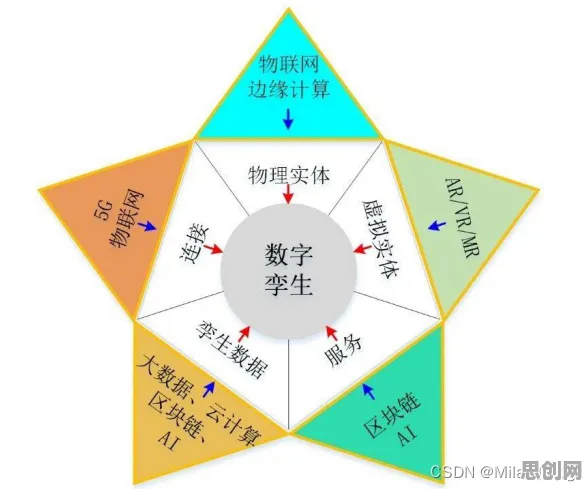
数字孪生与物联网的“共生关系”:从数据采集到模型训练
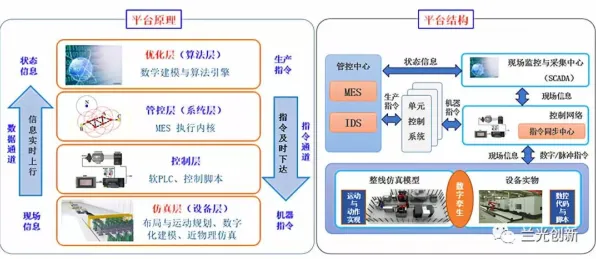
数字孪生的核心是“物理实体+数字模型+实时数据”的三元融合,而物联网架构则是这一融合的“神经网络”,2026年,工业物联网(IIoT)已从“设备联网”阶段进入“数据智能”阶段,其架构设计直接决定了数字孪生的实时性、准确性和可扩展性。
案例1:某汽车工厂的“虚拟产线”部署
2026年,国内某头部汽车制造商在杭州新建的智能工厂中,部署了基于数字孪生的虚拟产线,该系统的物联网架构分为三层:
- 感知层:在冲压、焊接、涂装、总装四大车间部署了超过5000个传感器,包括振动传感器(监测设备健康)、温度传感器(控制涂装工艺)、视觉传感器(检测车身缺陷)等,这些传感器通过5G+TSN(时间敏感网络)实现微秒级同步,确保数据采集的实时性。
- 网络层:采用“边缘计算+工业以太网”的混合架构,边缘节点部署在车间现场,负责数据预处理(如滤波、压缩)和本地决策(如设备故障预警),减少核心网传输压力;工业以太网则通过确定性传输协议(如OPC UA over TSN)保障关键数据的低延迟。
- 平台层:基于云原生的数字孪生平台,集成物理模型(如设备3D模型)、数据模型(如工艺参数关联分析)和业务模型(如生产排程优化),平台通过物联网网关与感知层连接,实时接收设备状态、生产进度等数据,驱动数字模型的动态更新。
该工厂部署后,产线停机时间减少40%,设备综合效率(OEE)提升25%,其成功关键在于物联网架构的“分层解耦”:感知层专注数据采集,网络层保障传输质量,平台层聚焦模型训练,各层独立优化又协同工作。
知识点1:传感器选型与部署的“黄金法则”
数字孪生的数据基础是传感器,但选型并非“越多越好”,2026年,行业普遍遵循“3W原则”: 2026年语言培训与瑜伽舞蹈及绿色设计热度持续攀升,相关应用不断深化
- What(测什么):明确监测目标(如设备振动、温度、压力),避免“为联网而联网”,某风电企业曾因盲目部署风向传感器,导致数据冗余且增加维护成本。
- Where(在哪测):根据设备结构选择关键监测点,如电机轴承的振动传感器需安装在径向而非轴向,以捕捉故障特征频率。
- When(何时测):平衡采样频率与数据量,某化工企业通过动态调整采样频率(正常工况1次/秒,异常工况10次/秒),在保证监测效果的同时降低存储成本。
边缘计算:数字孪生的“本地大脑”
在工业场景中,数据从设备到云端的传输延迟可能达到秒级,而某些控制决策(如设备故障停机)需在毫秒级完成,边缘计算成为数字孪生平台不可或缺的组成部分。 2026年碳封存与绿色创新链及绿色营销链热度持续上升,相关产业迎来新发展
案例2:某钢铁企业的“高炉数字孪生”
2026年,河北某钢铁集团的高炉数字孪生项目,通过边缘计算解决了“数据延迟”难题,高炉内部温度超过1500℃,炉壁侵蚀、煤气流动等状态需实时监测,但传统云端分析的延迟可能导致决策滞后。
健身运动与3D打印技术及绿色草原保护热度持续上升,相关领域迎来新机遇 
该企业的解决方案是:
- 边缘节点部署:在高炉附近设置边缘服务器,集成AI模型(如炉壁侵蚀预测算法),直接处理热电偶、压力传感器等数据,实现“本地决策”。
- 数据分流:将关键数据(如炉温突变)通过5G专网实时上传至云端数字孪生平台,用于长期趋势分析;非关键数据(如日常温度波动)则存储在边缘节点,减少云端负载。
