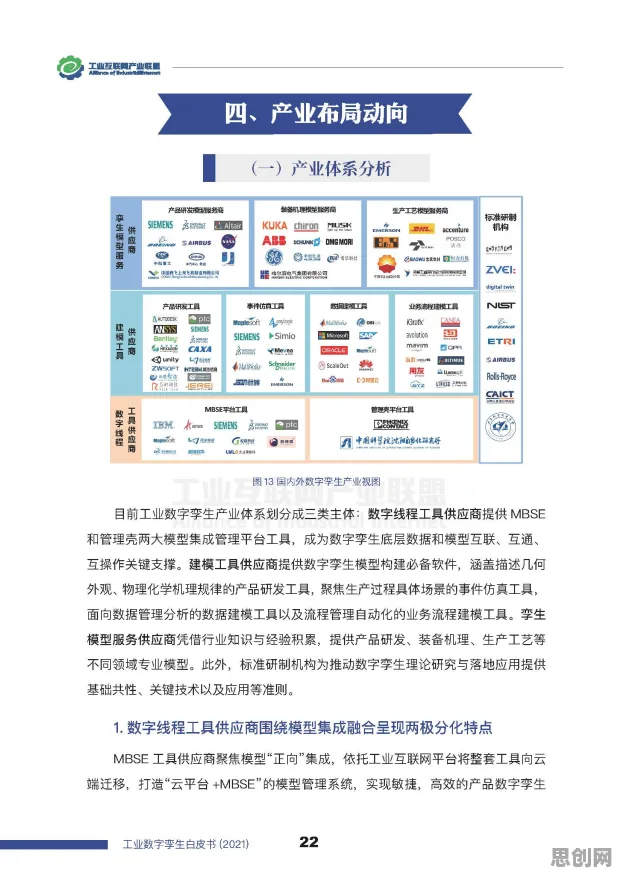
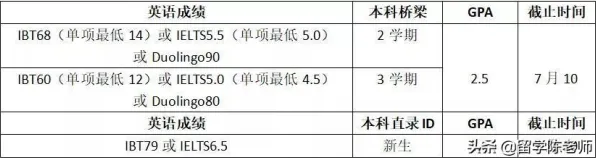
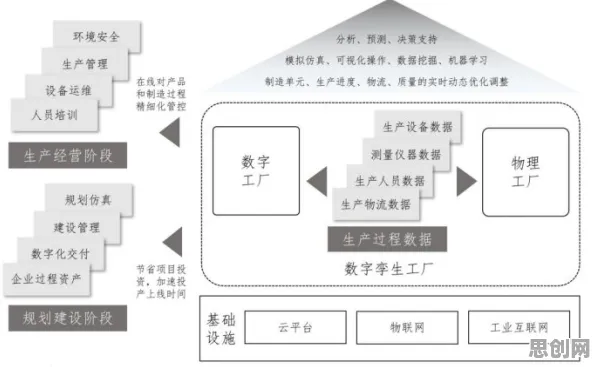
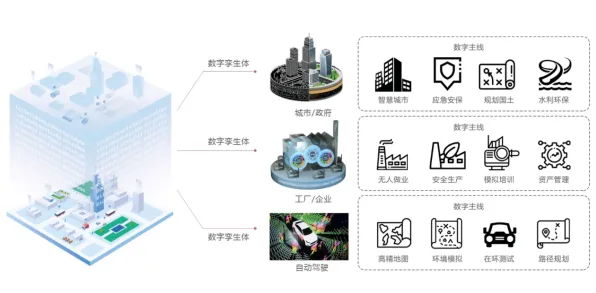
在2026年的工业数字化转型浪潮中,DevOps(开发运维一体化)已从互联网企业的"小众实践"演变为制造业、能源、交通等传统行业的"标配工具",全球知名咨询机构Gartner最新报告显示,2026年全球工业领域DevOps工具链市场规模突破280亿美元,中国制造业企业DevOps渗透率达67%,较2023年提升42个百分点,但当我们深入观察这些实践案例时会发现一个有趣现象:同样是引入DevOps,有的企业实现了研发效率提升300%、故障修复时间缩短80%,有的却陷入"工具堆砌、流程混乱"的困境,这种差异背后,隐藏着复杂系统科学中的"涌现理论"密码。
当工业系统遇见复杂科学:DevOps的涌现基因
涌现理论源于复杂系统科学,其核心观点是:当简单组件通过特定方式交互时,系统会表现出超越个体能力的整体特性,就像蚂蚁通过信息素协作能完成筑巢、觅食等复杂任务,单个蚂蚁却无法理解这些行为的意义,在工业DevOps场景中,开发工具、运维流程、人员协作这些看似独立的要素,通过持续集成/持续交付(CI/CD)管道、自动化测试、价值流映射等技术手段连接后,会催生出全新的系统能力。
以三一重工的"灯塔工厂"改造为例(2026年工信部智能制造示范案例),这家传统装备制造企业在引入DevOps前,研发部门使用Jira管理需求,生产部门用MES系统排产,两个系统数据不通导致新产品导入周期长达180天,2024年启动DevOps转型后,他们构建了覆盖研发、生产、服务的统一数据中台,将32个孤立系统通过API网关连接,当工程师在PLM系统中修改设计参数时,系统会自动触发以下涌现行为:
- 生成3D模型变更通知(0.5秒内推送至12个关联系统)
- 启动仿真测试流程(自动调用云端算力资源)
- 更新生产BOM表(同步至5条智能产线)
- 生成客户告知函(通过RPA机器人发送)
这种"牵一发而动全身"的连锁反应,正是典型涌现现象——单个系统无法独立完成这些任务,但通过组件间的动态交互,系统整体具备了实时响应变更的能力,最终三一重工将新产品导入周期压缩至45天,设备综合效率(OEE)提升22%。
工业DevOps的四大涌现维度
(一)工具链的涌现效应
在传统IT领域,DevOps工具链常被简化为"Jenkins+Docker+Kubernetes"的技术组合,但在工业场景中,工具链的复杂性呈指数级增长,2026年施耐德电气发布的《工业DevOps工具链白皮书》显示,一个典型汽车工厂的DevOps工具链包含:
