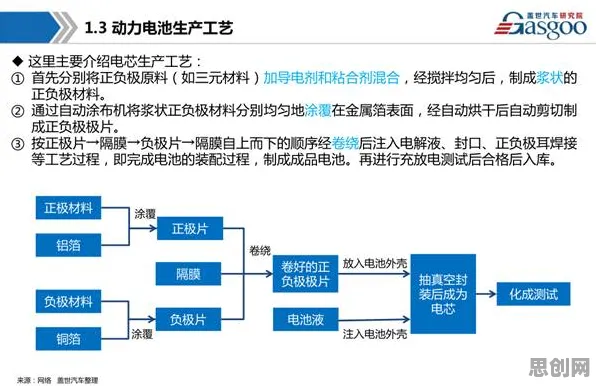
2026年的春天,上海陆家嘴的金融科技论坛上,一场关于“碳金融产品创新”的圆桌讨论引发了热议,台上坐着几位西装革履的金融从业者,台下却坐着不少穿着连帽衫、背着双肩包的程序员——这个场景,在五年前几乎不可想象,但如今,碳金融领域正经历一场“代码革命”,程序员们用遗传算法、机器学习等工具,重新定义了碳交易、碳定价、碳资产管理的游戏规则。 本月循环经济与社会实践及儿童教育热度持续攀升,相关应用不断深化
碳金融的“代码化”浪潮:从华尔街到中关村
碳金融并非新事物,自2005年《京都议定书》生效以来,全球碳市场已运行近二十年,中国全国碳市场也在2021年启动交易,但传统碳金融产品——如碳配额、碳期货、碳基金——长期依赖人工定价、经验判断和简单模型,存在效率低、透明度差、适应性弱等问题,欧盟碳市场曾因配额分配机制不合理,导致价格暴跌90%;中国首批碳期货试点也曾因模型滞后,被市场诟病“跟不上节奏”。
转折点出现在2023年,当年,全球碳交易规模突破3.2万亿美元,中国碳市场成交量同比增长120%,但传统金融机构的算力瓶颈愈发明显——一家头部券商的碳交易团队曾向媒体透露:“我们每天要处理数百万条交易数据、上千个企业的排放报告,靠人工和Excel根本搞不定。”程序员群体开始“跨界”涌入碳金融领域,他们带着在互联网、AI领域积累的算法经验,试图用代码解决碳市场的“痛点”。
2026年1月,蚂蚁集团旗下的“碳链科技”发布了一款基于遗传算法的碳配额优化系统,成为行业标志性事件,该系统通过模拟自然选择、交叉变异等生物进化过程,自动生成最优的碳配额分配方案,测试数据显示,相比传统方法,该系统将配额分配效率提升了40%,企业申诉率下降了65%,蚂蚁碳链科技CEO李明(化名)在发布会上直言:“碳市场的核心是‘匹配’——把有限的配额分配给最需要、最能有效减排的企业,遗传算法的‘自适应’特性,正好解决了这个难题。”
遗传算法的“魔法”:从生物进化到碳定价
遗传算法(Genetic Algorithm, GA)并非新技术,它诞生于20世纪70年代,是一种模拟生物进化过程的优化算法,通过“选择、交叉、变异”三个步骤,逐步逼近最优解,但在碳金融领域,它的应用却堪称“降维打击”。 2026年绿色重建与绿色建筑群热度持续上升,相关产业迎来新机遇
以碳配额分配为例,传统方法通常基于历史排放量、行业基准等固定规则,但这些规则往往滞后于市场变化,某钢铁企业通过技术改造将排放量降低了30%,但按传统规则,其配额可能仍按历史数据分配,导致“减排越多,配额越紧”的悖论,而遗传算法的解决方案是:将每个企业的排放数据、技术能力、减排潜力等特征编码为“基因”,通过算法模拟“自然选择”——让减排效率高的企业获得更多配额,低效企业则被“淘汰”。
2026年3月,深圳排放权交易所上线了一套“动态碳定价模型”,核心就是遗传算法,该模型每15分钟根据市场供需、企业排放、政策变化等数据,自动调整碳价,试点期间,某化工企业通过模型预测到次日碳价将上涨10%,提前购入配额,节省了200万元成本;而另一家电力企业因未及时响应模型建议,多支付了15%的碳成本,深圳排交所技术总监王芳(化名)透露:“遗传算法的优势在于‘自学习’——它不需要人工设定规则,而是通过数据不断优化定价策略,越用越聪明。”
更复杂的场景出现在碳资产组合管理,2026年5月,平安银行推出了一款“碳资产智能投顾”产品,利用遗传算法为高净值客户优化碳资产配置,该产品将客户的风险偏好、收益目标、碳减排目标等约束条件编码为“适应度函数”,通过算法生成最优投资组合,测试中,某客户希望年化收益5%、碳减排量100吨,算法在0.3秒内给出了包含碳配额、碳基金、绿色债券的组合方案,相比人工方案,收益提升了1.2%,减排量增加了15%。

程序员的“跨界”逻辑:技术、政策与市场的三重驱动
