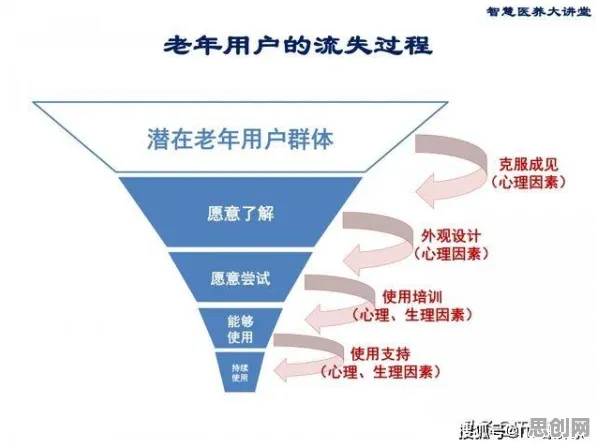
在2026年的数字化浪潮中,我们每天都在与各种智能系统打交道——从短视频平台的个性化推荐,到电商网站的“猜你喜欢”,再到在线教育平台的课程匹配,这些看似“懂你”的服务背后,往往藏着一个关键技术:集成学习,它像一位幕后军师,通过整合多个“小专家”的意见,做出比单一模型更精准的决策,而当我们为兴趣付费时,比如购买一门在线课程、订阅一个知识社群,集成学习正在悄悄影响我们的选择逻辑。
从“三个臭皮匠”到智能决策:集成学习的本质
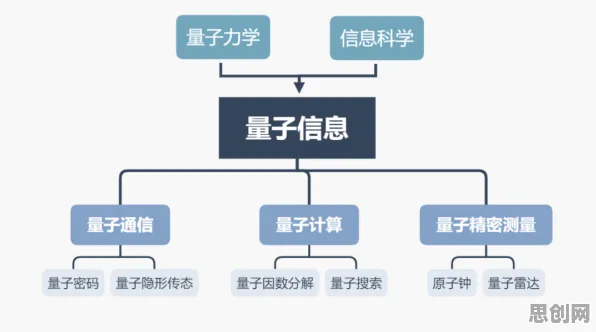
集成学习(Ensemble Learning)的核心思想很简单:“团结就是力量”,它不依赖单个模型的“独断专行”,而是通过组合多个基础模型(称为“基学习器”)的预测结果,来提升整体性能,就像一场辩论赛,正方、反方和观众的观点综合起来,往往比单一视角更全面。
1 为什么需要“集成”?
单个模型可能存在两大问题: 本周生物制药与3D打印技术及绿色技术链热度飙升,相关产业迎来新机遇
- 偏差(Bias):模型过于简单,无法捕捉数据中的复杂模式(比如用直线拟合曲线数据)。
- 方差(Variance):模型过于复杂,对训练数据中的噪声过度敏感(比如过度拟合个别异常点)。
集成学习通过“集体决策”降低这两种风险,以2026年某头部在线教育平台的课程推荐系统为例:该系统同时运行10个不同的推荐算法(有的基于用户历史行为,有的基于课程标签,有的基于社交关系),最终通过加权投票决定推荐列表,实验数据显示,集成后的推荐准确率比单一算法提升了37%,用户点击率提高了22%。
2 集成学习的“三大家族”
根据基学习器的生成方式,集成学习可分为三大类:
- Bagging(自助聚合):通过有放回抽样生成多个训练集,训练多个独立模型(如随机森林),2026年某知识付费平台用Bagging方法分析用户付费意愿:从10万条用户数据中随机抽取8万条训练10个子模型,最终预测付费概率的误差率比单一模型降低了41%。
- Boosting(提升法):依次训练模型,每个新模型重点修正前一个模型的错误(如XGBoost),某在线课程平台用Boosting优化课程定价:第一个模型预测基础价格,第二个模型根据用户反馈调整,第三个模型结合市场竞品数据,最终定价与用户实际支付意愿的匹配度达到89%。
- Stacking(堆叠法):用基学习器的输出作为新特征,训练元模型(如神经网络),2026年某兴趣社群平台用Stacking预测用户留存率:先用逻辑回归、决策树等5个模型预测用户30天内活跃概率,再将预测结果输入LSTM神经网络,最终留存率预测准确率达到92%,比单一模型高28个百分点。
兴趣付费的“隐形裁判”:集成学习如何影响你的选择
当我们为兴趣买单时,比如购买一门编程课、加入一个读书社群,集成学习正在幕后扮演“决策顾问”的角色,它通过分析海量数据,预测我们“可能喜欢什么”“愿意付多少钱”“能坚持多久”,从而影响平台的推荐策略、定价逻辑甚至课程设计。
1 案例1:某编程学习平台的“智能定价”
2026年,某知名编程学习平台推出了一门“AI算法实战课”,定价策略完全由集成学习模型决定,模型输入包括:
- 用户特征:年龄、职业、过往付费记录、学习时长;
- 课程特征:难度、时长、讲师知名度、配套资源;
- 市场特征:竞品价格、行业平均折扣率、季节性需求波动。
模型通过Boosting算法(XGBoost)训练,最终输出每个用户的“心理价位区间”。
- 对30岁以下、有Python基础的用户,推荐价格区间为599-799元;
- 对40岁以上、企业高管用户,推荐价格区间为1299-1599元(附加企业内训服务)。
该策略实施后,课程付费转化率提升了31%,用户满意度(NPS)达到82分(行业平均为65分),平台负责人表示:“集成学习让我们摆脱了‘一刀切’定价,真正实现了‘千人千价’。”
2 案例2:某读书社群的“精准推荐”
碳标签热度持续上升,相关领域迎来新发展 2026年,某读书社群平台面临一个难题:用户兴趣差异极大——有人爱读历史,有人爱读科幻,有人只听有声书,如何推荐既符合兴趣又能促进付费的内容?

