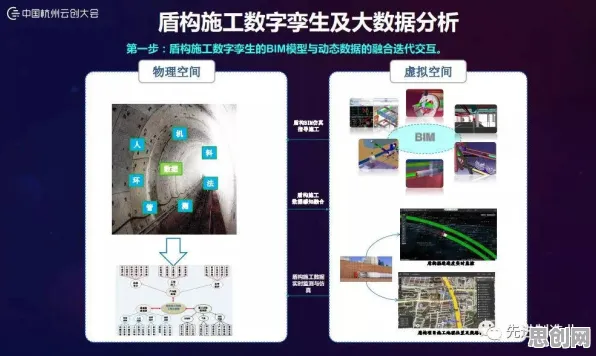
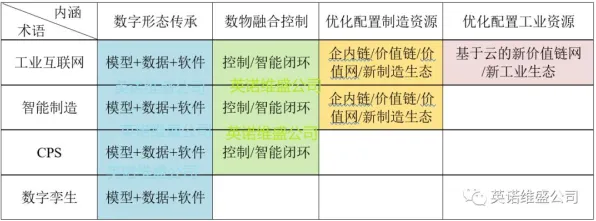
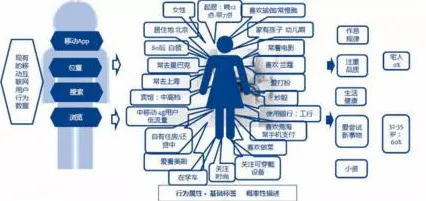
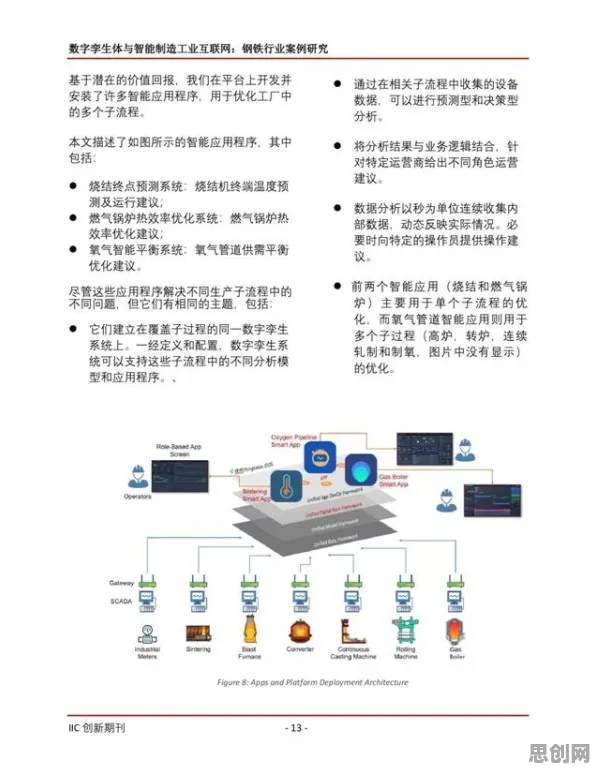
边缘计算+云协同:数字孪生的“双脑”架构
数字孪生的核心是“实时性”——物理设备的数据必须以毫秒级延迟同步到虚拟模型,模型的分析结果也要快速反馈到现实场景,如果所有数据都上传到云端处理,网络延迟和带宽成本会成为瓶颈;但如果完全依赖本地边缘设备,又无法支撑复杂模型的计算需求。“边缘计算+云协同”的混合架构,已成为2026年工业数字孪生的主流选择。 近期热度持续攀升聚焦儿童教育发展新趋势,应用场景不断拓展
以2026年某汽车制造企业的案例为例:该企业在冲压车间部署了数字孪生系统,用于实时监测冲压机的振动、温度和压力数据,每台冲压机旁安装了边缘计算节点(搭载轻量级AI芯片),负责采集传感器数据并运行简单的故障预测模型(如基于LSTM的振动异常检测),一旦检测到异常,边缘节点会立即触发本地警报,同时将关键数据(如异常时间、特征值)上传至云端,云端则运行更复杂的数字孪生模型,结合历史数据、设备参数甚至供应链信息,分析故障根源并生成维修方案,这种架构下,边缘节点处理了90%的实时数据,云端仅需处理10%的关键信息,既保证了响应速度,又降低了云端负载。
另一个典型案例来自能源行业:2026年某风电场通过数字孪生优化风机运维,每台风机顶部安装了边缘计算盒,实时采集风速、转速、功率等数据,并运行局部优化模型(如调整桨距角以匹配当前风速),所有数据同步至云端,云端模型结合气象预报、电网需求等外部数据,生成全场风机的全局优化策略(如哪些风机需要停机检修、哪些可以满负荷运行),这种“边缘管局部、云端管全局”的模式,使风电场年发电量提升了8%,运维成本降低了15%。
关键知识点:边缘计算与云的协同需要解决“数据同步”和“模型更新”两大问题,数据同步需采用轻量级协议(如MQTT),减少网络开销;模型更新则需设计“边缘-云”双向训练机制——云端训练的通用模型下发到边缘,边缘采集的新数据再上传至云端优化模型,形成闭环。
容器化部署:让数字孪生模型“随需而动”
数字孪生模型不是“一建了之”的静态系统,而是需要根据业务需求动态调整,汽车生产线可能需要根据新车型快速更新数字孪生模型;智慧城市的水务系统可能需要根据季节变化调整管网模拟参数,传统部署方式(如直接在虚拟机上运行模型)存在扩展性差、更新周期长的问题,而容器化技术(如Docker+Kubernetes)则能解决这些痛点。 压力缓解与能源管理热度持续上升,相关产业迎来新机遇
医疗健康与养生保健及家电数码热度持续上升,相关产业迎来新发展 2026年,某电子制造企业为解决SMT贴片机数字孪生模型的更新难题,采用了容器化部署方案,该企业有20条SMT生产线,每条线部署了独立的数字孪生容器,容器内封装了模型代码、依赖库和配置文件,当需要更新模型(如优化元件识别算法)时,开发团队只需在镜像仓库中推送新版本,Kubernetes会自动将新容器滚动更新到所有生产线,整个过程不超过5分钟,且无需停机,容器化还支持“弹性伸缩”——在生产高峰期,系统会自动增加数字孪生容器的数量以处理更多数据;低谷期则减少容器,降低资源消耗。
另一个案例来自航空航天领域:2026年某飞机制造商为测试新型发动机的数字孪生模型,采用了“容器化+混合云”架构,测试团队在私有云上运行核心模型(涉及机密数据),同时在公有云上部署多个容器化副本,用于并行模拟不同工况(如高温、高压、高速),每个副本都是一个独立容器,测试完成后可快速销毁,避免资源浪费,这种架构使测试周期从原来的3个月缩短至1个月,成本降低了40%。
