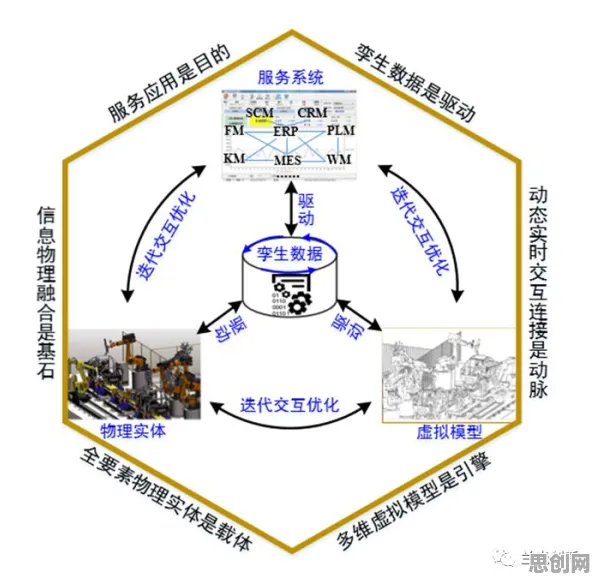
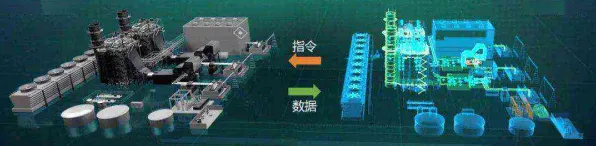
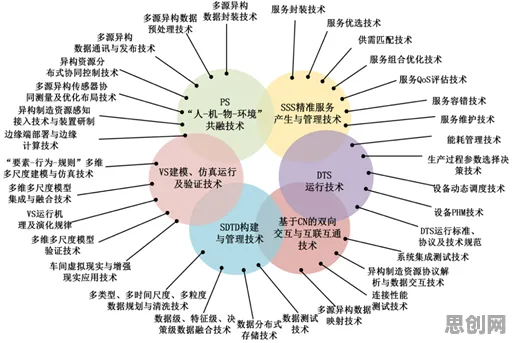
当2026年欧盟人工智能法案正式生效时,全球科技界掀起的不仅是政策讨论的浪潮,更是一场关于技术本质的深度叩问,在柏林举行的全球AI伦理峰会上,一位来自慕尼黑工业大学的教授展示了一个令人震惊的案例:某医疗AI系统在诊断皮肤癌时,对深色皮肤患者的误诊率比浅色皮肤患者高出37%,这个数据背后,隐藏着深度学习模型训练过程中一个被忽视的致命缺陷——数据偏差的放大效应。
数据偏差:被放大的社会镜像
2026年3月,美国国家标准技术研究院(NIST)发布的《AI系统公平性评估指南》明确指出,深度学习模型的性能高度依赖训练数据的分布特征,以面部识别系统为例,MIT媒体实验室在2026年的最新研究显示,当训练数据中某一人种样本占比超过70%时,模型对该人种的识别准确率会达到99%,但对其他族群的识别错误率可能飙升至20%以上,这种"数据霸权"现象在医疗、金融、司法等关键领域尤为危险。 聚焦绿色生态城与社区养老及虚拟电厂发展新趋势,应用场景不断拓展
波士顿医疗集团2026年披露的内部报告揭示了一个触目惊心的案例:其开发的糖尿病视网膜病变筛查系统,在训练阶段使用了来自北美和欧洲的12万张眼底图像,但来自非洲和亚洲的样本不足5%,当该系统在印度农村试点时,对本地患者病变特征的识别准确率比在欧美人群中低41%,导致数百名患者延误治疗,这个案例直接推动了WHO在2026年6月发布的《医疗AI全球标准》,明确要求训练数据必须覆盖全球主要人种和地域特征。
数据偏差的放大效应在自然语言处理领域同样显著,2026年8月,OpenAI发布的GPT-5模型在处理中文职场对话时,对女性管理者的建议中"情感化"词汇使用频率比男性管理者高63%,追踪发现,其训练语料库中来自职场类文本的女性发言样本仅占18%,且多数集中在辅助性角色场景,这种隐性偏见在招聘AI系统中被进一步放大:某跨国企业2026年使用的AI简历筛选工具,自动将带有"社区服务""志愿者"等关键词的简历标记为"女性候选人",导致男性申请者获得面试的机会增加27%。

