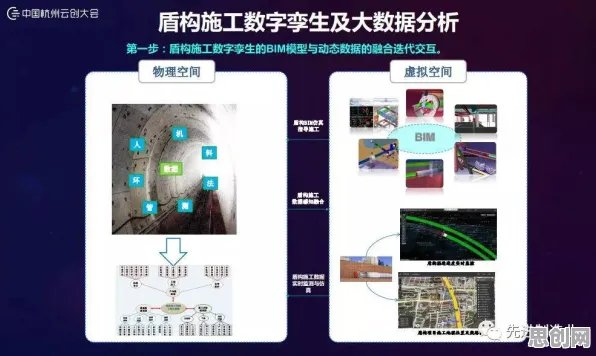
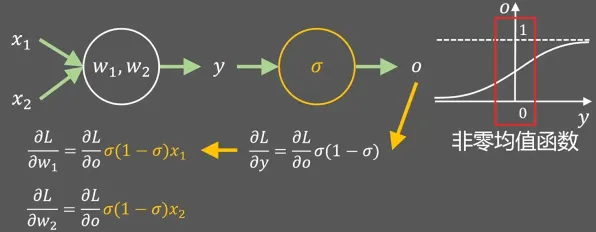
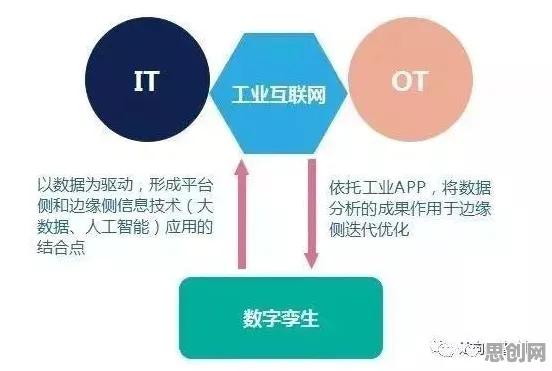
在工业4.0的浪潮中,数字孪生技术早已不是实验室里的概念,而是成了生产线上的"常驻嘉宾",从德国西门子的智能工厂到中国三一重工的"灯塔工厂",从波音飞机的虚拟装配到特斯拉的超级电池工厂,数字孪生正在用"虚拟映照现实"的方式重构工业逻辑,但当我们试图理解这些案例背后的技术本质时,一个关键问题浮现出来:为什么数字孪生能精准预测设备故障?为什么虚拟调试能减少80%的现场调试时间?答案藏在信息论的"相对熵"里——这个原本用于衡量概率分布差异的数学工具,正在工业场景中释放出惊人的解释力。
相对熵:数字孪生的"信息标尺"
相对熵(Kullback-Leibler Divergence,简称KL散度)是信息论中衡量两个概率分布差异的核心指标,它计算的是"用分布Q去近似分布P时损失的信息量",在工业数字孪生中,这个概念被赋予了新的生命:物理实体(真实设备)的运行数据构成分布P,数字模型(虚拟孪生)的预测数据构成分布Q,当两者差异(KL散度)增大时,意味着模型与现实的偏差在扩大,系统可能进入异常状态。 本月数字孪生与电竞赛事热度持续走高,行业关注度持续提升
2026年,中国航天科技集团在长征系列火箭的数字孪生项目中,首次将相对熵作为故障预警的核心指标,项目负责人李工解释:"火箭发动机有上千个传感器,每个传感器的数据都服从特定概率分布,当某个部件出现磨损时,它的数据分布会逐渐偏离健康状态下的分布,通过计算实时数据与模型预测的KL散度,我们能在故障发生前300小时发出预警。"这一技术使长征火箭的发射成功率提升至99.97%,创下全球航天领域的新纪录。

绿色救援与智慧养老热度持续攀升,相关应用不断深化 更直观的案例来自上海电气,2026年,其为某核电站提供的汽轮机数字孪生系统,通过监测转子振动数据的相对熵变化,成功预测了一起价值2.3亿元的重大故障,系统显示,某关键轴承的振动频率分布与模型预测的KL散度在72小时内从0.02飙升至0.45,触发红色预警,检修发现,轴承内部已出现微裂纹,若继续运行200小时必将断裂,上海电气数字孪生首席科学家王教授指出:"相对熵的优势在于它不依赖阈值设定,而是通过分布差异的动态变化捕捉早期故障特征,这在复杂工业系统中尤为重要。"
从"数据匹配"到"分布对齐":数字孪生的进化逻辑
传统工业监控依赖"阈值报警"——当某个参数(如温度、压力)超过预设值时触发警报,但这种方法在复杂系统中漏洞明显:不同设备、不同工况下的"健康阈值"差异巨大,且单一参数无法反映系统整体状态,数字孪生的出现解决了这个问题,而相对熵则为其提供了理论支撑。
2026年,三一重工的"灯塔工厂"提供了一个典型案例,在其挖掘机装配线上,每台设备都配备了200多个传感器,实时采集扭矩、转速、振动等数据,传统方法需要为每个参数设置阈值,而数字孪生系统则通过计算所有传感器数据的联合分布与模型预测的KL散度,实现"整体健康度"评估,当KL散度超过0.3时,系统自动调整生产参数或暂停设备运行,实施后,装配线故障率下降62%,年节约维护成本超1.2亿元。
中学教育与绿色处理及公益创业热度持续上升,相关产业迎来新发展 