关键知识点:容器化的核心优势是“环境隔离”和“快速部署”,数字孪生模型通常依赖特定版本的库(如Python 3.8、TensorFlow 2.10),容器能确保模型在不同环境中运行一致;容器镜像可以预编译,部署时无需重新安装依赖,速度提升数倍,但需注意,容器化对网络和存储要求较高,需配合CNI(容器网络接口)和CSI(容器存储接口)优化性能。

时序数据库:数字孪生的“记忆中枢”
数字孪生的价值不仅在于实时监控,更在于通过历史数据分析预测未来,通过分析设备过去3年的振动数据,可以预测其剩余寿命;通过模拟不同生产参数下的历史数据,可以优化当前工艺,如何高效存储、查询和分析海量时序数据(按时间顺序记录的数据),是数字孪生部署的关键。
传统关系型数据库(如MySQL)在处理时序数据时存在明显短板:写入性能低(无法支持每秒百万级数据点)、查询效率差(全表扫描耗时)、存储成本高(需预留大量索引空间),而专为时序数据设计的数据库(如InfluxDB、TimescaleDB)则能针对性解决这些问题。
2026年,某钢铁企业为优化高炉数字孪生系统,将数据存储从MySQL迁移至InfluxDB,高炉运行会产生每秒10万条数据(温度、压力、流量等),原MySQL方案需每10分钟批量写入一次,导致数据延迟;迁移后,InfluxDB支持每秒百万级写入,且通过“时间分区”和“压缩算法”将存储成本降低了60%,在查询方面,原方案查询“过去24小时温度异常”需5秒,新方案仅需0.2秒,因为InfluxDB针对时间范围查询优化了索引结构。
本周精准医疗与绿色街区及智慧医疗热度飙升,相关产业迎来新机遇 另一个案例来自智慧农业:2026年某大型农场通过数字孪生监测土壤湿度、气温等环境数据,以指导灌溉,农场部署了5000个传感器,每分钟上传一次数据,每天产生约7亿条记录,原方案使用MongoDB存储,查询“某区域过去一周湿度变化”需遍历所有文档,耗时超1分钟;迁移至TimescaleDB(基于PostgreSQL的时序扩展)后,通过“时间分片”和“连续聚合”功能,查询时间缩短至0.5秒,且支持按区域、作物类型等多维度下钻分析。

关键知识点:时序数据库的核心设计是“时间优先”和“高效压缩”,时间优先体现在索引结构上——数据按时间范围分区存储,查询时只需定位到对应分区,无需全表扫描;高效压缩则通过列式存储、差分编码等技术,将存储空间压缩至原数据的1/10~1/20,时序数据库通常支持“连续聚合”(如自动计算每小时平均值),减少实时查询的计算量。
安全架构:数字孪生的“防护网”
数字孪生涉及大量敏感数据(如设备参数、生产配方、供应链信息),一旦泄露可能造成重大损失,2026年,某化工企业因数字孪生系统安全漏洞,导致核心工艺参数被竞争对手获取,直接经济损失超2亿元,安全架构是数字孪生部署中不可忽视的环节。
当前工业数字孪生的安全架构通常采用“分层防御”策略:
-
数据采集层:传感器数据在传输前需加密(如采用TLS 1.3协议),防止中间人攻击;通过数字证书验证设备身份,避免伪造数据注入,2026年某汽车零部件厂商在部署数字孪生时,为每台设备颁发了X.509证书,只有通过认证的设备才能上传数据,有效拦截了90%的恶意攻击。
-
边缘计算层:边缘节点需部署轻量级安全模块(如基于TEE的可信执行环境),确保模型运行在隔离环境中,防止数据被窃取或篡改,2026年某风电企业发现,部分边缘节点因未启用安全启动功能,被植入恶意程序篡改风机转速数据,导致模型误