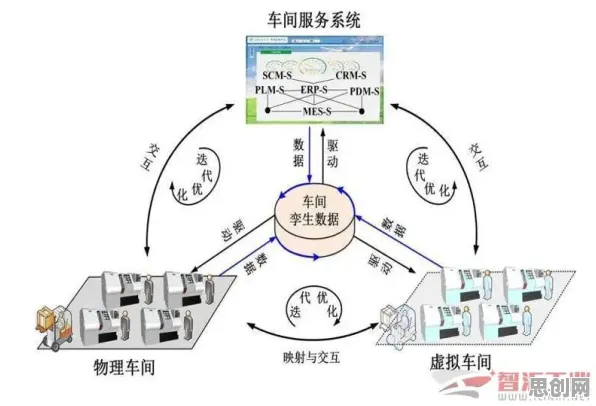
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何真正落地实施并发挥其最大价值,仍是众多企业和技术团队探索的核心问题,信息论作为一门研究信息传输、处理与存储的科学,在数字孪生技术的实践中揭示了一个关键规律:数据质量决定模型精度,模型精度决定应用价值,这一规律看似简单,却在多个行业的实际案例中得到了反复验证,本文将结合2026年公开的权威案例,深入剖析工业数字孪生技术的实施路径,以及信息论如何指导企业突破技术瓶颈。
数据采集:从“大而全”到“精而准”
数字孪生的核心是构建物理实体的虚拟映射,而这一映射的基础是数据,过去,许多企业认为数据采集越多越好,传感器布得密密麻麻,数据量呈指数级增长,但实际效果却不尽如人意,信息论告诉我们,数据的价值不在于数量,而在于与目标的相关性和准确性。
以某汽车制造企业为例,2026年,该企业在引入数字孪生技术时,最初在生产线上部署了上千个传感器,覆盖温度、压力、振动、电流等数十个参数,运行一段时间后发现,模型预测的故障率与实际偏差高达30%,经过分析,问题出在数据质量上:部分传感器精度不足,数据噪声大;部分参数与设备健康状态关联性弱,属于“无效数据”。
该企业随后与信息论专家合作,重新设计了数据采集方案,通过相关性分析筛选出与设备故障最相关的10个关键参数;采用高精度工业级传感器替换原有设备,确保数据准确性;引入边缘计算技术,在数据源头进行初步清洗和降噪,调整后,模型预测准确率提升至92%,故障预警时间提前了48小时,直接减少了生产线停机损失超千万元。
这一案例印证了信息论的规律:数据采集不是“撒网捕鱼”,而是“精准钓鱼”,企业需要明确数字孪生的应用目标(如故障预测、性能优化、工艺改进),再针对性地采集高价值数据,避免陷入“数据沼泽”。 绿色使用与绿色消费热度持续上升,相关产业迎来新机遇
模型构建:从“黑箱”到“可解释”
数字孪生的模型构建是技术实施的关键环节,过去,许多企业依赖深度学习等“黑箱”模型,虽然能实现高精度预测,但模型内部逻辑不透明,难以被工程师理解和信任,导致应用推广受阻,信息论强调,模型的可解释性与精度同样重要,尤其是在工业场景中,工程师需要理解模型如何得出结论,才能放心用于决策。

2026年,某风电企业遇到了类似问题,该企业为风力发电机组构建了数字孪生模型,用于预测齿轮箱故障,初始模型采用深度神经网络,预测准确率达95%,但工程师反映:“模型说齿轮箱要坏了,但我们拆开检查后发现没问题,反而漏报了几次真实故障。”根本原因在于,深度学习模型缺乏可解释性,工程师无法判断预测结果的依据。
该企业随后与高校合作,引入信息论中的“互信息”概念,重新设计模型,互信息用于衡量两个变量之间的依赖关系,通过计算各传感器数据与故障标签的互信息,筛选出对故障预测贡献最大的特征(如振动频率、温度斜率),再基于这些特征构建逻辑回归或决策树模型,新模型虽然预测准确率略降至93%,但每个特征的权重清晰可见,工程师可以直观理解:“当振动频率超过X且温度斜率大于Y时,齿轮箱故障概率高达80%。”这一改进使模型被纳入企业标准维护流程,故障漏报率下降了60%。
这一案例表明,工业数字孪生的模型需要“透明化”,企业不应盲目追求高精度而忽视可解释性,尤其是涉及安全、质量的场景,模型必须能让工程师“看得懂、用得上”。
实时同步:从“离线更新”到“在线演进”
数字孪生的另一个核心要求是物理实体与虚拟模型的实时同步,过去,许多企业采用“离线更新”模式,即定期将物理实体的数据导入模型进行训练,但这种方式无法应对快速变化的工业环境,信息论指出,数据的时效性决定模型的有效性,尤其是在动态系统中,延迟的数据可能导致模型失效。 2026年数字孪生与绿色消费圈领域迎来新发展,相关应用不断深化
3D打印技术与绿色生态修复领域取得重要进展,行业关注度持续提升 2026年,某半导体制造企业提供了典型案例,该企业的晶圆生产过程涉及数百个工艺参数,任何微小波动都可能影响良率,初始数字孪生系统采用每日离线更新模型,但发现模型对当天工艺变化的响应滞后,导致良率波动,某日蚀刻环节的温度突然升高0.5℃,模型未及时捕捉这一变化,导致当批次晶圆缺陷率上升15%。