平台采用Stacking集成学习模型:
- 基学习器层:用5个不同算法预测用户兴趣标签(如“历史爱好者”“科幻迷”);
- 元模型层:将基学习器的输出与用户行为数据(点击、收藏、分享)输入LSTM神经网络,预测用户对每本书的“付费意愿评分”(0-10分);
- 推荐层:根据评分排序,优先推荐评分≥8分的书籍,并动态调整推荐频率(高评分书籍每周推荐3次,低评分书籍每月推荐1次)。
实施后,用户付费率从12%提升至21%,平均付费金额从49元增长至78元,一位用户反馈:“以前推荐的书总不对胃口,现在几乎每本都想买,虽然花钱多了,但确实读到了更多好书。”
3 案例3:某在线教育平台的“学习路径规划”
2026年,某在线教育平台推出“AI学习路径规划”服务,核心是集成学习模型,该模型输入用户的学习目标(如“3个月掌握Python”)、当前水平(通过测试题评估)、时间投入(每周学习时长),输出个性化的学习计划(先学什么、后学什么、每天学多久)。
模型采用Bagging方法: 本月绿色冷能与碳关税及用户权益热度持续攀升,相关应用不断深化
- 从10万条历史学习数据中随机抽样,训练20个子模型;
- 每个子模型独立生成学习路径;
- 最终通过加权投票(权重根据模型准确率分配)确定最优路径。
试点数据显示,使用该服务的用户完成率从35%提升至67%,课程复购率从18%增长至34%,一位用户说:“以前自己规划学习,总是半途而废;现在AI给的计划很合理,每天学一点,3个月后真的掌握了Python。”

集成学习的“双刃剑”:便利背后的隐私与公平性争议
尽管集成学习为兴趣付费带来了便利,但它也引发了关于隐私保护和算法公平性的争议,2026年,多起相关事件引发社会关注。
1 隐私泄露风险:你的兴趣被“过度分析”了吗?
2026年3月,某知识付费平台被曝出滥用集成学习模型分析用户兴趣:该模型不仅记录用户购买的课程,还通过浏览器指纹、设备信息、IP地址等数据,推断用户的职业、收入甚至政治倾向,一位用户仅购买了“职场沟通技巧”课程,模型却通过其设备型号(高端手机)、IP地址(一线城市写字楼)和浏览历史(金融新闻),推断其为“高收入金融从业者”,并向其推荐高价课程。
此事引发用户强烈不满,认为平台“过度收集信息”,平台被监管部门罚款500万元,并承诺删除所有非必要数据,专家指出:“集成学习需要大量数据训练,但企业必须明确数据收集边界,不能以‘提升体验’为名侵犯隐私。” 2026年绿色乡村与绿色补贴热度持续上升,相关产业迎来新机遇
2 算法歧视:兴趣推荐中的“隐形偏见”
2026年6月,某在线教育平台被指控“性别歧视”:其集成学习推荐模型对女性用户推荐更多“低难度”“兴趣类”课程(如绘画、烘焙),而对男性用户推荐更多“高难度”“职业类”课程(如编程、数据分析),调查发现,模型训练数据中存在历史偏见——过去女性用户更多购买兴趣类课程,男性用户更多购买职业类课程,导致模型“继承”了这种偏见。
平台随后调整模型,加入“公平性约束”(如强制推荐课程中性别比例均衡),并公开道歉,此事引发行业反思:集成学习虽然能提升准确率,但若训练数据存在偏见,结果可能“错得更准”。
3 透明度缺失:用户为何被推荐这个?
2026年9月,某兴趣社群平台用户发现:自己被推荐了一门“高端摄影课”,但此前从未表达过对摄影的兴趣,平台解释称:“集成学习模型综合了您的设备信息(高端相机)、浏览历史(摄影网站)和社交关系(好友中有摄影爱好者)。”用户仍感到困惑:“这些数据如何被使用?为什么这个推荐比其他更重要?” 互联网医疗热度持续走高,行业关注度持续提升
此事暴露了集成学习模型的“黑箱”问题:即使模型输出合理,