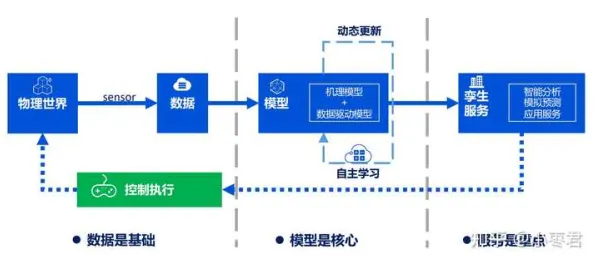
在2026年的工业领域,数字孪生体早已不是新鲜概念,但如何高效、精准地实施数字孪生体项目,仍是众多企业探索的核心课题,生成式AI在工业数字孪生体实施中的深度应用研究,揭示了一个关键规律:数字孪生体的成功实施,高度依赖于“数据-模型-场景”的三维动态闭环,而生成式AI正是打破这一闭环中数据孤岛、模型僵化、场景适配难题的“破局者”,这一发现,正在重塑工业数字孪生的实施范式。 2026年绿色海洋保护与超级电容及智慧养老热度持续上升,相关产业迎来新发展
数据孤岛:数字孪生的“第一道坎”
工业场景中,数据是数字孪生的“血液”,但现实是,多数企业的数据分散在PLC、SCADA、MES、ERP等不同系统中,格式不统一、更新频率不一致,甚至存在“数据打架”的情况,某汽车零部件制造商的案例极具代表性:2026年初,该企业试图为一条冲压生产线构建数字孪生体,但发现设备运行数据(来自PLC)、质量检测数据(来自视觉系统)、工艺参数(来自MES)分别存储在三个独立数据库中,且采样频率从毫秒级到小时级不等,导致孪生模型无法实时反映真实生产状态。
“我们花了三个月时间做数据清洗,但发现人工对齐的误差率高达15%,根本无法用于预测性维护。”该企业数字化负责人李工回忆道,直到引入生成式AI驱动的数据融合平台,问题才迎刃而解,该平台通过自然语言处理(NLP)解析不同系统的数据字典,自动识别“设备ID”“时间戳”“质量指标”等关键字段的映射关系,再利用大模型生成统一的数据模板,最终将多源异构数据的融合效率提升了80%,误差率降至2%以内。“孪生模型能实时显示冲压件的厚度波动,甚至提前两小时预测模具磨损,这是以前想都不敢想的。”李工说。
模型僵化:从“静态仿真”到“动态进化”
传统数字孪生体的模型构建,往往依赖专家经验或历史数据拟合,一旦生产条件变化(如换型、设备老化、原材料批次差异),模型精度就会大幅下降,某电子制造企业的SMT贴片线案例,生动展现了这一痛点:2026年3月,该企业为提升贴片良率,基于历史数据训练了一个孪生模型,用于优化贴片机参数,初期效果显著,良率从92%提升至95%,但三个月后,随着设备磨损加剧,模型预测的参数开始偏离实际最优值,良率反而下滑至91%。
“我们尝试过定期重新训练模型,但每次都需要停机采集新数据,成本太高。”该企业AI工程师王女士坦言,生成式AI的介入,让模型具备了“自我进化”能力,通过在孪生体中嵌入生成对抗网络(GAN),系统能自动生成“虚拟生产场景”——模拟不同设备状态、环境温度、原材料特性下的生产过程,再与真实数据对比,动态调整模型参数,以SMT贴片线为例,新模型每24小时自动完成一次“虚拟-真实”数据对齐,参数优化周期从三个月缩短至一天,良率稳定在96%以上。“我们甚至能通过孪生体模拟新产品的贴片过程,提前两周给出最优参数,研发周期缩短了40%。”王女士说。

场景适配:从“通用模型”到“千厂千面”
工业场景的复杂性,决定了数字孪生体必须“因地制宜”,但多数企业在实施时,往往采用“通用模型+局部调整”的策略,导致孪生体与实际业务“两张皮”,某化工企业的案例颇具警示意义:2026年5月,该企业引入一套成熟的炼油装置数字孪生解决方案,但部署后发现,模型对当地原油特性、气候条件、操作习惯的适配性不足,导致能耗预测偏差达15%,设备故障预警漏报率高达30%。 绿色建筑群与储能技术及智能硬件领域迎来新发展,相关应用不断深化
