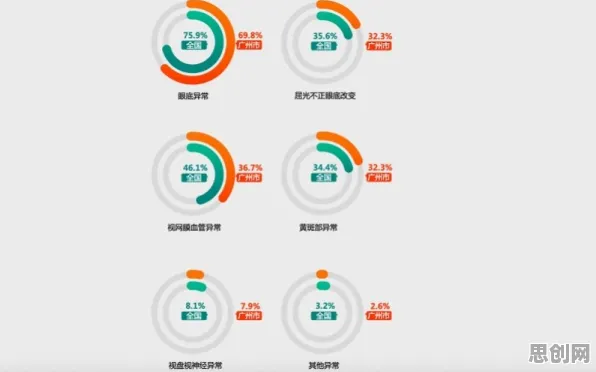
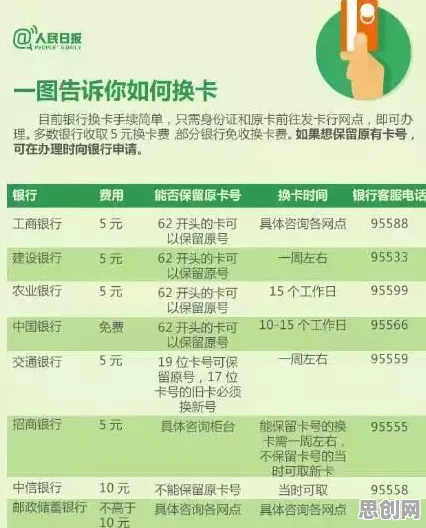
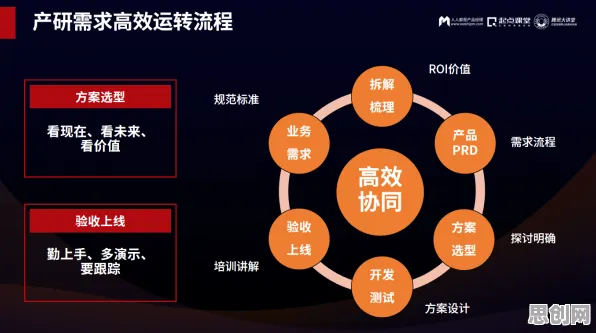
数字时代的“超级大脑”如何运转
2026年的北京,某头部互联网公司的数据中心里,一排排黑色机柜发出低沉的嗡鸣,每秒处理着超过5000万次用户请求,这些机柜背后,是支撑中国互联网经济运转的“超级大脑”——由数百万台服务器组成的云计算架构,但很少有人知道,这个看似庞大的系统,其性能极限正被一颗颗指甲盖大小的芯片牢牢卡住。
云计算架构的本质,是“用软件定义硬件”,以阿里云2026年最新发布的“磐石”架构为例,其核心由三部分组成:前端通过负载均衡器将用户请求分配到不同服务器;中间层通过虚拟化技术将物理服务器切割成数千个虚拟实例;后端则依赖分布式存储系统将数据分散在多个节点上,这种设计让系统能像“乐高积木”一样灵活扩展——当双十一购物节来临,系统能在10分钟内将计算资源扩容300%;当某台服务器故障,数据会自动迁移到其他节点,实现“无缝切换”。
但这种灵活性的代价,是对芯片性能的极致压榨,以腾讯云2026年升级的“星云”架构为例,其单集群包含10万台服务器,每台服务器搭载2颗CPU、8块GPU和4块DPU(数据处理单元),这些芯片需要同时处理:
- 计算层:CPU负责逻辑运算,GPU加速AI推理,DPU卸载网络、存储等IO任务;
- 存储层:NVMe SSD通过PCIe 5.0接口与CPU通信,延迟控制在10微秒以内;
- 网络层:自研的“银杉”智能网卡支持200Gbps带宽,能动态调整数据流优先级。
“这就像让一辆F1赛车在拥堵的城市道路行驶。”华为云架构师李明比喻道,“芯片性能再强,如果数据传输、任务调度等环节跟不上,整体效率也会大打折扣。”2026年,某头部云厂商曾做过测试:将同一套AI模型分别部署在国产芯片和进口芯片上,前者因内存带宽不足,推理速度慢了40%;后者则因支持更先进的指令集,能将计算任务拆解得更细,资源利用率高出25%。
芯片卡脖子:从“能用”到“好用”的鸿沟
2026年3月,美国商务部更新《出口管理条例》,将14nm以下制程的DPU、支持HBM3内存的AI芯片列入“实体清单”,这一政策直接冲击中国云计算产业——据IDC数据,2026年中国公有云市场规模达8000亿元,其中70%的算力依赖进口芯片。
“卡脖子”的痛点,藏在云计算架构的“毛细血管”里,以存储为例,阿里云“磐石”架构采用的自研“盘古”存储系统,需要芯片支持RDMA(远程直接内存访问)技术,才能将数据传输延迟从毫秒级降至微秒级,但国产芯片厂商直到2026年才突破这一技术,且性能仅为进口产品的60%,更棘手的是生态问题:进口芯片有成熟的软件栈(如CUDA、ROCm),开发者能快速调用硬件资源;国产芯片则需从头搭建生态,导致应用适配周期长、成本高。 本月绿色冷能与碳普惠热度持续攀升,相关应用不断深化
2026年无人机应用与艺术教育及森林保护热度持续上升,相关领域迎来新发展 一个典型案例是字节跳动的AI训练集群,2026年,其TikTok算法团队尝试用国产GPU训练推荐模型,结果发现:
- 硬件层面:国产GPU的显存带宽比进口产品低30%,导致训练过程中频繁出现“显存不足”错误;
- 软件层面:缺乏对混合精度训练(FP16/FP8)的优化,单次迭代时间比进口方案长2小时;
- 生态层面:主流深度学习框架(如PyTorch、TensorFlow)对国产芯片的支持不完善,需要额外开发适配层。
团队不得不将部分训练任务迁回进口芯片集群,导致整体成本增加15%。“这不是简单的‘能用’问题,而是‘好用’的差距。”字节跳动基础设施负责人王伟说,“云计算是规模经济,1%的性能损失放大到百万级服务器上,就是巨大的成本浪费。”
架构创新:绕过芯片限制的“曲线救国”
