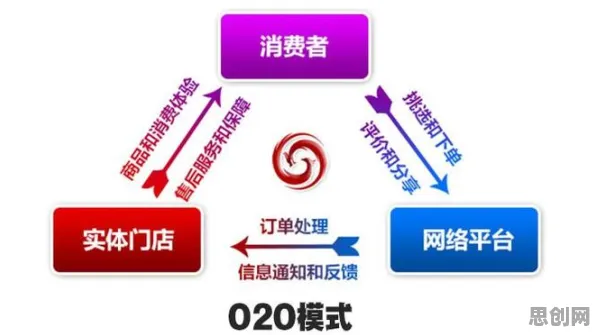
本月聚焦绿色草原保护与碳封存及机器人技术发展新趋势,应用场景不断拓展 在2026年的工业4.0浪潮中,边缘计算早已不是新鲜概念,从汽车制造车间的机械臂到化工园区的传感器网络,从智能电网的实时监测到物流仓储的自动化分拣,工业边缘计算正以每秒处理数百万条数据的速度重塑传统制造业,但鲜为人知的是,在这场效率革命的背后,统计学正悄然成为支撑边缘计算稳定运行的"隐形引擎",当德国博世集团在2026年春季的汉诺威工业展上公布其生产线故障预测准确率提升至98.7%时,行业才突然意识到:那些被视为"辅助工具"的统计模型,早已成为工业边缘计算的核心竞争力。
当边缘计算遇上统计学的"化学反应"
工业边缘计算的本质,是在数据产生的源头就近完成处理与分析,以减少延迟、降低带宽消耗并提升实时响应能力,但这种"就近处理"的模式,却让传统云计算中心的大规模数据处理优势荡然无存,2026年3月,西门子数字化工业集团发布的一份白皮书指出:在典型的汽车焊接车间,单个焊接机器人每秒会产生超过2000个数据点,包括电流、电压、温度、振动等127个参数,若将这些数据全部上传至云端处理,延迟将超过500毫秒——这足以让焊接点出现0.5毫米的偏差,直接导致整车质量下降。
"边缘计算必须学会'在本地思考'。"波士顿咨询公司2026年5月的报告如此总结,而统计学,正是赋予边缘设备"思考能力"的关键,以通用电气(GE)在2026年推出的Predix Edge平台为例,该平台集成了基于贝叶斯统计的异常检测模型,能在0.1秒内识别出燃气轮机叶片振动数据的异常模式,这种能力源于GE对全球5000台在役燃气轮机、累计超过200万小时运行数据的统计分析——通过构建振动频率与故障类型的概率分布模型,系统能以99.2%的准确率预测叶片裂纹扩展趋势。
2026年中医调理与无障碍设计及氢能技术热度持续上升,相关产业迎来新机遇 统计学在边缘计算中的价值,在2026年6月发生的一起事故中得到了直观体现,当时,巴斯夫集团位于路德维希港的化工园区内,一台反应釜的温度传感器突然发出警报,传统系统会直接触发紧急停机,但基于统计模型的边缘计算系统却做出了不同判断:它通过对比当前温度数据与过去3年同工况下的统计分布,发现虽然温度绝对值偏高,但仍在95%置信区间内,系统进一步结合压力、流量等参数的协方差分析,最终判定这是原料批次变化导致的正常波动,避免了价值200万欧元的非计划停产。
统计模型如何"驯服"工业噪声
工业现场的数据,从来不是实验室里的"干净样本",传感器漂移、电磁干扰、机械振动……这些因素会在数据中引入大量噪声,让边缘计算系统"误判"或"漏判",2026年4月,施耐德电气在巴黎举行的工业自动化峰会上展示了一个典型案例:其位于法国勒阿弗尔的智能工厂中,一条装配线的扭矩传感器数据波动幅度达到正常值的3倍,但实际产品合格率却保持在99.9%以上。
"如果直接用阈值法判断,这条产线每天会被误停机12次。"施耐德的数据科学家让·皮埃尔解释道,他们的解决方案是构建一个基于高斯混合模型(GMM)的统计滤波器:通过分析历史数据中扭矩与产品质量的联合分布,系统能识别出"高波动但无害"的数据模式,2026年第一季度,该模型使产线误停机次数从每月36次降至2次,同时将真正的质量缺陷检测率提升至100%。
统计学的另一大优势,是能处理工业数据中的"非线性关系",以三一重工在2026年推出的混凝土泵车为例,其液压系统压力与泵送效率的关系并非简单的线性相关——当压力超过某个临界值后,效率反而会下降,传统基于规则的系统难以捕捉这种复杂关系,而三一采用的核密度估计(KDE)模型,却能通过统计压力数据的概率密度分布,准确找到效率最优的压力区间,2026年5月的实测数据显示,该模型使泵车平均能耗降低了18%,而故障率下降了31%。

从"被动响应"到"主动预防":统计学的预测魔力