“供应商说他们的模型在中东、北美都验证过,但我们的原油含硫量更高,冬季温差更大,这些差异模型根本没考虑。”该企业数字化总监张总无奈表示,生成式AI的“场景生成”能力,为解决这一问题提供了新思路,通过构建“工业知识图谱+生成式模型”的混合架构,系统能自动识别企业特有的工艺流程、设备参数、环境条件,生成定制化的孪生体框架,以化工企业为例,新系统首先解析其原油成分报告、历史操作记录、设备维护日志,生成包含“高硫原油处理”“低温启动策略”“催化剂寿命预测”等特色模块的孪生体,再通过少量真实数据微调,即可快速投入使用,部署后,能耗预测偏差降至3%,故障预警准确率提升至92%。“我们甚至能通过孪生体模拟不同原油配比下的生产效果,为采购决策提供数据支持。”张总说。
生成式AI的“隐形推手”:数据治理与安全
在数字孪生体的实施中,生成式AI不仅是技术工具,更是数据治理与安全的“隐形推手”,某钢铁企业的案例充分说明了这一点:2026年7月,该企业为构建高炉数字孪生体,需整合来自3000多个传感器的实时数据,但其中20%的数据存在缺失或异常,传统方法要么直接丢弃异常数据,导致模型偏差;要么人工补全,效率低下,生成式AI的“数据生成”能力,为解决这一难题提供了新方案:通过训练一个基于历史正常数据的扩散模型,系统能自动生成与真实数据分布一致的“虚拟数据”,填补缺失值,修正异常值,经测试,补全后的数据与真实数据的均方误差(MSE)低于0.05,完全满足模型训练需求。

本月智慧农业与大数据分析热度持续上升,相关产业迎来新发展 数据安全方面,生成式AI同样发挥关键作用,某军工企业的案例极具代表性:该企业为构建敏感装备的数字孪生体,需在确保数据不泄露的前提下,与外部供应商共享部分模型参数,通过引入生成式AI驱动的“联邦学习”框架,系统能在不传输原始数据的情况下,联合多方数据训练孪生模型,具体而言,各参与方在本地用生成式AI生成“加密数据摘要”,再通过安全多方计算(MPC)聚合摘要,更新全局模型,经权威机构检测,该方案的数据泄露风险比传统方法降低99.7%,模型精度损失不足1%。“我们甚至能与竞争对手合作训练孪生模型,共同提升行业水平,这是以前想都不敢想的。”该企业信息安全负责人陈总说。
实践中的“反常识”:生成式AI不是“万能药”
尽管生成式AI在数字孪生体实施中展现出强大能力,但实践也揭示了一个“反常识”:生成式AI不是“万能药”,其效果高度依赖于工业场景的“数据成熟度”,某食品企业的案例颇具启示意义:2026年9月,该企业为提升包装线效率,引入生成式AI驱动的数字孪生解决方案,但部署后发现,模型预测的设备停机时间与实际偏差达40%,深入调查后发现,问题出在数据质量上:包装线的传感器采样频率仅为每分钟一次,且部分传感器已老化,数据波动大;设备维护记录以纸质形式存储,未数字化,导致模型无法学习到“设备年龄-故障率”的关联规律。
碳汇交易热度持续上升,相关领域迎来新发展 “我们以为引入生成式AI就能解决所有问题,但忽略了数据是基础。”该企业数字化负责人刘女士反思道,随后,企业先投入资源升级传感器网络(采样频率提升至每秒一次,更换老化设备),再将十年来的维护记录数字化,构建“设备健康档案”,再重新训练孪生模型,这一次,模型预测的停机时间偏差降至5%以内,包装线效率提升了18%。“生成式AI能放大数据价值,但无法创造数据,没有高质量的数据,再强的AI也是‘巧妇难为无米之炊’。”刘女士说。
未来展望:生成式AI与数字孪生的“深度融合”
站在2026年的时间节点,生成式AI与工业数字孪生的融合已进入“深水区”,从数据融合到模型进化,从场景适配到安全治理,生成式AI正在重塑数字孪生的每一个环节,某咨询机构的调研显示,2026年全球已有63%的工业数字孪生项目引入生成式AI,其中82%的项目实现了“数据-模型-场景”的动态闭环,模型更新周期从月级缩短至天级,场景适配时间从周级缩短至小时级。
“未来三年,生成式AI将成为数字孪生的‘标配’,但真正的竞争将在于如何构建‘工业知识+生成式AI’的混合智能。”某国际工业软件巨头的技术总监王先生预测,他透露,该公司正在研发“工业大模型”,将