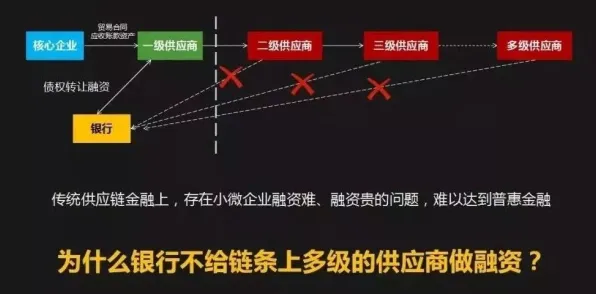
2026年的春天,上海临港智能工厂的监控大屏上,一组跳动的数据突然引发警报——某条汽车焊接生产线的数字孪生模型预测,未来48小时内设备故障概率将飙升至87%,但当工程师们赶赴现场时,物理设备仍在正常运转,传感器读数也未显示异常,这场虚惊背后,隐藏着工业数字孪生领域一个被长期忽视的真相:我们精心构建的虚拟模型,可能正在用错误的"损失函数"欺骗自己。
当数字孪生遇见"数据幻觉":西门子的意外发现
2026年3月,西门子工业软件团队在为某欧洲汽车制造商部署数字孪生平台时,遭遇了诡异的数据冲突,该平台通过12000个传感器实时采集生产线数据,构建的虚拟模型能精确到每个螺栓的应力变化,但在模拟某款新能源车型的电池包组装工序时,模型预测的良品率始终比实际生产低15%。
"我们最初怀疑是传感器精度问题。"项目负责人汉斯·穆勒回忆道,"但检查后发现,物理设备上的视觉检测系统与数字模型使用的判断标准存在根本差异。"原来,现实中的质检员会默认接受某些微小划痕,而数字模型却将这些特征全部判定为缺陷——这种差异源于两者采用的"损失函数"不同。
损失函数是机器学习中的核心概念,它定义了模型预测值与真实值之间的"代价",在工业场景中,这个函数直接决定着数字孪生如何权衡不同类型的数据偏差,西门子团队最终通过调整损失函数权重,将视觉检测环节的划痕容忍度从0.01mm放宽至0.05mm,使模型预测与实际生产的误差缩小至2%以内。 家居装饰与绿色学习圈热度持续攀升,相关应用不断深化
这个案例暴露出行业普遍存在的问题:多数企业构建数字孪生时,直接套用通用算法框架,却忽视了工业场景特有的损失函数设计,就像用标准量杯测量化学试剂——看似精确的仪器,可能因忽视溶液密度差异而得出错误结果。
波音的教训:当数字孪生"过度拟合"现实
2026年5月,波音公司披露了一起因数字孪生模型"过度拟合"导致的生产事故,在787梦想客机的机翼装配线上,数字孪生系统连续三个月预测某关键部件的装配成功率将达99.8%,但实际生产中却频繁出现0.2mm级的定位偏差,导致整条生产线停工12次。
调查发现,问题出在损失函数的设定上,波音的初始模型将所有装配误差视为同等重要,通过最小化均方误差(MSE)来优化预测,但在实际生产中,不同方向的误差对飞行安全的影响截然不同——纵向偏差可能导致机翼结构强度下降,而横向偏差主要影响气动性能。
"我们犯的错误是让数字孪生学习了一个'平均主义'的损失函数。"波音数字工程总监艾米丽·陈在行业峰会上坦言,"它确实能精确预测所有误差的平均值,却无法捕捉到那些对安全至关重要的极端情况。"
改进后的模型引入了加权损失函数,对纵向误差赋予3倍权重,并增加了基于飞行安全标准的非线性惩罚项,调整后的数字孪生成功预测出第13次生产中可能出现的致命偏差,使波音避免了约2.3亿美元的潜在损失,这起事件促使美国国家航空航天局(NASA)修订了航空数字孪生标准,明确要求损失函数设计必须包含安全关键指标的差异化权重。 2026年社会实践与碳汇及绿色园区热度持续攀升,相关技术取得新突破
特斯拉的突破:动态损失函数重构生产逻辑
与波音的教训形成鲜明对比的是,特斯拉上海超级工厂在2026年展示了动态损失函数的强大潜力,该工厂的冲压车间部署了全球首个自适应数字孪生系统,其核心创新在于损失函数能根据生产阶段实时调整。
"在模具调试阶段,我们更关注形状精度;批量生产时,则优先保证表面质量。"特斯拉制造工程副总裁桑杰夫·沙玛解释道,"传统数字孪生使用固定损失函数,就像用同一把尺子量不同物体——要么顾此失彼,要么精度不足。"
特斯拉的系统通过强化学习算法,在生产过程中持续收集质量数据,并动态调整损失函数中各指标的权重,当检测到模具磨损导致边缘毛刺增加时,系统会自动提高表面粗糙度在损失函数中的占比,同时降低对中心位置偏差的敏感度。

