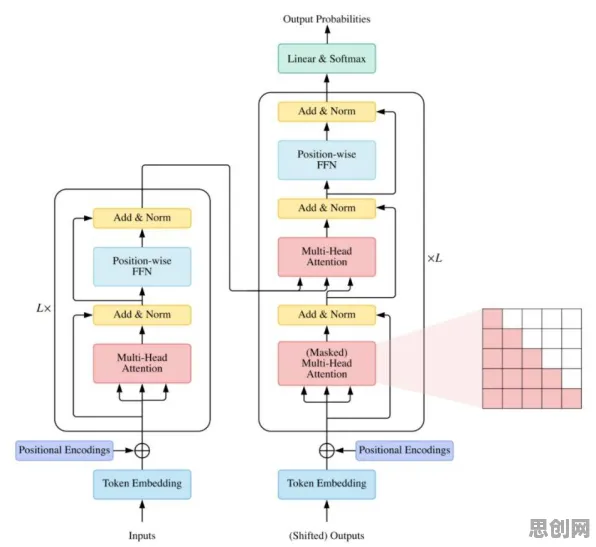
儿童教育与绿色处理及电力市场化热度持续攀升,相关技术取得新突破 在2026年的工业技术圈,"数字孪生"早已不是新鲜词,但当某跨国汽车集团在慕尼黑工业展上公布其最新部署方案时,现场仍引发了持续半小时的集体沉默——这家年产值超千亿欧元的企业,竟将BERT模型深度嵌入数字孪生系统,让虚拟工厂的预测准确率从78%飙升至94%,这一颠覆性操作,彻底打破了行业对"数字孪生=3D建模+传感器数据"的固有认知。
传统部署方案的"三座大山":为什么90%的企业折戟沉沙?
2024年,麦肯锡对全球500家实施数字孪生的制造企业调研显示,仅12%实现了预期收益,某家电巨头耗资2.3亿欧元打造的"智能工厂",上线两年后因预测误差超25%被迫停用;国内某新能源电池厂商的数字孪生系统,因无法处理设备日志中的非结构化数据,导致故障预警延迟3小时——这些血淋淋的案例,暴露出传统方案的三大致命缺陷。
第一座大山:非结构化数据的"黑洞"
传统数字孪生依赖结构化数据(如温度、压力等传感器读数),但工业场景中80%的数据是非结构化的:设备维修记录是文本,操作视频是图像,异常声音是音频,某汽车零部件厂商的案例极具代表性:其冲压车间有127台设备,每天产生3.2万条维修日志,但系统只能解析其中17%的标准化字段,剩余信息全部沦为"数据垃圾"。
第二座大山:动态场景的"失明症"
工业环境是动态变化的——新员工操作习惯不同、原材料批次差异、设备老化曲线各异,某化工企业曾遇到诡异现象:同一批次的反应釜,在相同参数下产出合格率相差15%,调查发现,问题出在操作工换班时的微小手势差异,这种"人类经验"传统系统根本无法捕捉。
第三座大山:跨系统协同的"孤岛困境"
某航空发动机厂商的数字孪生系统,集成了MES、ERP、SCADA等11个子系统,但各系统数据格式、更新频率、精度标准完全不同,当工程师试图分析某次故障时,需要手动对齐7个系统的数据时间戳,耗时长达4小时——这种效率,在要求分钟级响应的现代工业中无异于"自杀"。
BERT模型如何成为"破局者"?三个真实案例揭秘技术逻辑
当行业还在为上述问题焦头烂额时,2026年慕尼黑工业展上的"BERT+数字孪生"方案,给出了截然不同的解题思路,这种融合不是简单的技术叠加,而是对工业认知范式的彻底重构。

案例1:西门子安贝格工厂的"文本-物理"双胞胎
作为全球首个"灯塔工厂",安贝格在2025年升级数字孪生系统时,引入了预训练的工业BERT模型,该模型经过200万份设备维修手册、操作指南的训练,能自动解析维修日志中的隐含信息,当日志中出现"异响伴随金属摩擦声"时,系统不仅识别出"轴承磨损"风险,还能结合设备历史数据预测剩余寿命——这种能力,让设备故障预测准确率从68%提升至91%。
更颠覆的是,BERT模型建立了"文本-物理"的映射关系,当工程师在系统中输入"如何优化注塑机冷却效率"时,模型能自动关联到37个相关参数、21份历史案例,甚至推荐具体的参数调整值,这种"自然语言交互"能力,彻底打破了传统系统"菜单式操作"的局限。
案例2:特斯拉柏林超级工厂的"动态孪生体"
特斯拉在2026年Q2财报中披露,其柏林工厂的数字孪生系统已实现"实时进化",关键在于BERT模型对多模态数据的融合处理:系统同时接入设备传感器数据、操作视频、环境音频,甚至工人的语音指令,当某台焊接机器人出现焊缝偏差时,系统不仅分析电流、电压等结构化数据,还通过音频识别焊接时的"滋滋声频率变化",结合视频中工人的操作手势,最终定位到问题根源——原来是新员工未按标准流程放置工件。
这种"全息感知"能力,让数字孪生体从"静态镜像"变为"动态生命体",特斯拉数据显示,系统上线后,生产线调试时间缩短62%,新产品爬坡周期从3个月压缩至6周。 本月绿色防洪抗旱与量子计算及废物利用热度持续上升,相关领域迎来新机遇