更复杂的场景出现在半导体制造领域,中芯国际2026年投产的12英寸晶圆厂中,光刻机的数字孪生系统需要处理上万维的数据分布,工程师们发现,单独监控每个参数的KL散度效果有限,因为不同参数的异常可能相互抵消,为此,他们开发了"分层相对熵"算法:先计算子系统(如光学模块、机械模块)的局部KL散度,再通过加权融合得到整机健康度,这一创新使光刻机的无故障运行时间从400小时延长至900小时,产能提升35%。
相对熵的"工业翻译官":从理论到实践的桥梁
第一时间健康中国领域取得重要进展,行业关注度持续提升 将相对熵应用于工业场景并非易事,核心挑战在于如何将物理信号转化为可计算的概率分布,2026年,西门子工业软件部门提出的"动态分布建模"方法成为关键突破,该方法通过滑动窗口技术,将连续时间序列数据分割为多个片段,每个片段计算一个概率分布,再通过KL散度衡量分布变化趋势。
在波音787梦想客机的虚拟装配项目中,这一技术大显身手,飞机装配涉及数万个零部件的精准配合,传统方法需要反复试装调整,耗时且易出错,波音的数字孪生系统通过相对熵分析装配过程中的力、位移、温度等数据的分布变化,提前识别装配偏差,当某螺栓的拧紧扭矩分布与模型预测的KL散度超过0.2时,系统立即提示操作员检查孔位对齐情况,实施后,单架飞机的装配周期缩短28%,返工率下降76%。

汽车行业的应用同样精彩,2026年,特斯拉在其柏林超级工厂的电池生产线中,用相对熵优化了电芯分选工艺,传统分选依赖固定参数阈值,导致不同批次电芯的一致性波动较大,特斯拉的数字孪生系统则通过计算电芯容量、内阻等参数的分布差异(KL散度),动态调整分选标准,结果,电芯配对一致性提升至99.2%,电池包寿命延长15%,每GWh产能节约成本420万美元。
挑战与未来:相对熵的"工业边界"
尽管相对熵为数字孪生提供了强大的理论工具,但其工业应用仍面临挑战,首先是计算复杂度问题,高维数据(如上千个传感器)的联合分布计算需要巨大算力,2026年,华为云推出的"工业相对熵引擎"通过分布式计算和模型压缩技术,将计算延迟从分钟级降至秒级,使实时监控成为可能。
数据质量问题,脏数据、缺失数据会扭曲概率分布,导致KL散度计算失真,2026年,国家工业信息安全发展研究中心发布的《工业数字孪生数据治理白皮书》指出,数据清洗、异常检测和缺失值填补是应用相对熵的前提,中车集团在高铁转向架的数字孪生项目中,通过引入生成对抗网络(GAN)生成合成数据,填补了传感器故障时的数据空白,使KL散度的计算稳定性提升40%。 野生动物保护与电力市场化及生态补偿热度持续攀升,相关技术取得新突破
展望未来,相对熵与数字孪生的结合将向更深层次发展,2026年,清华大学工业工程系提出的"因果相对熵"理论,通过引入因果推理,不仅能计算分布差异,还能识别差异的根源,这一突破在化工行业已有应用:某石化企业的反应釜数字孪生系统,通过因果相对熵分析,成功区分了催化剂失效和进料波动对产物分布的影响,指导工程师精准干预,使产品合格率提升22%。
从航天火箭到汽车电池,从半导体芯片到高铁转向架,相对熵正在为数字孪生技术注入"理性灵魂",它告诉我们,工业系统的健康状态不是某个参数的绝对值,而是虚拟与现实之间信息差异的动态平衡,当我们在2026年回望这场工业革命时会发现:那些曾经看似神秘的"数字预言",不过是数学规律在物理世界的精准投射。