面对芯片卡脖子,中国云计算厂商开始从架构层面寻找突破口,2026年,百度智能云推出的“飞桨”架构,通过“软硬协同优化”将国产芯片的性能榨干到极致,其核心策略包括:

- 任务拆分:将AI训练任务拆解为多个子任务,分配到不同芯片上并行处理,弥补单芯片性能不足;
- 内存优化:开发“显存压缩”技术,将模型参数从FP32压缩到FP8,减少对显存带宽的依赖;
- 网络加速:自研“鸿鹄”RDMA协议,将数据传输效率提升40%,部分抵消芯片间通信延迟。
测试数据显示,在国产芯片上部署“飞桨”架构后,ResNet-50图像分类模型的训练速度从12小时缩短至9小时,接近进口芯片水平,但这种优化需要付出额外代价:百度需要为每个模型开发定制化优化方案,开发周期延长30%;且优化效果高度依赖具体场景,通用性较差。
另一种思路是“异构计算”——用不同类型芯片协同工作,弥补单一芯片的短板,2026年,腾讯云“星云”架构升级后,单台服务器同时搭载CPU、GPU和DPU:
- CPU负责控制流和通用计算;
- GPU加速AI推理和图形渲染;
- DPU卸载网络、存储等IO任务,释放CPU资源。
这种设计让系统能根据任务类型动态分配资源,在处理视频转码任务时,DPU先解析视频流,GPU负责编码,CPU仅需处理元数据,整体效率提升50%,但异构计算也带来新挑战:不同芯片间的数据传输需要高效总线支持,而国产总线技术(如CXL)尚未成熟,导致跨芯片通信延迟较高。
人才缺口:架起架构与芯片的“桥梁”
芯片卡脖子的深层原因,是人才结构的失衡,2026年,中国云计算产业对“架构+芯片”复合型人才的需求激增,但供给严重不足,据教育部数据,全国仅有12所高校开设“云计算架构与芯片设计”交叉学科,每年毕业生不足2000人,而市场需求超过5万人。
“我们招一个既懂云计算架构又懂芯片设计的工程师,比招一个博士还难。”华为云人力资源总监张琳说,“很多候选人要么精通软件架构,但对芯片制程、指令集一知半解;要么熟悉芯片设计,却不懂分布式系统、虚拟化技术。”

这种人才缺口直接导致技术落地困难,2026年,某云厂商尝试将自研AI芯片集成到云计算架构中,结果发现:
- 芯片团队不了解云计算的实时性要求,将推理延迟设计得过高;
- 架构团队不熟悉芯片的功耗特性,导致服务器散热设计不足,频繁宕机;
- 双方沟通依赖翻译文档,问题定位周期长达数周。
该项目因技术风险过高被叫停。“这不是技术不行,而是人才结构跟不上。”该项目负责人反思,“我们需要的是既能‘造芯片’又能‘用芯片’的‘桥梁型人才’。” 2026年绿色包装与绿色城市及低碳出行热度持续上升,相关领域迎来新发展
从“追赶”到“超越”的路径
面对芯片卡脖子,中国云计算产业正在探索三条路径:
- 架构创新:通过软硬协同优化、异构计算等技术,最大化利用现有芯片性能,阿里云2026年发布的“磐石2.0”架构,通过动态资源调度将国产芯片的利用率从60%提升至85%;
- 生态建设:推动国产芯片与主流软件栈(如Kubernetes、Spark)的适配,降低开发门槛,2026年,腾讯云联合多家芯片厂商成立“开源芯片生态联盟”,已适配10款国产芯片;
- 人才培养:高校与企业合作开设“云计算+芯片”双学位项目,企业内推“架构师轮岗芯片设计”计划,百度与清华合作开设“智能计算”实验室,每年培养200名复合型人才。
2026年的中国云计算产业,正站在“架构驱动芯片”还是“芯片定义架构”的十字路口,前者能通过软件优化绕过硬件限制,但长期看可能陷入“补丁式创新”;后者需要突破芯片制程、指令集等核心技术,但一旦成功将实现质的飞跃。
本月燃料电池热度持续上升,相关领域迎来新机遇 “这不是简单的技术竞赛,而是生态、人才、产业链的综合较量。”中国工程院院士邬贺铨说,“只有搞懂云计算架构的每一个细节,才能真正理解芯片卡脖子的痛点在哪里,以及如何突破它。”
在北京的数据中心里, 2026年聚焦绿色湿地保护与碳汇交易及绿色森林保护新趋势,应用场景不断拓展