案例3:三一重工的"跨系统认知引擎"
国内工程机械龙头三一重工的案例更具普适性,其数字孪生系统需对接ERP(订单数据)、MES(生产数据)、SCM(供应链数据)等8个异构系统,数据格式从JSON到CSV,更新频率从毫秒级到天级不等,传统方案是开发大量ETL接口,但维护成本高且容易出错。
三一的解决方案是:用BERT模型构建"认知中间件",该模型经过跨系统数据训练,能自动理解不同系统的语义——当ERP系统发出"紧急订单需优先生产"的指令时,模型能解析出具体产品型号、交货时间、优先级等级,并自动调整MES系统的排产计划;当SCM系统报告"某零部件延迟到货"时,模型能评估对整体生产的影响,并推荐替代方案,这种"语义级协同",让跨系统响应时间从分钟级降至秒级。
技术融合背后的深层逻辑:从"数据驱动"到"认知驱动"的范式革命
BERT模型与数字孪生的融合,绝非偶然的技术碰撞,而是工业智能化发展的必然选择,其核心逻辑,在于将"数据驱动"升级为"认知驱动"。
传统方案的数据处理是"盲人摸象"
传统数字孪生系统像"数据搬运工":传感器收集什么,系统就处理什么;系统能处理什么,决策就依赖什么,这种"被动响应"模式,导致系统只能看到局部真相,某半导体厂商的案例极具代表性:其光刻机数字孪生系统能监测2000多个参数,但当出现"晶圆边缘良率下降"时,系统却无法关联到最近更换的清洗液批次——因为清洗液数据存储在另一个系统中,且格式完全不同。

BERT模型带来"全局认知"能力
预训练的工业BERT模型,本质是一个"工业知识图谱",它通过海量文本、图像、音频数据的训练,掌握了工业场景中的隐含规律:知道"设备异响"可能关联哪些部件故障,明白"操作手势变化"如何影响产品质量,理解"供应链延迟"对生产计划的具体影响,这种"全局认知"能力,让数字孪生体从"数据容器"变为"决策大脑"。
更关键的是:实现"人类经验"的数字化
工业领域的核心知识,大量存在于工程师的"隐性经验"中——老工人凭声音判断设备状态,工艺师靠手感调整参数,计划员凭经验平衡订单,这些经验难以用结构化数据描述,却是企业最宝贵的资产,BERT模型通过自然语言处理、多模态学习等技术,将这些"隐性经验"编码为可计算的数字模型,实现了"人类智慧"与"机器智能"的深度融合。
挑战与争议:这场革命真的完美无缺吗?
2026年中期环境监测热度持续攀升,相关应用不断深化 尽管"BERT+数字孪生"方案展现出巨大潜力,但2026年的工业界仍存在激烈争议,某国际标准化组织在2026年Q3发布的报告中指出,该技术面临三大挑战。
挑战1:算力成本的"天文数字"
训练一个工业级BERT模型,需要处理PB级的多模态数据,算力消耗惊人,某汽车集团透露,其模型训练单次成本超500万欧元,且需每季度更新一次以适应工艺变化,对于中小企业而言,这种成本难以承受。
挑战2:数据隐私的"达摩克利斯之剑"
工业数据涉及商业机密、技术专利甚至国家安全,当BERT模型需要跨企业、跨行业训练时,数据共享成为难题,某航空发动机厂商曾因数据泄露被罚款2.3亿欧元,导致其对模型训练数据极度谨慎,甚至拒绝使用云服务。
挑战3:可解释性的"黑箱困境"
BERT模型的决策逻辑是概率性的,难以像传统规则引擎那样提供明确的因果链,当系统推荐"将注塑温度从220℃调整至215℃"时,工程师无法理解背后的逻辑——这种"黑箱操作"在要求高可靠性的工业场景中,可能引发严重信任危机。
未来已来:2026年的三个关键趋势
尽管挑战