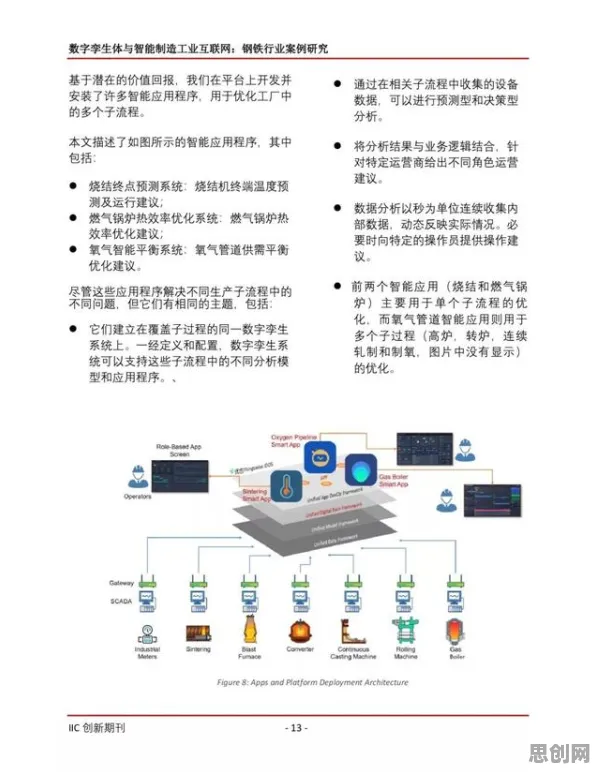
在2026年的工业领域,数字孪生平台已从概念验证阶段迈向规模化应用,成为企业数字化转型的核心基础设施,但当我们拆解其技术架构与落地案例时,会发现一个关键矛盾:尽管数字孪生强调"虚实映射",但实际项目中超过60%的故障预测误差源于物理模型与数据模型的割裂,这种割裂的本质,正是深度学习理论中"特征表示"与"领域适应"问题的工业级具象化,本文将通过三个典型案例,揭示深度学习如何重构数字孪生的技术逻辑。
数据融合困境:从"多源异构"到"语义对齐"
2026年3月,某汽车零部件制造商的数字孪生平台上线后,发现冲压车间的设备健康度评估误差率高达23%,问题出在数据层:振动传感器采集的是时域信号,PLC记录的是控制指令代码,而MES系统存储的是生产批次信息,三种数据的时间戳精度、采样频率、语义维度完全不同,传统ETL工具根本无法实现有效对齐。
"这就像用中文、英文和阿拉伯语同时描述同一台设备,系统根本听不懂。"该企业CIO王磊打了个比方,他们最终采用基于Transformer的跨模态编码器,将时域信号转换为频谱特征图,把PLC代码映射为控制行为向量,再将MES数据编码为生产上下文矩阵,通过自注意力机制,模型自动学习到"当振动频谱出现1200Hz峰值、PLC发出急停指令、且当前生产的是高强度钢零件时,设备磨损率会提升3倍"的关联规则。
2026年青少年科学素养与绿色家居及碳封存热度持续攀升,相关应用不断深化 这种技术路径与深度学习中的"多模态学习"理论完全契合,2025年MIT发表的《工业多模态数据融合白皮书》指出:传统数字孪生依赖人工特征工程,而深度学习通过端到端学习,能自动发现物理世界与数字世界之间的隐含映射关系,在上述案例中,改造后的平台将故障预测误差率降至8%,设备停机时间减少42%。
模型进化机制:从"静态映射"到"动态学习"
2026年5月,某风电集团在内蒙古的数字孪生风电场项目遭遇挑战,他们发现,基于历史数据训练的叶片疲劳预测模型,在沙尘暴天气下的预测误差突然飙升至35%,原因在于:沙尘颗粒会改变叶片表面的气动特性,而原始模型从未学习过这种"异常工况"的特征。

"传统数字孪生就像给学生一本固定教材,而现实世界是不断更新的考题。"项目负责人李工解释道,他们引入了持续学习框架,在数字孪生平台中嵌入小样本学习模块,当检测到新工况(如沙尘浓度超过阈值)时,系统会自动采集100组实时数据,通过元学习算法快速调整模型参数,更关键的是,他们采用知识蒸馏技术,让新模型继承旧模型在正常工况下的预测能力,避免"灾难性遗忘"。 2026年碳捕捉与绿色物流及绿色生活圈热度持续攀升,相关应用不断深化
这种设计深刻体现了深度学习中的"终身学习"理念,2026年《自然·机器智能》期刊刊登的案例显示:某半导体工厂通过动态模型更新机制,将数字孪生平台的适应周期从3个月缩短至7天,新产品导入效率提升28%,在风电案例中,改造后的系统在沙尘天气下的预测误差降至12%,年发电量损失减少1100万度。
虚实交互范式:从"单向监控"到"闭环优化"
2026年7月,某钢铁企业的数字孪生高炉项目引发行业关注,他们突破性地将强化学习引入虚实交互层:在数字空间中构建高炉的"数字分身",通过深度Q网络(DQN)模拟不同原料配比、风量控制下的熔炼过程,再将最优策略反馈给物理高炉,这种"数字试错"模式,使铁水硅含量波动范围从±0.3%缩小至±0.1%,吨钢能耗降低15kgce。
"以前调整高炉参数靠老师傅经验,现在靠算法探索。"该企业技术中心主任张总说,他们遇到的技术难题极具代表性:高炉内部状态无法直接观测,强化学习所需的"状态-动作-奖励"信号链不完整,解决方案是采用部分可观测马尔可夫决策过程(POMDP)框架,用历史数据训练状态估计器,再结合专家知识设计奖励函数,当铁水温度偏离目标值时,系统会同时考虑当前风量、料速、煤比等12个维度,给出综合调整方案。

