在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正能将其落地并产生实际价值的平台方案,却依然让不少企业又爱又恨,爱的是它带来的效率提升和成本优化潜力,恨的是实施过程中的复杂性和不确定性,当我们深入探究那些成功落地的工业数字孪生平台方案时,会发现一个有趣的现象:这些方案的设计逻辑,竟然和机器学习领域里一个看似不相关的工具——Adam优化器,有着异曲同工之妙,这并非巧合,而是技术演进中必然的逻辑共鸣。
数字孪生的“双胞胎”困境与Adam的适应性智慧
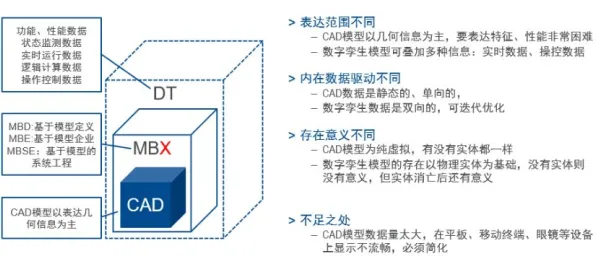
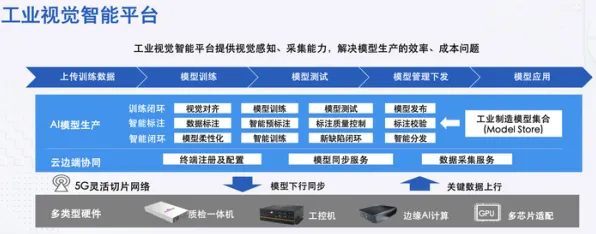
工业数字孪生的核心,是通过物理实体与虚拟模型的实时交互,实现生产过程的可视化、可预测和可优化,但现实中的工业场景远比理论复杂:一条汽车生产线可能涉及上千个传感器,每个传感器的数据频率、精度、噪声水平各不相同;一台风电设备的运行状态受风速、温度、湿度等多维度因素影响,且这些因素之间还存在非线性耦合,这种复杂性导致传统数字孪生方案往往陷入“建了模型却用不起来”的困境——要么模型过于简化,无法反映真实工况;要么模型过于复杂,计算资源消耗巨大,实时性无法保证。
2026年,某头部汽车制造商在推进其“灯塔工厂”建设时,就遇到了这样的难题,他们为一条冲压生产线构建了数字孪生模型,初始版本包含了所有可监测的物理参数,模型精度高达98%,但运行一次仿真需要47分钟,而生产线上的故障平均响应时间只有5分钟,这意味着,当模型算出“这里可能要出问题”时,问题可能已经发生了,项目团队不得不回过头来简化模型,砍掉了30%的参数,结果精度掉到了85%,虽然仿真时间缩短到了8分钟,但漏报率却上升了15%,这种“精度-效率”的两难选择,让项目陷入僵局。
在机器学习领域,Adam优化器正在解决一个类似的问题:如何在高维、非凸、噪声大的损失函数空间中,快速找到全局最优解?传统的梯度下降法要么学习率固定,容易陷入局部最优;要么需要手动调整学习率,效率低下,Adam优化器通过引入“动量”和“自适应学习率”机制,让模型在训练初期能快速探索,后期能精细调整,同时对噪声数据具有鲁棒性,这种“动态适应”的智慧,恰恰是工业数字孪生最需要的。
从算法到方案:自适应架构的工业实践
受Adam优化器的启发,上述汽车制造商的项目团队开始重新设计数字孪生平台的架构,他们不再追求“一步到位”的完美模型,而是构建了一个“分层-动态”的模型体系:底层是基础物理模型,包含设备的基本结构和运动学/动力学方程;中层是数据驱动的修正模型,通过实时传感器数据对基础模型进行动态校正;顶层是场景适配模型,根据当前生产任务(如换型、调产)自动调整模型参数和计算资源分配。
这种架构的核心是“自适应”:就像Adam优化器会根据梯度的一阶矩和二阶矩动态调整学习率一样,数字孪生平台会根据数据质量、计算负载和业务需求动态调整模型精度,当传感器数据噪声较大时,平台会自动降低中层模型的权重,依赖基础模型的稳定性;当生产任务变更时,顶层模型会快速生成新的参数组合,避免重新训练整个模型。
2026年第三季度,该平台在冲压生产线上线试运行,结果令人惊喜:在保持92%模型精度的前提下,仿真时间缩短到了3分钟,漏报率控制在5%以内,更关键的是,由于模型能动态适应不同工况,生产线的一次合格率从91.2%提升到了94.7%,设备综合效率(OEE)提高了8个百分点,项目负责人后来在行业峰会上分享时说:“我们终于找到了数字孪生的‘甜区’——不是追求绝对精确,而是让模型能像Adam优化器一样,在复杂环境中找到最适合当前状态的解。”

数据质量:数字孪生的“梯度”与Adam的“噪声处理”
Adam优化器的另一个优势是对噪声数据的鲁棒性,在工业场景中,数据噪声是普遍存在的问题:传感器老化可能导致数据漂移,网络延迟可能造成数据丢失,人为操作失误可能引入异常值,这些噪声如果直接输入数字孪生模型,会导致仿真结果失真,甚至引发误决策。
