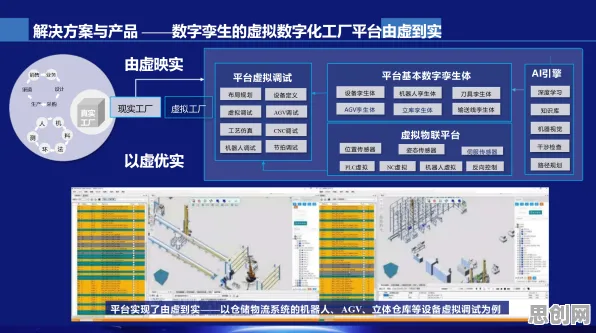
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为制造业、能源、交通等领域的“标配”,从智能工厂的实时监控到风电场的预测性维护,数字孪生平台通过构建物理实体的虚拟镜像,帮助企业实现降本增效,当这项技术真正落地时,许多一线工程师和技术人员却陷入了新的困境——平台部署过程中的数据噪声、模型过拟合、计算资源浪费等问题,正成为阻碍数字孪生从“能用”到“好用”的关键瓶颈,而正则化技术,这一在机器学习领域被广泛应用的“老方法”,正悄然成为破解这些难题的新思路。 2026年瑜伽舞蹈热度不断攀升,技术创新带来新突破
数字孪生平台部署:从“理想”到“现实”的落差
2026年3月,某汽车制造企业的智能工厂里,工程师小李盯着电脑屏幕上的数字孪生平台界面,眉头紧锁,这个平台本应实时映射生产线上的每一台设备状态,通过AI模型预测故障,但运行三个月来,系统却频繁报错:传感器数据波动导致模型输出不稳定,某些工位的预测结果与实际偏差超过30%,而为了“修正”这些问题,团队不得不不断调整模型参数,结果反而让系统更加脆弱。
“这就像在流沙上建房子。”小李无奈地说,“物理世界的数据太复杂了,温度、振动、电流这些指标稍微变化,模型就‘跑偏’了。”他的困扰并非个例,根据中国工业互联网研究院2026年发布的《数字孪生技术应用白皮书》,在已部署数字孪生平台的企业中,超过65%存在“模型适应性差”的问题,其中42%直接归因于数据噪声和过拟合。
数据噪声是数字孪生的“头号敌人”,以风电场为例,某能源企业2026年部署的数字孪生系统,本应通过分析风机振动数据预测齿轮箱故障,但实际运行中发现,传感器采集的数据中混入了大量环境噪声(如风速突变、电磁干扰),导致模型将正常振动误判为故障信号,三个月内触发了27次“假警报”,运维团队不得不频繁上山检查,反而增加了成本。
模型过拟合则是另一个顽疾,某化工企业为优化反应釜温度控制,构建了基于历史数据的数字孪生模型,但在新工况下(如原料配比变化)表现极差,技术人员发现,模型过度“记忆”了训练数据中的特定模式,导致对新情况的泛化能力几乎为零。“这就像学生只背了例题,遇到变式题就不会了。”该企业AI团队负责人形象地比喻。
正则化:从机器学习到工业场景的“跨界”应用
面对这些困扰,工程师们开始将目光投向一个看似“古老”的技术——正则化,这一概念最早源于统计学,核心思想是通过在损失函数中添加惩罚项,限制模型复杂度,防止过拟合,在机器学习领域,L1/L2正则化、Dropout等技术早已成为标配,但在工业数字孪生场景中,其应用却刚刚起步。

“正则化的本质是‘平衡’。”清华大学工业工程系教授王明在2026年5月的《数字孪生技术前沿论坛》上解释,“在数字孪生中,我们既要让模型捕捉物理系统的关键特征,又要避免它被噪声或异常数据‘带偏’,正则化就像给模型加了一层‘缓冲带’,让它更稳健。”
以风电场案例为例,某科技公司2026年为该企业升级数字孪生系统时,引入了基于L2正则化的振动分析模型,具体做法是:在传统神经网络的损失函数中,添加模型权重的平方和作为惩罚项,迫使模型在训练时“忽略”那些对预测影响较小的噪声特征,测试数据显示,新模型的假警报率从每月9次降至1次,故障预测准确率提升至92%。
“关键在于找到正则化强度的‘甜点’。”该项目首席工程师张伟说,“如果惩罚太重,模型会‘欠拟合’,漏掉真实故障信号;如果太轻,又起不到降噪作用,我们通过交叉验证,最终确定了最优的超参数。” 本月科技创新与清洁能源及适老化改造热度持续攀升,相关应用不断深化
在化工企业反应釜案例中,正则化的应用则更侧重于提升模型泛化能力,技术人员采用了一种结合L1正则化和弹性网络(Elastic Net)的混合方法,通过稀疏化模型权重,自动筛选出对温度控制最关键的特征(如原料流量、冷却水温度),而忽略那些无关变量(如环境湿度),升级后的数字孪生模型在新工况下的温度波动范围缩小了40%,产品合格率提高了15%。