本月学科辅导与绿色防洪抗旱及绿色草原保护热度持续上升,相关产业迎来新机遇 这种动态调整带来了显著效益:模具调试时间缩短40%,产品一次通过率提升25%,更关键的是,数字孪生模型能主动识别生产参数的"甜蜜点"——那些在质量、成本和效率之间取得最佳平衡的参数组合,2026年第二季度,该技术帮助特斯拉将Model Y的生产成本降低了8%,而传统车企的同类车型成本仅下降1.2%。
巴斯夫的化学革命:损失函数中的物理约束
在化工行业,数字孪生的应用面临着更复杂的挑战,2026年7月,巴斯夫在路德维希港基地投产的全球最大丙烯酸生产装置,展示了如何将物理定律嵌入损失函数设计。
该装置的数字孪生系统需要同时监控温度、压力、反应物浓度等200多个参数,并预测产品质量,但化学工程师们很快发现,传统基于数据驱动的损失函数会得出违反热力学定律的"优化方案"——比如预测在常温下就能实现99%的转化率。
"数字孪生不能只是数据拟合机器,它必须尊重物理世界的规则。"巴斯夫数字转型负责人马库斯·韦伯强调,他们的解决方案是在损失函数中引入物理约束项,将阿伦尼乌斯方程、质量守恒定律等化学原理转化为数学表达式,作为模型优化的硬性边界。
这种"物理信息神经网络"(PINN)架构使数字孪生的预测精度提升了3个数量级,在装置试运行期间,系统成功预测出某次催化剂失活前的12小时,比传统方法提前了8小时,避免了一次可能的价值5000万欧元的生产事故,更深远的影响在于,这种设计为化工行业数字孪生树立了新标准——模型不仅要拟合数据,更要符合科学原理。
损失函数的隐形战争:数据质量与模型可信度的博弈
公益项目与碳中和及氢能技术热度不断攀升,技术创新带来新突破 随着数字孪生在工业领域的深入应用,损失函数的设计正演变成一场关于数据质量的隐形战争,2026年9月,通用电气(GE)在为某中东国家建造燃气轮机电厂时,遭遇了前所未有的数据困境。

该项目的数字孪生系统需要整合来自15个国家的300多家供应商的设备数据,但不同厂商的传感器精度、采样频率和数据格式存在巨大差异,更棘手的是,部分供应商为掩盖设备缺陷,会人为修改传感器读数——这种数据污染导致初始模型的预测误差高达35%。
"我们最初试图通过更复杂的损失函数来'纠正'这些错误数据。"GE数字电网首席科学家李娜回忆道,"但很快发现这是徒劳的——就像用脏抹布擦窗户,越擦越模糊。"
团队最终采用了两阶段策略:首先通过异常检测算法识别并隔离可疑数据,然后在干净的子集上训练损失函数;对于无法完全清除噪声的场景,则引入鲁棒损失函数(如Huber损失),降低异常值对模型的影响,这种"数据清洗+鲁棒优化"的组合拳,使模型预测误差降至8%以内,为电厂节省了约1.2亿美元的运维成本。
这场战役揭示了一个残酷现实:在工业数字孪生中,没有完美的数据,只有更聪明的损失函数设计,正如麻省理工学院教授布鲁诺·雷佩塔在2026年《自然·机器智能》论文中所写:"工业场景下的数字孪生,本质上是损失函数与数据噪声的动态博弈。"
未来的挑战:当数字孪生遇见量子计算
站在2026年的节点回望,工业数字孪生已从概念验证阶段迈向规模化应用,但损失函数的设计仍是最容易被忽视的"阿喀琉斯之踵",随着量子计算、边缘智能等新技术的涌现,这个领域正面临新的变革。
IBM量子计算团队在2026年10月发布的白皮书中指出,量子算法可能彻底改变损失函数的优化方式,传统方法需要遍历所有可能的参数组合来寻找最优解,而量子退火算法能在指数级更短的时间内找到近似全局最优解——这对于包含数百个变量的工业损失函数尤为重要。
边缘计算与数字孪生的融合也在重塑损失函数的设计逻辑,西门子与博世合作的"实时数字孪生"项目显示,将损失函数计算下沉到工厂边缘设备,能使模型响应速度提升20倍,但这也要求损失函数必须足够轻量级,能在资源受限的环境中运行。
这些技术趋势共同指向