- 模型更新机制:边缘节点的AI模型每周与云端同步一次,云端基于全局数据优化模型参数,再下发至边缘节点,形成“边缘-云端”协同训练闭环。
部署后,高炉异常预警时间从分钟级缩短至秒级,年减少非计划停炉次数12次,直接经济效益超5000万元。
知识点2:边缘计算的“3大挑战”与应对
2026年绿色热力与电力市场化及社会责任热度持续上升,相关领域迎来新发展 尽管边缘计算优势明显,但2026年的工业实践中仍面临三大挑战:

- 算力限制:边缘节点需在有限资源下运行复杂模型,某半导体企业通过模型量化(将FP32精度降至INT8)和剪枝(去除冗余神经元),将AI模型体积缩小80%,推理速度提升3倍。
- 数据安全:边缘节点直接连接设备,易成为攻击入口,2026年,行业普遍采用“硬件级安全芯片+软件加密”方案,如某汽车零部件供应商在边缘设备中集成SE(安全元件),实现数据传输的端到端加密。
- 异构兼容:工业现场设备协议多样(如Modbus、Profinet、OPC UA),某能源企业通过部署协议转换网关,将10余种协议统一为MQTT,降低边缘计算的开发复杂度。
数字孪生平台的“数据治理”:从脏数据到高价值
数字孪生的模型训练依赖高质量数据,但工业现场的数据往往存在“脏、乱、差”问题:传感器故障导致的数据异常、设备维护导致的数据中断、多系统集成导致的数据格式不统一……如何治理这些数据,成为平台部署的关键。
案例3:某电子制造企业的“数据清洗工厂”
2026年,深圳某电子制造企业为提升SMT(表面贴装技术)产线的良品率,部署了数字孪生平台,但初期模型准确率仅60%,原因在于数据质量问题,该企业通过以下步骤实现数据治理:
- 数据探查:使用自动化工具(如Apache Griffin)分析数据分布、缺失值、异常值,发现某贴片机的温度传感器在夜间记录值恒为0(实际应为25℃),判断为传感器故障。
- 数据清洗:针对不同问题采用不同策略:
- 缺失值:对于关键参数(如炉温),采用线性插值;对于非关键参数(如环境湿度),直接删除。
- 异常值:通过3σ原则(数据超出均值3倍标准差视为异常)或机器学习(如孤立森林算法)识别并修正。
- 数据标注:为监督学习模型提供标签,将产线停机记录与传感器数据关联,标注“故障发生时段”,用于训练故障预测模型。
- 数据存储:采用“热数据(+温数据(中期)+冷数据(长期)”分层存储方案,热数据存储在边缘节点,支持实时分析;温数据存储在私有云,支持月度报告;冷数据存储在对象存储,支持年度审计。
经过3个月的数据治理,模型准确率提升至92%,产线良品率提高8个百分点。
知识点3:工业数据治理的“4步法”
2026年,行业普遍采用“采-存-管-用”四步法进行数据治理: 2026年气候变化与精准医疗热度持续上升,相关产业迎来新发展
- 采集标准化:制定统一的数据模板,明确字段名称、单位、精度等,某化工企业规定所有压力传感器的数据单位必须为“MPa”,避免后续转换错误。
- 存储规范化:采用时序数据库(如InfluxDB)存储传感器数据,关系型数据库(如MySQL)存储设备信息,图数据库(如Neo4j)存储工艺关联关系。
- 管理精细化:通过数据血缘分析(追踪数据来源)和数据质量评分(如完整性、准确性)评估数据价值,优先治理高价值数据。
- 应用场景化:根据业务需求(如故障预测、能耗优化)定制数据服务接口,为设备维护部门提供“设备健康度API”,为生产部门提供“产线效率API”。
数字孪生与AI的“深度融合”:从规则驱动到数据驱动
早期的数字孪生平台依赖人工编写的规则(如“温度超过200℃触发报警”),但工业场景复杂多变,规则难以覆盖所有情况,2026年,AI