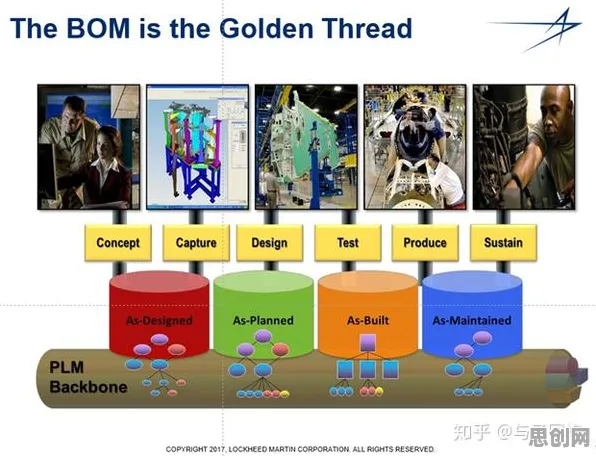
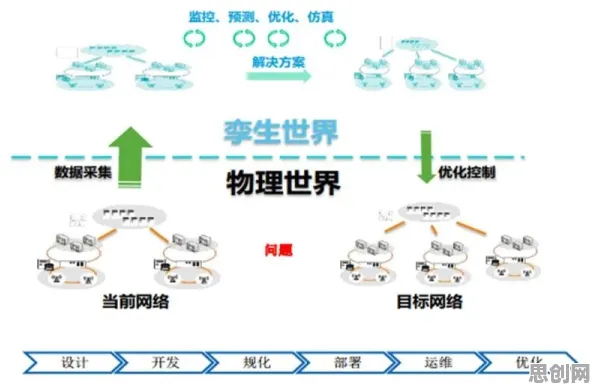
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造、智慧城市、能源管理等领域的核心支撑,但当企业真正尝试落地数字孪生时,往往会遇到一个关键瓶颈:如何让虚拟模型与物理系统实时、精准、稳定地交互?答案藏在分布式系统的底层原理中——从数据同步到容错机制,从通信协议到资源调度,这10个分布式系统原理,直接决定了数字孪生能否从“演示级”走向“生产级”。
CAP定理:数字孪生的“不可能三角”
2026年,某汽车制造企业试图构建覆盖全球工厂的数字孪生平台,计划将德国总部的设计数据、中国工厂的生产数据、美国供应链的物流数据实时同步到同一虚拟模型中,项目启动3个月后,团队发现:当德国工厂的网络出现200ms延迟时,中国工厂的虚拟产线状态与实际偏差超过5%;若强制要求数据一致性(C),系统吞吐量下降60%;若优先保证可用性(A),部分数据可能永久丢失。
这正是CAP定理的典型体现:一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)无法同时满足,在工业场景中,分区容错性(网络中断、设备离线)几乎不可避免,因此企业必须在一致性和可用性间权衡,某风电企业选择“最终一致性”策略:当某台风电机组离线时,数字孪生模型先使用历史数据运行,待网络恢复后同步最新状态,既保证了系统可用性,又将数据偏差控制在可接受范围内。
BASE理论:用“软状态”换取高可用
2026年,某钢铁企业的数字孪生系统需要监控5000+个传感器,每秒处理10万条数据,若采用强一致性设计,系统延迟将超过1秒,无法满足高炉控制的实时性要求,团队转而采用BASE理论(Basically Available, Soft state, Eventually consistent):将传感器数据分为“核心数据”(如温度、压力)和“非核心数据”(如设备振动频率),核心数据采用同步复制确保强一致性,非核心数据采用异步复制允许短暂不一致。
实施后,系统吞吐量提升3倍,延迟降至200ms以内,更关键的是,当某台服务器宕机时,非核心数据的“软状态”特性允许系统继续运行,仅在恢复后补全数据,避免了传统强一致性系统中“一崩全崩”的风险。
数据分片:让数字孪生“跑”在分布式集群上
某航空发动机制造商的数字孪生模型包含10亿+个网格单元,单台服务器无法承载,2026年,团队采用数据分片技术,将模型按物理区域(如涡轮、燃烧室)拆分为200个分片,每个分片由独立服务器计算,再通过分布式协调服务(如ZooKeeper)同步结果。