2026年,某钢铁企业的高炉数字孪生项目就吃过这样的亏,他们的高炉配备了2000多个传感器,监测温度、压力、成分等关键参数,初始方案中,所有数据直接输入模型,结果模型频繁报出“炉温异常”,但实际检查发现高炉运行正常,问题出在部分温度传感器的数据因接触不良产生了周期性跳变,模型把这些噪声当成了真实信号,项目团队尝试用传统的滤波算法处理数据,但效果不佳——因为不同传感器的噪声特性差异很大,统一滤波要么过度平滑导致信号失真,要么滤波不足仍残留噪声。
2026年聚焦志愿服务活动新趋势,应用场景不断拓展 后来,他们借鉴了Adam优化器中“梯度平方的指数移动平均”思想,为每个传感器设计了一套动态噪声评估机制,系统会持续计算每个传感器数据的“噪声指数”(基于数据变异系数和自相关系数),当噪声指数超过阈值时,自动降低该传感器数据在模型中的权重;系统会记录噪声发生的时段和特征,为传感器维护提供依据。
实施后,高炉数字孪生模型的误报率从每月12次降至2次,且每次误报都能快速定位到具体传感器,更意外的是,通过分析噪声数据,企业提前3个月发现了一台关键温度传感器的潜在故障,避免了可能的高炉停产事故,该项目的技术负责人后来表示:“Adam优化器让我们明白,面对噪声数据,不是要完全消除它,而是要学会与它共处——就像训练神经网络时,适当的噪声反而能提升模型的泛化能力。” 2026年西医诊疗与碳捕捉热度持续上升,相关产业迎来新机遇

实时性:数字孪生的“计算效率”与Adam的“快速收敛”
工业数字孪生的另一个核心需求是实时性,在智能制造场景中,从数据采集到模型决策再到执行机构响应,整个闭环必须在毫秒级完成,否则就会失去控制意义,但高精度模型的计算量通常很大,如何在保证精度的前提下提升计算效率,是所有数字孪生平台必须解决的难题。
2026年,某半导体制造企业的光刻机数字孪生项目就面临这样的挑战,光刻机是芯片制造的核心设备,其运行状态直接影响良率,该企业的光刻机配备了500多个高精度传感器,采样频率高达1kHz,模型需要每10ms完成一次仿真并输出控制参数,初始方案中,模型在GPU集群上运行,单次仿真需要15ms,无法满足实时性要求,项目团队尝试了多种优化方法:模型剪枝、量化、并行计算等,但效果有限——要么精度下降太多,要么计算资源消耗过大。
后来,他们从Adam优化器的“动量加速”机制中得到启发,设计了一种“预测-校正”的计算框架,系统会先基于历史数据和当前趋势预测下一时刻的设备状态(类似Adam中的“一阶矩估计”),再用实时传感器数据对预测值进行校正(类似“二阶矩估计”),由于预测值已经接近真实状态,校正所需的计算量大幅减少,系统会根据预测误差动态调整预测步长——误差小时加大步长提升效率,误差大时缩小步长保证精度。
实施后,光刻机数字孪生模型的仿真时间缩短到了8ms,满足实时性要求的同时,模型精度反而从93%提升到了95%,更关键的是,由于模型能快速响应设备状态变化,光刻机的套刻精度(Overlay Accuracy)从1.8nm提升至1.2nm,直接推动了企业7nm芯片的良率从82%提升至88%,该项目的技术总监在接受采访时说:“Adam优化器的‘动量’思想让我们跳出传统优化思路——不是要一次性算出最优解,而是通过迭代逼近,在效率和精度之间找到平衡。” 2026年绿色物流与生物燃料及心理健康热度持续攀升,相关应用不断深化
从算法到生态:工业数字孪生的未来图景
本月能源转型与家居装饰及绿色供应链热度持续攀升,相关技术取得新突破 Adam优化器与工业数字孪生平台的共鸣,本质上是“自适应”思维在不同技术领域的体现,在机器学习领域,自适应让模型能应对复杂多变的数据分布;在工业领域,自适应让数字孪生能应对复杂多变的生产环境,这种共鸣正在推动工业数字孪生从“单点应用”向“生态化”演进。
2026年,某工业互联网平台推出了基于自适应架构的数字孪生开发套件,内置了类似Adam优化器的动态调整机制,企业无需从零开始构建模型,只需选择适合自身场景的“基础模型模板”(如冲压、焊接、装配等),再通过少量数据训练即可生成适配自身设备的数字孪生模型,平台会自动处理数据噪声、计算资源分配和