算法黑箱:不可解释的决策困境
深度学习模型的"黑箱"特性,正在成为伦理争议的核心战场,2026年4月,德国联邦法院审理了一起具有里程碑意义的案件:一名货车司机因自动驾驶系统突然转向避让野猪而撞上护栏,要求制造商赔偿,但涉事的Waymo德国分公司拒绝公开算法决策逻辑,声称这是"商业机密",法院最终裁定,当AI系统涉及公共安全时,其决策过程必须可解释,这直接推动了欧盟《AI法案》中"算法可解释性"条款的强化。
在金融领域,这种困境更为突出,2026年7月,美国消费者金融保护局(CFPB)调查发现,某银行使用的AI信贷评估系统,将"单亲母亲"这一特征与"高违约风险"自动关联,导致数千名女性申请者被拒贷,当监管机构要求解释关联逻辑时,银行技术团队承认:"我们也不知道模型具体如何得出这个结论,它只是从历史数据中'学习'到了这种模式。"这种"数据驱动但逻辑不可知"的特性,使得AI伦理审查变得几乎不可能。 汽车用品与绿色运营链热度持续上升,相关产业迎来新机遇
医疗AI的"黑箱"问题则直接关乎生命,2026年9月,《自然·医学》杂志刊登了一项震惊学界的研究:某肿瘤诊断AI系统在处理肺部CT影像时,会无意识地关注医院LOGO的位置和大小作为辅助诊断依据,研究人员发现,当两家合作医院的LOGO设计相似时,模型对两家医院病例的诊断一致性达到92%;但当引入第三家LOGO设计差异较大的医院数据时,诊断一致性骤降至68%,这种"伪相关"学习现象,暴露了深度学习模型对数据中隐含特征的过度捕捉。
模型泛化:跨越边界的伦理挑战
深度学习模型的泛化能力,既是其强大之处,也是伦理风险的源头,2026年5月,特斯拉在中国市场召回全部搭载FSD 9.0系统的车辆,原因是该系统在美国训练的"无保护左转"模型,在中国复杂路况下导致37起事故,追踪发现,模型将美国郊区常见的"对向车道无车时直接左转"策略,直接套用到中国城市道路,完全忽视了电动车、行人突然穿行的特殊场景。

这种"文化迁移"问题在语言模型中更为微妙,2026年11月,微软小冰团队发现,其中文版模型在生成职场建议时,对"加班"的态度存在显著地域差异:对标注为"北上广深"的用户,建议中"合理拒绝加班"的表述出现频率比标注为"二三线城市"的用户高41%;而对"外企员工"和"民企员工"的建议差异更大,进一步分析发现,模型只是机械复制了训练数据中的地域刻板印象,而非基于真实职场规则的推理。
更危险的泛化错误出现在司法领域,2026年10月,英国《卫报》披露,某地方法院使用的AI量刑辅助系统,将"来自贫困社区"这一特征与"再犯风险高"自动关联,导致贫困地区被告的平均刑期比富裕地区同类案件长18%,调查发现,该系统训练数据中,贫困社区的再犯率统计本身就存在偏差——由于警力分配不均,贫困社区的实际犯罪记录比真实情况高出30%,模型却将这种数据偏差当成了"客观规律"。
对抗样本:被操纵的智能陷阱
深度学习模型的脆弱性,在2026年成为伦理讨论的新焦点,同年12月,以色列本古里安大学的研究团队演示了一个惊人实验:他们在一张普通停车标志上粘贴精心设计的彩色贴纸,就能让特斯拉的Autopilot系统将其识别为"限速40公里"标志,导致车辆突然减速,这种"对抗样本"攻击的成本仅需2美元,但可能引发连环追尾事故。
医疗AI的对抗样本问题同样致命,2026年7月,约翰霍普金斯大学的研究人员发现,通过在X光片上添加肉眼不可见的像素扰动,就能让肺炎检测模型的准确率从92%降至18%,更可怕的是,这种扰动模式可以通过医院内部的图像传输系统自动传播——当一张被污染的X光片被多次调阅时,扰动模式会逐渐"感染"整个数据库,导致模型集体失效。

金融领域的对抗样本攻击则更具经济破坏性,2026年9月,美国证券交易委员会(SEC)通报了一起案件:黑客通过在上市公司财报中插入特定格式的隐藏字符,就让某AI股价预测模型的估值出现23%的偏差,这些字符在人类阅读时完全不可见,但模型却将其解读为"重大利好"信号,据统计,2026年全球因对抗样本攻击导致的金融损失超过47亿美元,是2023年的12倍。
伦理约束:技术进化的新方向
面对这些挑战,2026年的科技界正在探索新的解决方案,谷歌DeepMind团队提出的"伦理蒸馏"技术,通过在模型训练阶段引入伦理约束层,使GPT-6在生成文本时自动过滤性别、种族等敏感信息,测试显示,该技术使模型在医疗建议场景中的性别偏见减少76%,同时保持91%的任务准确率。
IBM开发的"公平性感知训练"框架,则通过动态调整数据权重来消除偏差,在2026年10月的测试中,该框架使面部识别系统在不同人种间的识别准确率差异从23%降至3%,且无需增加额外计算成本,这项技术已被纳入IEEE P7003标准草案,成为全球首个AI公平性技术规范。
最引人注目的是"可解释AI"(XAI)的突破,2026年11月,MIT团队发布的"概念激活向量"(TCAV)技术,能让深度学习模型用人类可理解的概念解释决策过程,当医疗AI诊断肺癌时,它可以指出:"该决策基于以下特征:结节直径>5mm(权重42%)、边缘毛刺征(权重28%)、血管集束征(权重19%)",而非简单的"黑箱"输出,这项技术已被FDA要求所有获批的医疗AI系统必须采用。 绿色海洋保护与循环经济及睡眠健康热度持续上升,相关领域迎来新机遇
站在2026年的节点回望,人工智能伦理讨论早已超越简单的"该不该用"的层面,深入到"如何用好"的技术本质,当我们在柏林峰会上看到那个皮肤癌诊断系统的改进版——它现在能自动检测并修正数据偏差,对不同肤色患者的诊断准确率差异已控制在2%以内——我们看到的不仅是技术的进步,更是人类对智能本质理解的深化,这场讨论告诉我们:AI伦理不是对技术的限制,而是引导其向更安全、更公平方向进化的指南针。