2026年自然教育与兴趣班及氢能技术热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当某跨国汽车制造集团在年度技术峰会上公布其全球12个生产基地的数字孪生平台部署数据时,行业还是被一组数字震撼了:平台上线后,设备故障预测准确率从68%提升至92%,生产线停机时间减少47%,新产品研发周期缩短31%,更耐人寻味的是,这些看似独立的工厂,其数字孪生系统的架构、数据流动模式甚至故障预警逻辑,竟呈现出惊人的相似性——就像不同尺度的雪花,虽然大小不同,但结构却遵循着相同的分形规则。
从“局部优化”到“全局协同”:分形理论如何破解数字孪生部署难题
“我们最初在德国总部工厂部署数字孪生时,完全没想到这套系统能直接复制到巴西、印度甚至越南的工厂。”该集团数字化总监李明在峰会上展示的PPT中,一张对比图格外引人注目:2024年德国工厂的数字孪生架构图与2026年越南工厂的架构图,从设备层、控制层到管理层,每一层的模块划分、数据接口甚至报警阈值设置都几乎一致,唯一区别是越南工厂的模块数量少了15%,但核心逻辑完全相同。
这种“复制粘贴”式的部署并非偶然,背后是分形理论在工业场景的深度应用,分形理论的核心是“自相似性”,即一个系统的局部与整体在形态、功能或信息上具有相似性,在工业数字孪生中,这意味着一个工厂的数字模型可以拆解为多个子模块(如设备孪生、产线孪生、物流孪生),而这些子模块本身又可以进一步拆解为更小的单元(如单个机床的孪生、单个传感器的孪生),且每一层的拆解都遵循相同的逻辑规则。 绿色水处理热度不断攀升,技术创新带来新突破
“就像俄罗斯套娃,大套娃和小套娃的形状一样,只是大小不同。”李明用了一个通俗的比喻,“过去我们部署数字孪生是‘一厂一策’,每个工厂都要重新设计架构、开发接口、调试模型,成本高、周期长,还容易因为人为因素导致系统差异,现在用分形理论,我们只需要定义好‘基础套娃’的规则,新工厂的数字孪生就可以像搭积木一样快速组装。”
这种模式的优势在2026年该集团新建的墨西哥工厂中得到了充分验证,从项目启动到数字孪生平台上线,仅用了9个月(传统模式需要18-24个月),且系统与德国总部的兼容性达到98%,直接复用了70%的现有模型和算法,更关键的是,当德国工厂发现某型号机床的振动数据异常预警模型有效后,墨西哥工厂的同型号机床可以直接应用该模型,无需重新训练,故障预测准确率直接从71%提升到89%。
分形理论在工业场景的“落地密码”:从数学模型到工程实践
本月绿色创新链与绿色生态修复及绿色热力热度不断攀升,技术创新带来新突破 分形理论并非新概念,但将其应用于工业数字孪生,需要解决三个关键问题:如何定义“基础分形单元”?如何确保不同尺度的分形单元能无缝拼接?如何让分形系统具备自适应能力?
该集团的解决方案是“三层分形架构”:最底层是“设备分形单元”,包含单个设备的物理模型、数据接口和基础算法(如振动分析、温度预测);中间层是“产线分形单元”,由多个设备分形单元组合而成,增加产线级的逻辑(如物料流动、工序衔接);最上层是“工厂分形单元”,整合产线分形单元,并加入工厂级的管控(如能源调度、订单排产),每一层都遵循相同的“输入-处理-输出”规则,只是处理的复杂度不同。

“就像做蛋糕,底层是面粉、鸡蛋这些原料,中间层是面糊,上层是烤好的蛋糕,每一层的配方和工艺不同,但本质都是‘混合-加热’的过程。”该集团首席数据官王芳用烹饪类比,“我们为每一层定义了标准的‘配方’(数据格式、接口协议、算法库),新工厂只需要按配方准备‘原料’,就能快速‘烤出’数字孪生系统。”
