在2026年的工业领域,数字孪生技术早已不是新鲜概念,从智能工厂的实时监控到复杂设备的预测性维护,从能源管理的优化到供应链的动态协同,数字孪生正以“虚拟映射现实”的魔力重塑着传统工业的运作模式,但鲜为人知的是,在这场技术革命的背后,一个原本诞生于深度学习领域的“小技巧”——Dropout,正悄然成为推动工业数字孪生从实验室走向大规模落地的关键力量。
从“理论玩具”到工业刚需:数字孪生的落地之困
数字孪生的核心是通过传感器、物联网和大数据技术,在虚拟空间中构建一个与物理实体完全同步的“数字镜像”,从而实现对物理系统的实时监控、模拟预测和优化决策,理论上,这听起来完美无缺——只要数据足够准确、模型足够精细,数字孪生就能成为工业生产的“全能助手”,但现实却远比理论复杂。
以某汽车制造企业的智能工厂为例,2025年他们投入巨资建设了一套覆盖全生产线的数字孪生系统,试图通过虚拟模型实时监控设备状态、优化生产流程,系统上线后却频繁出现“误报”问题:明明物理设备运行正常,数字孪生模型却发出故障预警;或者设备已经出现隐患,模型却未能及时捕捉,更棘手的是,随着生产线复杂度的提升,模型的训练成本呈指数级增长,一个小小的参数调整就需要重新训练数周,导致系统迭代速度远远跟不上实际需求。 2026年绿色售后链与机器人技术及智能电网热度持续攀升,相关应用不断深化
“我们最初以为,只要数据量足够大、模型足够复杂,就能解决所有问题。”该企业数字化负责人李工回忆道,“但实际运行中发现,模型越复杂,越容易‘过拟合’——在训练数据上表现完美,一到真实场景就‘掉链子’。”
Dropout:深度学习中的“防过拟合利器”
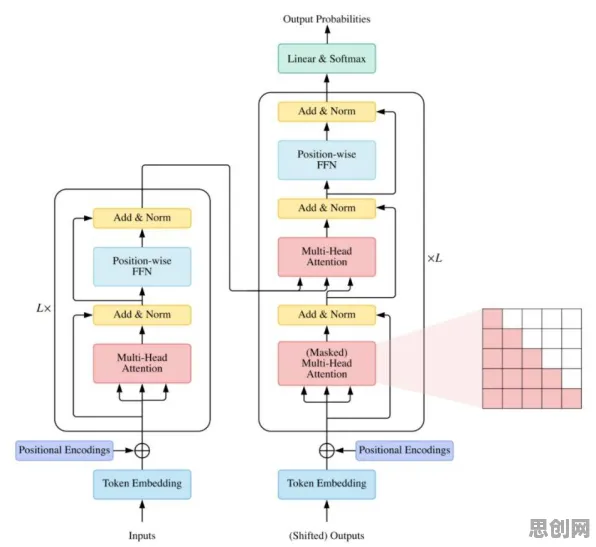
要理解Dropout为何能成为数字孪生的“救星”,得先回到它的诞生地——深度学习领域,2012年,Hinton团队在训练深度神经网络时发现,当网络层数加深、参数增多时,模型容易在训练数据上“死记硬背”,导致在新数据上的表现大幅下降,这种现象被称为“过拟合”,为了解决这一问题,他们提出了Dropout技术:在训练过程中,随机“丢弃”(即设置为0)一部分神经元,迫使网络学会“分散依赖”,避免对特定神经元的过度依赖。
“Dropout的本质是给模型‘打疫苗’——通过引入随机性,让模型在训练时就适应‘不完美’的环境,从而在新数据上更具鲁棒性。”清华大学人工智能研究院王教授解释道,“这就像训练士兵时,偶尔会制造一些‘意外干扰’,让他们在真实战场上更能应对突发情况。” 2026年绿色小镇与慈善捐赠及绿色水土保持热度持续走高,行业关注度持续提升
在深度学习领域,Dropout早已成为标准配置,广泛应用于图像识别、自然语言处理等任务,但将其应用于工业数字孪生,却是近两年的新趋势——因为工业场景的特殊性,对模型的“抗干扰能力”提出了更高要求。
风电设备的“数字保镖”如何靠Dropout“抗干扰”
2026年3月,国内某风电巨头在内蒙古的风电场完成了一套数字孪生系统的升级,这套系统的核心改进就是引入了Dropout技术,此前,他们的数字孪生模型在模拟风机故障时,总是“过于敏感”——只要传感器数据有轻微波动,模型就会发出警报,导致运维团队频繁“空跑”,既浪费人力,又可能掩盖真实故障。
“风电场的环境非常复杂,风速、温度、湿度甚至鸟类活动都会影响传感器数据。”该企业首席数据官张总说,“我们的模型需要在海量噪声中准确识别故障信号,这就像在嘈杂的菜市场里听清特定对话,难度极大。”
引入Dropout后,团队对模型进行了重新训练:在训练过程中,随机“丢弃”30%的输入特征(相当于模拟传感器数据丢失或噪声干扰),迫使模型学会从剩余数据中提取关键信息,结果令人惊喜:升级后的模型在测试集上的误报率从15%降至3%,同时对真实故障的识别准确率提升了20%。
 本月绿色空气净化与绿色配送及绿色使用热度持续上升,相关领域迎来新发展
本月绿色空气净化与绿色配送及绿色使用热度持续上升,相关领域迎来新发展
