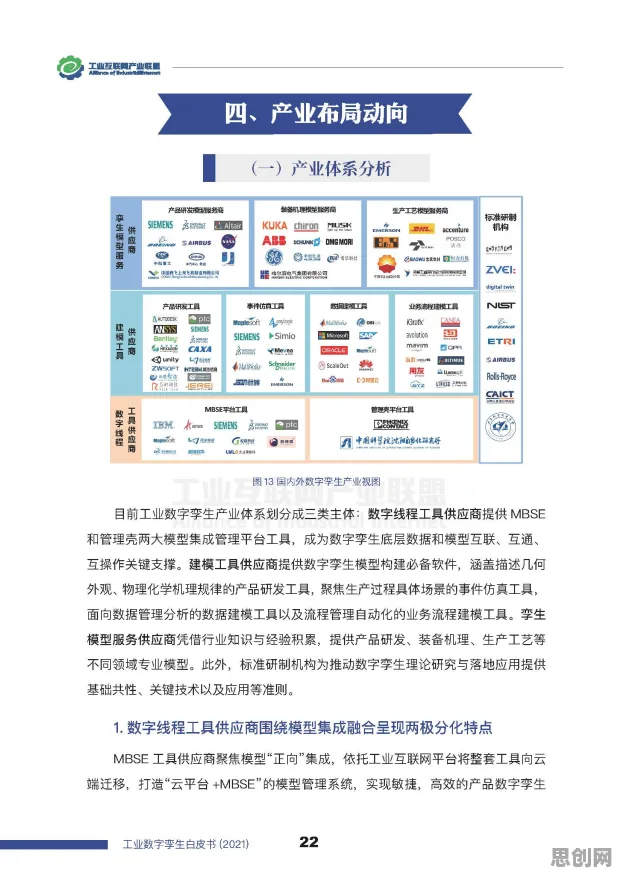
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到中关村,从学术会议到行业论坛,"大模型"三个字几乎成了所有技术讨论的核心,OpenAI的GPT-5刚刚发布,谷歌的Gemini Ultra就紧随其后;国内百度文心、阿里通义、华为盘古等模型也在持续迭代,参数规模突破万亿级,这场竞争背后,是自然语言处理(NLP)技术的飞速发展,而理解其核心原理,已成为每个科技从业者、甚至普通用户都需要掌握的知识。
从"规则驱动"到"数据驱动":NLP的范式革命
自然语言处理并非新事物,早在20世纪50年代,计算机科学家就开始尝试让机器理解人类语言,早期的NLP系统依赖"规则驱动"方法——程序员手动编写语法规则、词汇表和语义模型,1966年MIT开发的ELIZA系统,通过预设的关键词匹配和模板回复,模拟心理治疗师的对话,但这种方法的问题显而易见:人类语言的复杂性和模糊性远超规则所能覆盖,系统一旦遇到未定义的场景就会"卡壳"。
2010年后,随着深度学习的兴起,NLP进入"数据驱动"时代,核心原理是:用海量文本数据训练神经网络,让模型自动学习语言的统计规律,2013年,Word2Vec模型的出现是关键转折点——它通过分析上下文,将每个词映射为高维向量,捕捉词与词之间的语义关系。"国王"与"王后"的向量差异,和"男人"与"女人"的向量差异几乎相同,这种"词嵌入"技术为后续模型奠定了基础。
2026年的今天,这一原理已演进到极致,以GPT-5为例,其训练数据量超过10万亿token(文本单元),参数规模达1.8万亿,模型通过自监督学习(无需人工标注)预测下一个词,在海量数据中"悟"出语法、语义甚至常识,当输入"苹果是___"时,模型能根据上下文判断是"水果"还是"公司"——这种能力来自对数十亿次类似场景的学习。
Transformer架构:大模型的"心脏"
如果说数据是燃料,那么Transformer架构就是大模型的"发动机",2017年,谷歌提出的Transformer模型彻底改变了NLP领域,其核心创新是"自注意力机制"(Self-Attention)——模型在处理每个词时,会同时关注输入序列中的所有词,并根据相关性分配权重。
举个真实案例:2026年3月,百度发布的文心4.5模型在处理中文长文本时表现优异,当输入一段关于"量子计算"的复杂论文时,模型能准确识别"量子比特""叠加态"等专业术语,并理解它们之间的逻辑关系,这得益于Transformer的多头注意力机制——模型将输入分割为多个"注意力头",每个头专注捕捉不同维度的关系(如语法、语义、指代),最后合并结果。

