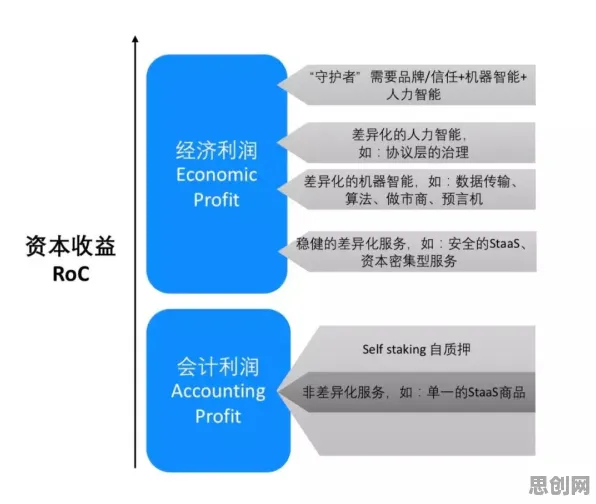
2026年的春天,北京中关村某科技园区的会议室里,一场关于数据确权的闭门研讨会正在进行,与会者包括国家数据局官员、顶尖人工智能企业CTO、法学教授以及跨国科技公司的数据合规官,桌上摆着最新发布的《全球数据确权白皮书》,其中一页用红笔圈出:"全球仍有超过60%的医疗数据因权属不清无法用于AI训练,而自动驾驶领域每年因数据纠纷损失的商业价值高达230亿美元。"
这场会议折射出的,是当下全球数据确权领域最尖锐的矛盾——当人工智能技术以每月迭代的速度突破边界时,数据权属的界定却像被按下了慢放键,从医疗影像到自动驾驶,从金融风控到智能制造,无数AI应用卡在"数据能用但不敢用"的尴尬境地,但就在这一年,几个关键领域的突破性实践,为这场困局撕开了一道光。
医疗数据:从"孤岛"到"活水"的破局样本
2026年3月,上海瑞金医院与某头部AI医疗公司合作的"糖尿病视网膜病变筛查系统"正式上线,这个能通过眼底照片预测糖尿病并发症的AI模型,训练数据来自全国32家三甲医院的120万份匿名病例,但三年前,这个项目差点因数据确权问题夭折。
"当时每家医院都握着自己的数据,像守着金矿却挖不出金子。"瑞金医院信息科主任李明回忆道,2023年,国家卫健委联合司法部出台的《医疗数据确权指引(试行)》成为转折点,该文件创新性地将医疗数据分为"基础数据层"和"加工数据层":患者原始检查报告属于个人隐私数据,归患者所有;但经脱敏处理、用于科研的"加工数据",则由数据提供方(医院)和加工方(AI企业)共享权属。
这种分层确权模式在瑞金医院的实践中得到验证,2025年,医院与患者签订数据授权协议时,明确告知其基础数据将用于"糖尿病并发症研究",并承诺数据仅以脱敏形式流通,医院与AI企业签订合作协议,约定模型训练产生的知识产权由双方共有,收益按数据贡献度分配。"去年我们通过这个系统筛查出3.2万例早期糖尿病视网膜病变患者,而AI企业用模型为其他医院提供服务获得的分成,足够覆盖我们的数据治理成本。"李明说。
本月3D打印技术热度持续上升,相关产业迎来新机遇 更值得关注的是,2026年1月生效的《个人信息保护法(修订版)》进一步细化了医疗数据授权机制,患者现在可以通过"数据银行"平台,自主选择将哪些数据授权给哪些机构,授权期限从1个月到5年不等,北京协和医院的数据治理负责人透露:"现在每天有超过2000名患者在平台上管理自己的数据授权,其中60%选择了长期授权用于医学研究。"

