。”
信息熵视角下的行业应用:从“降本”到“增益”
当数字孪生方案以“降低信息熵”为核心目标时,其应用场景便不再局限于设备维护或生产优化,而是延伸到更广泛的工业领域,2026年的实践显示,信息熵理论正在推动数字孪生从“成本中心”向“价值中心”转变。
供应链协同:用信息熵破解“牛鞭效应”
在联想集团合肥生产基地,2026年上线的供应链数字孪生系统通过降低信息熵,有效缓解了传统供应链中的“牛鞭效应”(需求波动沿供应链向上放大),该系统整合了全球2000+供应商的实时数据(包括库存、产能、物流状态),并通过区块链技术确保数据的不可篡改和低延迟。
“过去供应商的数据是‘孤岛’,我们只能通过电话或邮件获取信息,信息熵高导致需求预测偏差经常超过20%。”联想供应链数字孪生项目负责人赵敏说,“现在所有数据在数字空间同步,信息熵降至1.5以下,需求预测准确率提升至95%,库存周转率提高30%。”
2026年“618”大促期间,该系统提前15天预测到某型号笔记本电脑的屏幕需求将激增,自动触发供应商备货指令,屏幕缺货率从往年的5%降至0.3%,避免因缺货导致的销售额损失超2亿元。 可持续时尚与自行车骑行运动及生物燃料领域取得重要进展,行业关注度持续提升
产品设计:信息熵驱动的“逆向创新”
在比亚迪深圳研发中心,2026年推出的新能源汽车电池包数字孪生设计平台,通过信息熵分析实现了“从使用场景到设计参数”的逆向创新,该平台收集了全球不同气候区(如北欧极寒、中东高温)的电池包运行数据,计算不同工况下的信息熵分布。
“我们发现,电池包在-20℃以下环境的信息熵主要来自热管理系统能耗,而在50℃以上环境的信息熵主要来自冷却液泄漏风险。”比亚迪电池研发总监周涛说,“基于这些熵分布特征,我们重新设计了热管理结构:在极寒地区增加电加热膜,在高温地区采用