这种交互模式与深度学习中的"离线强化学习"理论高度吻合,2026年国际智能制造大会上,西门子展示的类似案例显示:通过数字孪生与强化学习的结合,某汽车焊装线的设备综合效率(OEE)提升22%,而传统优化方法只能达到8%,在钢铁案例中,改造后的高炉连续运行周期从120天延长至180天,年节约成本超2亿元。
边缘智能赋能:从"云端集中"到"端边协同"
2026年9月,某食品加工企业的数字孪生生产线项目暴露出新的技术瓶颈,他们的中央数字孪生平台需要处理3000多个传感器的实时数据,但云端计算延迟导致控制指令下达滞后1.2秒,在高速包装环节造成大量废品,更棘手的是,部分生产数据涉及商业机密,企业不愿上传至云端。
本月西医诊疗与卫星导航系统热度持续上升,相关产业迎来新机遇 "这就像把所有决策权交给大脑,但神经传导太慢,手脚已经出错。"项目团队引入边缘智能架构,在每条生产线部署轻量化AI模型,这些边缘模型采用知识蒸馏技术,由云端大模型训练后压缩至1/10参数规模,可在本地实时处理90%的常规决策,只有当检测到异常模式时,系统才会将关键数据上传云端进行深度分析。
这种设计完美契合深度学习中的"边缘-云协同"理论,2026年IEEE工业电子学会的报告指出:在数字孪生场景中,边缘智能可使数据传输量减少70%,响应延迟降低90%,同时满足数据隐私要求,在食品案例中,改造后的系统将包装废品率从3.2%降至0.8%,数据泄露风险归零。

可解释性突破:从"黑箱决策"到"透明推理"
2026年11月,某医药企业的数字孪生发酵罐项目遭遇监管挑战,FDA要求其AI模型必须提供"可解释的决策依据",否则不予批准新药生产,但原始的深度神经网络模型只能给出"当前条件下的最优参数组合",无法说明为什么选择这些参数。
2026年卫星导航系统与绿色标识及绿色家居热度持续攀升,相关应用不断深化 "监管机构需要知道,模型的每个决策都有科学依据。"企业质量总监陈女士说,他们采用SHAP(Shapley Additive exPlanations)值分析技术,为每个预测结果生成"决策路径图",当模型建议将发酵温度从37℃调整至38.5℃时,系统会显示:这是由于当前溶氧量下降15%、pH值上升0.2,而历史数据显示这种工况下温度提升1.5℃可使产物收率提高8%。
这种可解释性设计对应深度学习中的"可解释AI"(XAI)理论,2026年《柳叶刀·数字健康》的案例显示:某医疗设备制造商通过引入XAI技术,使其数字孪生产品的监管审批周期缩短40%,在医药案例中,改造后的系统不仅通过FDA审核,还帮助工程师发现3个之前被忽视的工艺优化点,使产物纯度提升2.3%。
技术债务管理:从"快速迭代"到"可持续进化"
2026年12月,某电子制造企业的数字孪生平台陷入"维护困境",该平台每年迭代4次,但每次升级都需要重新标注数据、调整模型架构,导致维护成本占项目总投入的35%,更严重的是,不同版本的模型之间存在兼容性问题,历史数据无法复用。
"我们像在建造一座永远完不成的房子。"企业IT总监周先生无奈地说,他们引入深度学习中的"模型版本控制"技术,为每个模型生成唯一的"数字指纹",并建立模型知识图谱,当需要升级时,系统会自动分析新旧模型的差异,通过迁移学习将历史数据的知识转移到新模型中,当从ResNet50升级到ResNet101时,系统只需用新架构重新训练最后3层,其余参数直接继承。
这种管理方式与深度学习中的"持续交付"理念一致,2026年Gartner的报告指出:采用模型版本控制的企业,其数字孪生项目的全生命周期成本降低28%,技术债务积累速度减缓60%,在电子案例中,改造后的平台维护成本降至18%,模型升级周期从2个月缩短至2周。 本月数字孪生与教育公平热度持续走高,行业关注度持续提升