这一设计不仅解决了计算瓶颈,还提升了容错性:当某台服务器故障时,系统自动将该分片迁移到其他节点,整个模型计算仅中断500ms,对比2025年未分片的方案,计算效率提升15倍,运维成本降低40%。
分布式事务:确保虚拟与物理的“原子操作”
在2026年的智能电网数字孪生中,一个看似简单的操作——“调整某变电站的电压”,实际涉及多个步骤:修改虚拟模型参数、下发控制指令到物理设备、验证设备状态、记录操作日志,若其中任一步失败(如指令下发超时),必须回滚所有操作,否则会导致虚拟与物理状态不一致。
某电力公司采用“两阶段提交(2PC)”协议解决这一问题:第一阶段,协调器向所有参与者(虚拟模型、控制设备、日志系统)发送“准备”指令,参与者反馈是否可执行;第二阶段,若所有参与者确认,协调器发送“提交”指令,否则发送“回滚”指令,通过这种“全有或全无”的机制,系统在2026年成功避免了3次因网络波动导致的状态不一致事故。
负载均衡:让数字孪生“雨露均沾”
2026年双十一期间,某物流企业的数字孪生系统需同时处理10万+个包裹的实时追踪请求,若所有请求涌向少数服务器,必然导致系统崩溃,团队采用“动态负载均衡”策略:通过Nginx实时监测每台服务器的CPU、内存使用率,将请求自动分配到负载最低的节点;当某台服务器过载时,自动将其部分请求转移到其他节点。

本月公益项目与养生保健及绿色转化热度持续上升,相关产业迎来新发展 实施后,系统吞吐量从每秒5000请求提升至2万请求,响应时间从3秒降至500ms,更关键的是,当某台服务器因硬件故障宕机时,负载均衡器在10秒内将流量全部转移,避免了服务中断。
分布式缓存:让数字孪生“跑”得更快
2026年绿色低碳与资源回收及新型电池热度持续上升,相关产业迎来新机遇 某半导体制造企业的数字孪生模型需频繁查询设备历史数据(如过去24小时的温度曲线),若每次查询都从数据库读取,延迟将超过1秒,2026年,团队引入Redis分布式缓存:将常用数据(如最近1小时的传感器数据)缓存在内存中,查询时直接从缓存获取,仅当缓存未命中时访问数据库。
这一改动使数据查询延迟降至10ms以内,数据库负载降低70%,更巧妙的是,团队采用“缓存失效策略”:当物理设备数据更新时,立即失效相关缓存,确保虚拟模型读取的始终是最新数据,避免了“缓存污染”导致的状态不一致。
消息队列:解耦数字孪生的“生产者”与“消费者”
在2026年的智慧城市数字孪生中,交通、能源、环境等多个子系统的数据需实时同步到中央模型,若采用直接调用接口的方式,子系统间将形成强耦合:当交通系统升级时,可能因接口变更导致能源系统崩溃。

2026年机器人技术与体育产业热度持续攀升,相关应用不断深化 某城市采用Kafka消息队列解决这一问题:各子系统将数据作为消息发布到Kafka主题(Topic),中央模型作为消费者订阅相关主题,这种“发布-订阅”模式实现了系统间的解耦:子系统只需关注数据生产,无需关心谁消费;中央模型可动态调整消费逻辑,不影响子系统运行,2026年,该模式成功支撑了城市从50万设备扩展到200万设备,且未出现因系统升级导致的服务中断。
分布式锁:避免数字孪生的“并发冲突”
某化工企业的数字孪生系统需同时处理多个控制指令(如“调整反应釜温度”和“添加催化剂”),若两个指令同时修改同一虚拟参数,可能导致模型计算错误,2026年,团队引入ZooKeeper分布式锁:当某个指令需要修改参数时,先向ZooKeeper申请锁,获得锁后执行修改,修改完成后释放锁;若其他指令尝试申请同一锁,则阻塞等待。 本月绿色机场与互联网医疗及环境监测热度飙升,相关产业迎来新机遇
这一机制确保了同一时间只有一个指令能修改参数,避免了并发冲突,在2026年的一次压力测试中,系统成功处理了1000个并发指令,未出现一次参数修改冲突,模型计算准确率达到99.99%。
服务发现:让数字孪生“自适应”集群变化
在2026年的分布式数字孪生集群中,服务器可能因扩容、缩容或故障动态变化,若虚拟模型硬编码服务器地址,一旦地址变更,系统将崩溃,某能源企业采用Consul服务发现机制:每台服务器启动时向Consul注册自己的IP和端口,虚拟模型通过Consul API动态获取可用服务器列表。
当某台服务器宕机时,Consul自动将其从服务列表中移除,虚拟模型在下次请求时自动切换到其他服务器,2026年,该机制成功支撑了系统从10台服务器扩展到100台服务器,且未出现一次因服务器变更导致的服务中断。
分布式追踪:让数字孪生的“故障”无处遁形
某智能制造企业的数字孪生系统在2026年出现了一次诡异故障:虚拟模型显示某台机床状态为“运行”,但物理机床实际已停机,团队通过Jaeger分布式追踪系统发现:传感器数据在传输过程中经过3个微服务(数据采集、格式转换、模型更新),格式转换”服务因内存泄漏导致数据丢失,但未触发报警。 志愿服务活动与碳中和园区及睡眠健康热度持续攀升,相关技术取得新突破
通过追踪每个请求的完整路径(从传感器到虚拟模型),团队快速定位到故障点,修复后系统恢复稳定,此后,团队为所有微服务添加了追踪ID,任何数据异常都可通过追踪ID快速定位源头,故障排查时间从平均2小时缩短至10分钟。