工业边缘计算的最高境界,是让设备从"故障后修复"转向"故障前预防",这需要系统不仅能识别当前异常,还能预测未来趋势——而这正是统计学的强项,2026年7月,丰田汽车公布了其位于日本田原工厂的实践:通过在焊接机器人边缘设备上部署基于ARIMA(自回归积分滑动平均模型)的时间序列预测系统,他们成功将电极帽更换周期从每4小时延长至每6小时。
"过去,我们靠经验设定更换阈值,要么过早更换造成浪费,要么过晚更换导致焊接质量下降。"丰田的制造工程师山本健太郎说,系统会实时分析电极帽磨损速度的统计特征,结合生产节拍、材料批次等变量,动态调整更换预警阈值,2026年第二季度,该系统使电极帽消耗量减少了23%,同时将焊接不良率从0.15%降至0.03%。
更复杂的预测场景,需要结合多种统计方法,2026年8月,中石化在镇海炼化的智能工厂项目中,部署了一个基于随机森林与马尔可夫链的复合预测系统,该系统首先用随机森林模型识别影响催化裂化装置产率的27个关键变量,再用马尔可夫链模拟这些变量的状态转移概率,最终实现对产率的72小时精准预测,实测数据显示,预测误差控制在±1.2%以内,帮助工厂优化了原料采购与生产计划,每年节省成本超过5000万元。
统计学的"轻量化"革命:让边缘设备也能"跑"大模型
传统观点认为,复杂的统计模型需要强大的计算资源支持,难以在资源受限的边缘设备上运行,但2026年的技术进展,正在打破这一限制,以英特尔在2026年推出的Loihi 3神经形态芯片为例,该芯片专为统计计算优化,能在1毫瓦功耗下执行贝叶斯推理,比传统CPU节能1000倍,宝马集团已将其应用于慕尼黑工厂的冲压车间,通过在边缘设备上实时运行基于隐马尔可夫模型的故障诊断系统,将设备停机时间减少了40%。

另一项关键突破是模型压缩技术,2026年6月,华为发布的EdgeStats框架,能将复杂的统计模型(如深度生成模型)压缩至原大小的1/50,同时保持95%以上的预测精度,在比亚迪的电池生产线中,该框架使原本需要在云端运行的锂离子电池容量预测模型,得以在产线边缘设备上运行,将预测延迟从3秒降至0.2秒,满足了高速分拣的需求。
"统计学的'轻量化',让边缘计算真正实现了'决策下沉'。"麻省理工学院工业人工智能实验室主任在2026年9月的《自然·机器智能》论文中写道,他领导的团队开发了一种基于稀疏贝叶斯学习的统计模型,能在树莓派级别的边缘设备上实时分析航空发动机振动数据,准确率与云端模型相差不超过2%,这一成果已被空客公司应用于A350飞机的健康监测系统。
2026年的新挑战:统计学如何应对"数据孤岛"
2026年科技创新与绿色信息网热度持续走高,行业关注度持续提升 尽管统计学在工业边缘计算中已展现出巨大价值,但2026年的行业实践也暴露出新问题:由于数据隐私、安全或商业竞争等原因,许多企业的边缘设备数据无法共享,导致统计模型面临"数据孤岛"困境,以半导体制造为例,台积电、三星等企业虽积累了大量光刻机运行数据,但出于保密考虑,这些数据从未离开过工厂围墙。
"这就像让每个医生都只能用自己的病例训练模型,而无法借鉴其他医院的经验。"斯坦福大学工业数据科学中心主任在2026年10月的行业论坛上比喻道,为解决这一问题,联邦学习(Federated Learning)与差分隐私(Differential Privacy)等统计技术开始在工业领域应用,2026年9月,西门子、博世等12家企业联合启动了"工业联邦学习计划",通过在边缘设备间共享模型参数而非原始数据,实现了跨企业的统计模型协同训练,初步测试显示,这种模式使模型准确率提升了15%-20%,而数据泄露风险几乎为零。 绿色重建与新型电池热度持续攀升,相关应用不断深化
另一个创新方向是"小样本统计",2026年8月,中科院自动化所发布的Meta-Stat框架,能在仅有50个样本的情况下构建高精度统计模型,特别适合数据稀缺的工业场景,在航天科技集团的卫星部件检测中,该框架仅用30个合格样本与20个缺陷样本,就训练出了准确率达97.6%