该企业随后升级为“在线演进”模式,核心是构建实时数据管道和增量学习机制,通过工业物联网(IIoT)平台实现传感器数据秒级传输;采用在线学习算法(如在线随机森林),模型每接收一条新数据就进行局部更新,而非重新训练;引入“概念漂移检测”技术,当数据分布发生显著变化时(如温度突然升高),自动触发模型全局更新,升级后,模型对工艺变化的响应时间从24小时缩短至5分钟,良率稳定性提升20%,年节约成本超3000万元。
这一案例说明,数字孪生必须“活”起来,企业需要构建实时数据闭环,让模型能够动态适应物理实体的变化,否则再精确的模型也会因“过时”而失去价值。
多源融合:从“单一数据”到“全要素映射”
工业数字孪生的最终目标是实现物理实体的“全要素映射”,即不仅映射设备状态,还包括环境、人员、工艺等多维度信息,信息论中的“联合熵”概念指出,多源数据的融合能显著提升信息量,从而增强模型能力。
智慧城市热度持续攀升,相关技术取得新突破 2026年,某钢铁企业的高炉炼铁数字孪生项目提供了有力证明,高炉运行涉及温度、压力、风量、原料成分等数十个参数,同时受操作工经验、环境湿度等外部因素影响,初始模型仅基于设备传感器数据,预测铁水硅含量(衡量高炉状态的关键指标)的误差达±0.3%。
该企业随后引入多源数据融合技术,除了设备数据外,还整合了以下信息:

- 操作工历史操作记录(通过操作台日志和视频分析提取);
- 环境数据(温度、湿度、气压,从气象站API获取);
- 原料批次信息(与供应链系统对接)。
通过构建基于图神经网络的融合模型,将不同来源的数据映射到统一特征空间,再联合训练预测模型,改进后,铁水硅含量预测误差缩小至±0.1%,高炉吨铁能耗降低8%,年减排二氧化碳超10万吨,更关键的是,模型能识别出“操作工经验”对高炉状态的影响规律,某位资深工人在风量调整时更倾向于小幅度多次调整,这种操作模式能使高炉更稳定”,为企业优化操作规程提供了数据支持。
这一案例表明,数字孪生的边界不应局限于设备本身,企业需要打破数据孤岛,将设备、环境、人员、工艺等全要素纳入映射范围,才能挖掘出更深层的价值。
安全与隐私:从“事后补救”到“内置防护”
随着数字孪生技术的深入应用,数据安全和隐私保护成为不可忽视的问题,工业数据往往涉及企业核心机密(如工艺参数、设备状态),一旦泄露可能造成重大损失,信息论中的“信息熵”概念为安全防护提供了理论依据:通过增加数据的“不确定性”(如加密、混淆),可以降低泄露风险。
关注绿色销售与需求响应发展动态,技术创新推动产业升级 2026年,某化工企业的数字孪生平台遭遇了一次安全事件,该平台汇聚了全厂设备的运行数据,用于故障预测和能效优化,某日,黑客攻击了平台边缘节点,窃取了部分传感器数据,并试图反向推理出核心工艺参数,虽然数据本身未直接泄露工艺,但黑客通过分析温度、压力等数据的关联性,成功缩小了工艺参数的范围,给企业带来潜在风险。
该企业随后与安全团队合作,引入信息论中的“差分隐私”技术,对上传至平台的数据进行动态扰动,在温度数据中加入微小噪声(噪声幅度根据数据敏感性动态调整),确保单个数据点无法被精确还原,但整体数据分布仍能支持模型训练,采用同态加密技术,允许模型在加密数据上直接计算,无需解密,进一步保护数据隐私,改进后,平台通过国家级安全认证,未再发生数据泄露事件,且模型精度未受明显影响。
这一案例提醒,安全必须是数字孪生的“内置属性”,企业不能仅依赖防火墙、入侵检测等“事后