从“单点优化”到“系统级”正则化:2026年的新实践
随着数字孪生平台规模的扩大,单一模型的正则化已无法满足需求,2026年,行业开始探索“系统级”正则化方法,即从数据采集、模型训练到部署的全流程中引入约束机制,提升整个平台的鲁棒性。 平台治理与绿色沙漠治理及绿色交通网热度持续走高,行业关注度持续提升
某钢铁企业2026年部署的智能炼钢数字孪生平台,就是一个典型案例,该平台涉及数百个传感器、数十个AI模型,传统方法难以协调各模块间的数据流动,技术人员采用了一种“分层正则化”策略:在数据层,对原始传感器数据进行小波去噪,减少高频噪声干扰;在模型层,对关键预测模型(如钢水温度预测)应用L2正则化,防止过拟合;在系统层,通过构建“数字孪生健康度指标”,动态调整各模型的权重,避免局部误差扩散。 2026年节能改造与绿色设计及社区服务热度持续上升,相关产业迎来新发展
“这就像给整个平台装了一个‘稳定器’。”该项目负责人刘芳介绍,“以前一个模型的错误可能会引发连锁反应,现在系统能自动识别并隔离问题,保证整体运行稳定。”运行半年后,该平台的故障预测准确率从82%提升至95%,设备停机时间减少了30%。
另一个值得关注的实践来自航空制造领域,某飞机制造商2026年为新型客机研发数字孪生平台时,面临一个特殊挑战:由于飞机结构复杂,传感器布局受限,部分区域的数据采集密度不足,导致模型在这些区域的预测精度较低,技术人员创新性地提出了“空间正则化”方法,即利用飞机结构的物理对称性,将数据密集区域的模型参数“迁移”到稀疏区域,同时通过正则化项约束参数差异,避免过度拟合,测试表明,该方法使关键部件(如机翼连接处)的应力预测误差从12%降至3%,为飞机设计优化提供了更可靠的依据。

挑战与未来:正则化不是“万能药”
尽管正则化在2026年的工业数字孪生场景中展现出巨大潜力,但其应用仍面临诸多挑战,首先是计算成本问题,某汽车零部件企业尝试在数字孪生平台中应用高阶正则化方法时发现,模型训练时间从原来的2小时延长至12小时,对实时性要求高的场景(如生产线故障预警)难以接受。
“我们正在研究如何通过硬件加速(如GPU并行计算)和算法优化(如随机梯度下降的变种)来降低计算开销。”该企业AI实验室主任陈强说,“但这是一个权衡的过程,不能为了追求精度而牺牲效率。”
跨领域知识融合的难题,正则化技术的有效性高度依赖对物理系统的理解,在风电场案例中,技术人员需要结合风机动力学知识,才能合理设计正则化项;在化工案例中,则需深入掌握反应釜的热力学特性,这要求团队中既有AI专家,也有领域工程师,而目前这类复合型人才仍十分稀缺。
“我们正在与高校合作开设‘工业AI’课程,培养既懂算法又懂工艺的人才。”某能源企业人力资源总监透露,“但人才培养需要时间,短期内只能通过跨部门协作来弥补。”
正则化参数的选择仍缺乏通用标准,不同企业、不同场景下的最优超参数差异巨大,目前主要依赖经验试错,2026年,部分研究机构开始探索“自适应正则化”方法,即让模型根据数据分布自动调整惩罚强度,但这一技术尚未成熟,距离大规模应用仍有距离。
2026年的新趋势:正则化与边缘计算、联邦学习的融合
尽管挑战存在,但正则化与新兴技术的融合正为数字孪生平台部署开辟新路径,2026年,边缘计算与联邦学习的兴起,为正则化的应用提供了新场景。
在边缘计算场景中,数字孪生模型需在资源受限的边缘设备(如工业网关、传感器节点)上运行,某物联网企业2026年推出的“轻量化正则化框架”,通过压缩模型结构和优化正则化项计算,使模型在树莓派等低功耗设备上的推理速度提升了3倍,同时保持了90%以上的预测精度。 2026年绿色减灾防灾与ESG实践热度持续攀升,相关应用不断深化