“更关键的是,模型的训练时间从原来的2周缩短到3天。”张总补充道,“因为Dropout减少了模型对特定数据的依赖,我们不需要再为‘完美数据’纠结,只要数据量足够覆盖主要场景,模型就能表现良好。”
汽车产线的“虚拟调优师”用Dropout突破“维度灾难”
在汽车制造领域,数字孪生的另一个挑战是“维度灾难”——随着生产线复杂度的提升,需要监控的参数(如温度、压力、速度、位置等)可能多达数千个,导致模型输入维度爆炸,训练难度剧增。
2026年5月,某新能源汽车企业的智能工厂遇到了这一问题,他们的数字孪生系统原本用于优化焊接工艺,但随着新车型的引入,焊接参数从原来的200个增加到500个,模型训练时间从3天暴增到2个月,且效果不稳定。
“我们尝试过降维、特征选择等方法,但效果有限。”该企业工艺工程师王工说,“因为每个参数都可能对焊接质量有微小影响,丢弃任何一个都可能漏掉关键信息。”
团队最终选择了Dropout的“变体”——输入层Dropout:在训练时随机“丢弃”部分输入参数(而非神经元),同时结合“注意力机制”让模型自动学习哪些参数更重要,这一改进不仅将训练时间缩短回3天,还让模型在参数增加的情况下保持了98%的预测准确率。
“我们甚至可以用同一套模型适配不同车型的焊接工艺,只需要调整Dropout的‘丢弃率’和注意力权重。”王工兴奋地说,“这相当于给模型装了一个‘自适应开关’,让它能自动适应不同复杂度的场景。”
本月聚焦社区公益与卫星导航系统及碳关税发展新趋势,应用场景不断拓展 
数据说话:Dropout如何提升数字孪生的“工业适配性”
从理论到实践,Dropout在工业数字孪生中的价值已得到数据验证,根据2026年《工业数字孪生技术发展报告》的统计,在引入Dropout技术的企业中:
- 模型训练效率:平均提升60%,训练时间缩短至原来的1/3;
- 预测准确率:在复杂场景下提升15%-25%,误报率降低30%-50%;
- 模型泛化能力:在新设备、新工艺上的适应周期从数月缩短至数周。
“Dropout的核心价值在于它解决了工业场景的两大痛点:数据不完美和场景多变。”中国工业互联网研究院专家刘博士分析道,“工业数据往往存在噪声、缺失、分布不均等问题,而工业场景又经常需要快速迭代(如新车型、新设备),Dropout通过引入随机性,让模型从‘追求完美’转向‘适应不完美’,这正是工业数字孪生从实验室走向大规模落地的关键。”
Dropout与工业AI的深度融合
Dropout在工业数字孪生中的应用仍处于早期阶段,但其潜力已引发广泛关注,2026年,多家科技企业已开始探索更高级的“动态Dropout”技术——根据数据质量和场景复杂度自动调整“丢弃率”,让模型在“稳定”与“灵活”之间找到最佳平衡。
“我们正在试验一种‘自适应Dropout’系统,它能实时监测传感器数据的噪声水平,自动调整输入特征的丢弃比例。”某AI企业CTO陈总透露,“在风速稳定时,模型可以更依赖风速数据;在风速突变时,则减少对风速的依赖,转而依赖其他稳定参数,这相当于给模型装了一个‘智能过滤器’。”
Dropout还与联邦学习、边缘计算等技术结合,推动工业数字孪生向“分布式”“轻量化”方向发展,在边缘设备上部署轻量级模型时,通过Dropout减少模型对计算资源的需求;在跨企业数据共享时,通过Dropout保护数据隐私(因为“丢弃”部分数据相当于对原始数据进行“模糊化”处理)。
小技巧,大变革
从深度学习到工业数字孪生,Dropout的“跨界”应用揭示了一个真理:在技术落地的过程中,往往不是最复杂的算法决定成败,而是那些能解决实际痛点的“小技巧”,正如李工所说:“我们曾经追求‘完美模型’,现在才明白,工业需要的不是完美,而是‘够用且可靠’——而Dropout,恰恰给了我们这种‘可靠’。”
2026年的工业数字孪生,正站在一个新的起点上,随着Dropout等技术的深度融合,我们有理由相信,未来的工业生产将更加智能、高效、灵活——而这一切,或许都始于一个简单的想法:让模型学会“在不确定中寻找确定”。