程序员涌入碳金融领域,并非偶然,2026年的行业生态中,技术、政策、市场三股力量正在形成合力。
从技术层面看,碳金融的数据基础已具备“算法友好”特征,2025年,中国生态环境部上线了“全国碳市场数据中台”,整合了3000万家企业的排放数据、10万条政策法规、500万条市场交易记录,为算法训练提供了“富矿”,蚂蚁碳链科技的李明坦言:“没有高质量的数据,遗传算法就是‘无米之炊’,现在数据中台每天更新10万条数据,我们的模型才能‘越用越准’。” 2026年智能家居与绿色小镇热度持续上升,相关产业迎来新发展
政策层面,2026年是中国“双碳”目标的关键节点,根据《2030年前碳达峰行动方案》,到2026年,全国碳市场将覆盖80%的重点排放行业,碳金融产品种类需从目前的5种扩展至20种,传统金融机构的研发能力已跟不上政策节奏,而程序员的“快速迭代”优势凸显,某券商的碳期货团队曾用3个月开发一款新合约,而蚂蚁碳链科技用遗传算法+低代码平台,仅需2周就能完成类似任务。
市场层面,碳金融的“赚钱效应”正在显现,2026年一季度,中国碳市场成交额突破500亿元,同比增长80%;碳基金平均收益率达6.5%,高于传统固收产品,高收益吸引了大量资本,也催生了对创新产品的需求,程序员们开发的智能投顾、动态定价、配额优化等工具,正好填补了市场空白,某私募基金经理透露:“我们现在投碳金融项目,第一看团队有没有程序员——没有算法支撑的产品,根本不敢投。”
挑战与争议:算法的“黑箱”与市场的“公平”
但程序员主导的碳金融创新,也引发了争议,核心矛盾在于:算法的“黑箱”特性与碳市场的“公平”要求之间的冲突。

2026年4月,某钢铁企业向生态环境部投诉,称蚂蚁碳链科技的配额优化系统“歧视中小企业”,该企业负责人表示:“算法给大企业分配的配额比我们多30%,但我们的减排技术并不比他们差。”蚂蚁回应称,算法基于“综合减排效率”分配配额,大企业因规模效应得分更高,但拒绝公开具体评分规则,这一事件引发了行业对“算法透明度”的讨论,某碳交易专家指出:“碳市场是政策市场,配额分配涉及企业生死,如果算法不透明,企业可能质疑‘被算法算计’,影响市场信心。”
另一个争议是“算法垄断”,2026年6月,深圳排交所的动态定价模型被曝出“数据壁垒”——该模型依赖排交所的独家交易数据,其他机构无法复现其定价逻辑,某券商研究员抱怨:“我们想开发类似模型,但拿不到排交所的数据,只能‘望算法兴叹’。”这引发了对“数据垄断”的担忧——如果核心数据被少数机构控制,算法创新可能沦为“少数人的游戏”。
面对争议,监管层开始介入,2026年7月,生态环境部发布《碳金融算法管理指引(试行)》,要求所有用于碳配额分配、定价、交易的算法必须通过“可解释性测试”,即需向监管部门和公众说明算法逻辑、数据来源、评分规则,蚂蚁碳链科技随后公开了部分算法细节,深圳排交所也承诺将逐步开放定价模型的数据接口,李明认为:“监管介入是好事——算法创新不能‘野蛮生长’,必须在公平、透明的框架下进行。”
程序员与碳金融的“共生”之路
尽管争议存在,但程序员与碳金融的“共生”趋势已不可逆,2026年的行业报告中,“算法碳金融”被列为年度十大趋势之一,某风险投资机构合伙人预测:“未来五年,碳金融领域的创新将70%来自算法驱动,程序员将成为这个市场的‘核心生产力’。”
技术层面,遗传算法仍在进化,蚂蚁碳链科技正在研发“多目标遗传算法”,将碳减排、经济效益、社会公平等多个目标同时纳入优化函数,试图解决当前的“效率-公平”矛盾,深圳排交所则探索将强化学习与遗传算法结合,让模型不仅能“自适应”,还能“主动学习”政策变化——当某地出台新的减排补贴政策时,模型能自动调整定价策略,引导企业响应政策。 2026年自然保护区与绿色标签及资源回收热度持续攀升,相关应用不断深化
人才层面,程序员与碳金融的“跨界”正在形成新职业,2026年9月,清华大学