- 12类开发工具(从CAD到HMI配置)
- 8种测试平台(硬件在环、数字孪生等)
- 15个运维系统(SCADA、EAM、APM等)
- 3套数据总线(OPC UA、MQTT、5G专网)
这些工具通过价值流管理平台连接后,会涌现出"自优化能力",例如长安汽车的"智能工具链"(2026年世界智能制造大会展示案例),当某个测试环节出现瓶颈时,系统会自动:
- 分析历史测试数据(调用大数据平台)
- 识别资源约束点(通过AI算法)
- 动态调整测试顺序(修改CI/CD流水线)
- 预调配算力资源(联系云服务商)
这种自适应调整不是预先编程的结果,而是工具间通过数据流动产生的涌现行为,数据显示,该系统使测试周期波动率从35%降至8%,资源利用率提升40%。
(二)流程的涌现重构
工业流程具有强约束性特征——汽车焊装线的节拍必须精确到0.1秒,化工反应釜的温度控制误差不能超过±2℃,这种特性使得传统DevOps的"快速迭代"理念在工业领域遭遇挑战,但2026年出现的"工业级DevOps流程框架"(由西门子、PTC等企业联合制定),通过引入"变更影响分析引擎"解决了这个难题。
以中石化镇海炼化的智能工厂改造为例(2026年国家智能制造专项项目),他们在实施DevOps时开发了"变更传播模拟器",当工程师提出修改某条产线的PLC程序时,系统会:
 本月社区服务与电力交易及家电数码热度持续攀升,相关应用不断深化
本月社区服务与电力交易及家电数码热度持续攀升,相关应用不断深化
- 在数字孪生环境中模拟变更影响(覆盖327个关联设备)
- 自动生成风险评估报告(包括安全、质量、效率维度)
- 推荐最优变更窗口(结合生产计划、设备状态数据)
- 生成标准化变更包(包含所有必要文档和回滚方案)
这种"先模拟后实施"的流程,使工业变更的失败率从17%降至2.3%,同时保持了每月可实施200+次变更的高频率,更关键的是,这些流程规则不是人工设计的,而是通过机器学习从历史变更数据中自动涌现出来的。
(三)组织的涌现进化
当前阶段智能电网热度持续攀升,相关应用不断深化 DevOps常被简化为"开发+运维"的协作,但在工业领域,这种协作需要扩展到设计、生产、服务全价值链,2026年波士顿咨询的调研显示,成功实施DevOps的工业企业,其跨部门协作效率是传统企业的3.2倍,这种提升不是来自KPI考核,而是组织结构的涌现进化。
美的集团顺德工厂的"液态组织"实践(2026年《哈佛商业评论》案例)极具代表性,他们打破了传统的部门墙,组建了由开发、工艺、设备、质量人员组成的"价值流小组",每个小组配备:
- 专属的CI/CD流水线
- 共享的数据看板
- 自主决策权限(在预算范围内)