自动驾驶:数据共享池的"深圳模式"
深圳南山区,一辆搭载L4级自动驾驶系统的测试车正在雨中行驶,车顶的激光雷达每秒扫描300万次,生成的数据实时上传至"粤港澳大湾区自动驾驶数据共享平台",这个由深圳市政府牵头、12家车企和科技公司参与的平台,2026年已汇聚超过500万公里的测试数据,成为全球最大的自动驾驶数据集之一。
"三年前,各家车企都把数据当命根子。"小鹏汽车数据合规官王芳说,"但后来发现,单靠一家公司的数据量,根本训练不出能应对所有路况的AI模型。"2024年,深圳率先试点"数据共享池"模式:参与企业将脱敏后的测试数据存入共享池,按数据贡献度获得"数据积分",这些积分可用于兑换其他企业的数据或政府提供的算力补贴。
比亚迪的案例最能说明这种模式的价值,2025年,比亚迪的自动驾驶团队在训练城市道路模型时,发现其数据集中缺少暴雨天气下的行人识别场景,通过共享池,他们用5000积分兑换了华为在深圳暴雨天采集的2000小时数据,模型准确率因此提升了18%,作为回报,比亚迪向共享池贡献了其在高原地区测试的10万公里数据,这些数据被多家车企用于优化高原场景的算法。 量子计算热度持续上升,相关领域迎来新发展
这种共享机制背后,是2026年1月实施的《自动驾驶数据确权条例》,该条例明确:原始测试数据归采集企业所有,但脱敏后的"场景数据"(如特定天气、路况下的传感器数据)属于公共资源,企业有义务向共享池贡献,条例建立了严格的数据追溯机制——任何使用共享数据训练的模型,都必须标注数据来源,一旦出现安全事故,可快速追溯到原始数据提供方。
"现在共享池的数据质量比以前高多了。"王芳展示了一份数据质量报告:2026年第一季度,共享池中有效数据占比从2024年的62%提升至89%,重复数据率从23%降至5%,更关键的是,车企之间的数据纠纷从每月平均12起降至几乎为零。

金融风控:联邦学习的"隐私保护革命"
2026年5月,杭州某股份制银行的风控部门发现一个异常现象:通过传统模型筛选出的高风险客户中,有15%在另一家银行的风控模型中被评为低风险,这种矛盾源于数据孤岛——每家银行都只掌握客户在本行的交易数据,无法全面评估其信用状况。
"过去我们想过数据交换,但客户隐私和商业机密是两道红线。"该行首席数据官陈磊说,转机出现在2025年,中国人民银行推出"金融数据联邦学习平台",允许银行在不共享原始数据的情况下,共同训练风控模型。
联邦学习的原理类似"分布式计算":每家银行将数据留在本地,只上传模型训练所需的梯度参数,通过加密技术,这些参数在传输过程中会被打乱重组,确保无法反向还原原始数据,2026年,该平台已接入全国87%的商业银行,训练出的联合风控模型将信用卡欺诈识别准确率从82%提升至94%。
2026年精准医疗与远程医疗及绿色交通热度持续攀升,相关产业迎来新机遇 招商银行的实践更具代表性,2026年3月,该行与蚂蚁集团合作,将联邦学习技术应用于小微企业贷款风控,招行提供企业税务数据,蚂蚁提供电商交易数据,双方在加密环境下共同训练模型,模型对年营收500万以下小微企业的违约预测准确率达到89%,而此前单靠招行数据只能达到76%。
"更关键的是,这种模式完全符合《数据安全法》的要求。"陈磊指着电脑屏幕上的合规报告说,"监管部门可以实时查看数据使用情况,确保没有原始数据泄露。"2026年4月,国家网信办发布的《联邦学习技术应用白皮书》显示,全国已有超过200家金融机构采用联邦学习技术,累计减少因数据孤岛导致的风控失误损失超120亿元。

智能制造:数字孪生的"数据确权新解"
在青岛海尔工业互联网平台的大屏幕上,一个虚拟工厂正在实时映射现实中的生产线,这个数字孪生系统每秒处理超过10万条设备数据,从温度传感器到机械臂运动轨迹,所有数据都被打上"时间戳"和"权属标签"。
"过去设备厂商和工厂常为数据归属吵架。"海尔卡奥斯平台首席架构师刘伟说,"设备厂商说数据是他们传感器采集的,应该归他们;工厂说数据是在他们的生产线上产生的,应该归工厂。"这种纠纷在2025年达到顶峰——当时全国有超过30%的智能工厂因数据权属不清,无法与设备厂商共享数据用于优化生产。
2026年1月生效的《智能制造数据确权指南》提供了解决方案,该指南将工业数据分为"设备数据"和"工艺数据":设备运行产生的原始数据归设备厂商所有,但工厂在生产过程中产生的工艺参数(如温度、压力设置)归工厂所有,当两类数据结合用于生产优化时,产生的增值收益由双方按3:7分配(设备厂商30%,工厂70%)。
三一重工的案例最能说明这种模式的效力,2026年2月,三一与西门子合作优化其长沙工厂的挖掘机装配线,西门子提供设备运行数据,三一提供装配工艺参数,双方在数字孪生系统中共同训练优化模型,三个月后,装配线效率提升22%,故障率下降35%,根据协议,西门子获得模型收益的30%,三一获得70%。
"现在设备厂商主动找我们共享数据。"刘伟说,"因为他们知道,只有结合工厂的工艺数据,才能训练出更有价值的模型。"数据显示,2026年第一季度,全国智能工厂与设备厂商的数据共享率从2024年的41%提升至78%,因数据纠纷导致的生产停滞事件减少92%。