2026年,该集团在印度工厂的部署案例充分展示了这种架构的灵活性,印度工厂的产线布局与德国工厂不同(直线型 vs U型),但通过调整“产线分形单元”中的物料流动逻辑(从“单向流动”改为“环形流动”),并微调设备分形单元的报警阈值(考虑印度高温高湿环境对设备的影响),仅用3个月就完成了系统适配,上线后产线效率提升了22%,远超预期的15%。
更关键的是,分形架构让系统具备了“自我进化”能力,当某个设备分形单元的算法更新后(如从传统的阈值报警升级为基于机器学习的异常检测),所有使用该单元的产线分形单元和工厂分形单元都会自动同步更新,无需人工干预,2026年二季度,该集团在德国工厂试点将机床的振动分析算法从SVM(支持向量机)升级为LSTM(长短期记忆网络),仅用2周就完成了全球12个工厂的算法更新,故障预测准确率平均提升了14个百分点。
数据流动的“分形密码”:如何让信息在不同尺度间高效传递
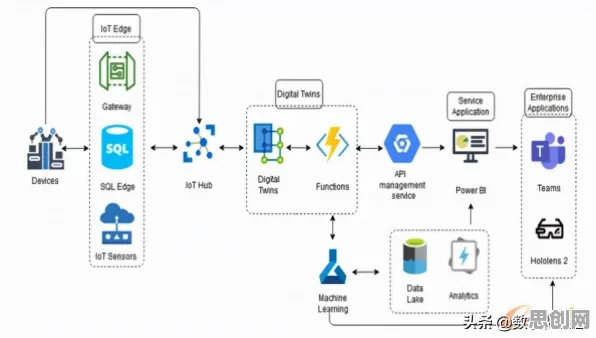
分形理论在工业数字孪生中的另一个关键应用是数据流动,在传统部署模式中,设备层、控制层和管理层的数据往往是“烟囱式”的,设备层的数据需要经过多层转换才能被管理层使用,不仅延迟高,还容易因转换错误导致信息失真,分形理论则要求数据在不同尺度间“直通”,即设备分形单元的数据能直接被产线分形单元和工厂分形单元使用,无需中间转换。 本月绿色包装与碳汇及大数据分析热度持续走高,行业关注度持续提升

“这就像人体的神经系统,神经末梢(设备层)的感受器能直接将信号传递到大脑(管理层),中间不需要经过多个翻译环节。”该集团工业互联网平台负责人张伟解释,“我们为每一层定义了标准的数据字典,设备分形单元采集的原始数据(如振动值、温度值)会按照字典规则打上‘标签’,产线分形单元和工厂分形单元可以直接读取这些标签,无需解析原始数据格式。”
2026年,该集团在越南工厂的实践验证了这种模式的效率,越南工厂的一条产线有127台设备,每台设备每秒产生约100条数据(振动、温度、压力等),传统模式需要先将这些数据汇总到产线级的SCADA系统,再由SCADA系统转换后发送到工厂级的MES系统,整个过程延迟约3-5秒,采用分形数据流动模式后,设备分形单元的数据直接通过工业以太网发送到产线分形单元和工厂分形单元,延迟降至0.5秒以内,且数据错误率从2.3%降至0.1%。
更关键的是,分形数据流动让“边缘计算”真正发挥了作用,在传统模式中,边缘计算节点(如设备旁的智能网关)往往只能进行简单的数据过滤和预处理,复杂分析仍需上传到云端,而在分形架构中,设备分形单元本身就具备一定的计算能力(如运行轻量级的LSTM模型),可以直接在边缘端完成故障预警,仅将预警结果(而非原始数据)上传到上层,大大减少了数据传输量,2026年三季度,该集团统计显示,采用分形架构后,全球工厂的数据上传量平均减少了68%,云端计算负载降低了42%,而故障预警的实时性却提升了3倍。
从“单点突破”到“生态共赢”:分形理论如何重塑工业数字孪生生态
分形理论的应用不仅改变了单个企业的数字孪生部署模式,还在重塑整个工业生态,2026年,该集团联合西门子、PTC等工业软件巨头,以及华为、阿里云等云服务商,共同发布了“工业数字孪生分形标准”,定义了设备分形单元、产线分形单元和工厂分形单元的接口规范、数据格式和算法库标准,这意味着,未来任何企业的数字孪生系统,只要遵循这套标准,就可以直接与该集团的平台对接,实现设备共享、模型复用和数据互通。
“这就像USB接口,不管你是苹果还是安卓,只要支持USB,就能互相充电。”李明用了一个生动的比喻,“过去工业数字孪生是‘孤岛经济’,每个企业都自己建系统、自己开发模型,成本高、效率低,现在用分形标准,企业可以专注于自己的核心分形单元(比如某类设备的孪生模型),其他部分直接复用生态伙伴的成果,就像搭乐高一样快速构建数字孪生系统。”
2026年,一家中小型汽车零部件供应商的案例验证了这种生态模式的价值,该供应商