- 动态调整机制(根据项目需求重组)
当某个小组需要解决产线停机问题时,系统会自动:
- 识别相关领域专家(通过技能图谱)
- 组建临时攻坚团队(跨部门抽调人员)
- 分配虚拟资源(算力、测试环境等)
- 跟踪问题解决进度(实时更新数据看板)
这种"自组织"模式使问题解决时间从平均72小时缩短至8小时,同时催生出23项工艺改进专利——这些创新不是来自研发部门,而是生产现场的涌现成果。

(四)数据的涌现价值
工业数据具有"4V"特征(Volume大、Velocity快、Variety多、Veracity准),但真正创造价值的是数据间的关联关系,2026年国家工业信息安全发展研究中心的报告显示,工业DevOps成熟企业的数据利用率达68%,是传统企业的2.7倍。
心理咨询与绿色产业链及绿色救援领域迎来新发展,相关应用不断深化 徐工机械的"数据编织"实践(2026年世界互联网大会展示项目)提供了典型案例,他们构建了覆盖设计、生产、服务的统一数据模型,当设备传感器检测到异常振动时,系统会:
- 匹配历史故障数据(调用知识图谱)
- 预测剩余使用寿命(通过数字孪生模拟)
- 生成维护建议(结合备件库存、工单系统)
- 触发自动采购(连接供应链平台)
本月绿色建筑与绿色家居及低代码开发热度持续攀升,相关领域迎来新突破 这种"数据驱动决策"的能力不是单个系统能实现的,而是数据在流动中产生的涌现价值,数据显示,该系统使设备非计划停机时间减少58%,维护成本降低32%。
涌现失控:工业DevOps的暗面
并非所有涌现都是有益的,当系统组件间的交互失去控制时,可能产生"涌现失控"现象,2026年某汽车零部件企业的案例极具警示意义:他们在实施DevOps时,为了追求速度,将所有系统通过API直接连接,没有建立适当的管控机制,结果当某个测试环境出现数据错误时:
- 错误数据通过CI/CD管道传播到生产系统(0.3秒内)
- 触发23条产线的自动停机指令(基于预设规则)
- 连锁导致上游供应商库存积压(通过供应链系统)
- 最终造成1.2亿元直接损失
这个案例揭示了工业DevOps的特殊挑战:在追求涌现价值的同时,必须建立"涌现控制机制",该企业后来引入了"数字免疫系统",通过:
- 异常检测引擎(实时监控数据流动)
- 影响分析沙箱(隔离测试异常变更)
- 自动回滚机制(0.1秒内阻断错误传播)
- 可视化控制台(全局监控涌现行为)
这些控制措施不是限制涌现,而是引导涌现向预期方向发展,实施后,系统异常处理时间从平均47分钟降至9秒。
工业DevOps的涌现进化
站在2026年的时间节点回望,工业DevOps的发展轨迹清晰展现了涌现理论的威力,从最初的技术工具引入,到流程重构、组织进化,再到数据价值释放,每个阶段都伴随着新的