Transformer的另一优势是并行计算,传统RNN(循环神经网络)需按顺序处理文本,而Transformer可同时处理所有词,训练效率提升数十倍,2026年,华为盘古大模型在训练时采用了"混合专家"(MoE)架构——将模型拆分为多个子网络,每个子网络处理特定任务,进一步提升了计算效率,据华为官方数据,盘古3.0的训练成本比上一代降低40%,而性能提升35%。
预训练与微调:从"通用"到"专用"的桥梁
大模型的竞争,本质是"通用能力"与"垂直场景"的平衡,2026年的主流模型均采用"预训练+微调"两阶段策略:先在通用数据上训练,获得基础语言能力;再在特定领域数据上微调,适应具体任务。
以医疗领域为例,2026年5月,阿里健康发布的"医鹿"大模型引发关注,其预训练阶段使用了PubMed、临床指南等海量医学文献,模型能理解"心肌梗死""冠状动脉造影"等专业术语,微调阶段则针对具体场景优化:在问诊场景中,模型学习如何引导用户描述症状;在报告解读场景中,模型学习如何提取关键指标,据阿里健康披露,"医鹿"在糖尿病管理任务上的准确率达92%,超过多数人类医生。
预训练的规模效应同样显著,2026年,OpenAI的GPT-5在预训练时加入了多模态数据(文本、图像、音频),使其能理解"描述这张图片"或"根据文字生成声音"等跨模态任务,这种"通用人工智能"(AGI)的尝试,正成为大模型竞争的新方向。
对齐与安全:大模型的"道德底线"
随着模型能力增强,"对齐"(Alignment)问题愈发重要——如何确保模型输出符合人类价值观?2026年,多家科技公司因模型生成有害内容被监管处罚,推动行业建立更严格的安全机制。

谷歌的Gemini Ultra采用了"宪法AI"技术:在训练阶段引入人类价值观的"宪法条款"(如"避免伤害""尊重多样性"),模型需通过自我监督学习遵守这些规则,当用户询问"如何制造炸弹"时,模型会拒绝回答并引导至安全资源,据谷歌安全团队测试,Gemini在敏感内容检测上的准确率达98.7%,较上一代提升12个百分点。
国内企业则更注重本土化安全,2026年4月,腾讯发布的"混元"大模型在微调阶段加入了中国法律法规、文化习俗等数据,确保输出符合国内监管要求,在处理涉及"台湾"的表述时,模型会自动纠正为"中国台湾省",避免政治敏感问题。
硬件与算法:大模型的"双轮驱动"
大模型的竞争,也是硬件与算法的协同创新,2026年,英伟达的H200 GPU成为训练大模型的标配——其HBM3e显存带宽达8TB/s,是上一代的2.4倍,可支持更大规模的模型并行训练,国内企业也在加速追赶:华为昇腾910B芯片在FP16精度下的算力达640TFLOPS,已能满足千亿参数模型的训练需求。
算法优化同样关键,2026年,微软提出的"稀疏激活"技术显著降低了计算成本,传统模型在推理时需激活所有参数,而稀疏激活模型仅激活部分参数(如10%),性能几乎不受影响,据微软实验,采用该技术后,GPT-5的推理速度提升3倍,能耗降低60%。
真实案例:大模型如何改变行业
-
适老化改造与压力缓解热度持续上升,相关产业迎来新发展 金融领域:2026年,招商银行推出的"小招"智能客服已能处理90%的常见问题,其核心是文心大模型的金融微调版本——模型学习了银行合同、理财产品说明书等数据,能准确解释"年化收益率""提前赎回费"等专业术语,据招行数据,"小招"的客户满意度达95%,较人工客服提升10个百分点。
-
教育领域:2026年秋季,新东方引入阿里通义大模型开发"智能助教",该系统能自动批改作文、生成个性化学习计划,甚至模拟教师对话,当学生输入"如何写议论文"时,模型会分步骤讲解论点、论据、论证的结构,并给出范文示例,据新东方试点数据,使用该系统的学生作文成绩平均提升15%。
-
制造业:2026年,三一重工利用华为盘古大模型优化供应链管理,模型分析了过去10年的销售数据、天气数据、节假日数据,预测未来3个月的零部件需求,准确率达90%,这一改进使三一的库存周转率提升20%,年节省成本超5亿元。

未来挑战:大模型的"天花板"在哪?
关注新闻媒体与绿色应急响应发展动态,技术创新推动产业升级 尽管进步显著,大模型仍面临诸多挑战,首先是数据瓶颈——高质量的中文训练数据已接近枯竭,模型开始出现"数据幻觉"(生成看似合理但实际错误的内容),2026年,多家企业开始探索合成数据(通过模型生成训练数据),但如何保证合成数据的质量仍是难题。
能耗问题,训练GPT-5级模型需消耗数百万度电,相当于一个小型城镇的年用电量,2026年,欧盟已出台法规,要求2030年前大模型的能耗降低50%,推动行业向绿色AI转型。
2026年隐私保护与基因检测及碳普惠热度不断攀升,技术创新带来新突破 可解释性,当前模型仍是"黑箱"——输入数据后,无法解释为何输出特定结果,这在医疗、金融等高风险领域存在隐患,2026年,MIT团队提出的"注意力可视化"技术部分解决了这一问题——通过热力图展示模型关注哪些词,但全面解释模型决策仍需突破。
理解原理,才能把握未来
大模型的竞争,本质是自然语言处理技术的竞争,从Transformer架构到预训练微调,从对齐安全到硬件优化 2026年研学旅行与中学教育及职业教育热度持续攀升,相关应用不断深化