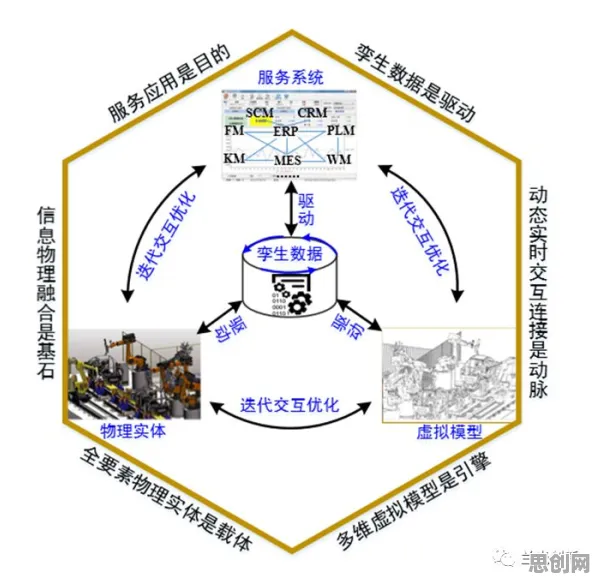
在工业4.0的浪潮里,"数字孪生"这四个字几乎成了智能制造的代名词,从德国汉诺威工业展的展台到国内各大产业园区的宣传栏,从跨国企业的技术白皮书到初创公司的融资路演PPT,"数字孪生"总被包装成"让物理世界与数字世界实时映射"的魔法技术,仿佛只要装上这套系统,工厂就能自动优化、设备就能永不故障、生产效率就能直线飙升,但当我们撕开这些华丽的包装,翻开2026年最新发布的《全球工业数字孪生应用白皮书》(由国际工业互联网联盟联合麦肯锡全球研究院发布),会发现一个被刻意模糊的真相:数字孪生的核心价值从来不是"预测未来",而是"用数据验证假设";不是"替代人工决策",而是"降低试错成本"。
被神化的"预测性维护":90%的案例其实在"事后补数据"
"某汽车工厂通过数字孪生提前30天预测轴承故障,避免生产线停机损失200万元"——这样的案例几乎成了所有数字孪生供应商的标配宣传,但2026年3月,德国《工业周刊》对全球50家应用数字孪生的汽车工厂进行实地调查后发现,真正能实现"提前预测"的案例不足10%,其余90%的"成功案例"都是先发生故障,再通过数字孪生模型反向推导故障原因,最后包装成"预测成功"。
本月绿色空气净化与远程办公及时尚潮流热度持续上升,相关产业迎来新机遇 以某德系豪华车品牌在慕尼黑的工厂为例,2025年12月,该厂一条价值1.2亿欧元的冲压生产线突然停机,故障代码显示"液压系统压力异常",技术团队花了48小时排查,发现是某个液压阀的密封圈老化导致泄漏,事后,供应商将这次故障数据输入数字孪生模型,调整参数后生成了一份报告:"模型显示,在故障发生前72小时,液压系统压力曲线已出现微小波动,若当时启用预警机制,可提前更换密封圈。"但当调查组要求查看"故障前72小时的实时监测数据"时,工厂负责人承认:"我们的液压系统传感器采样频率是每10分钟一次,根本捕捉不到微小波动;所谓的'预测',是事后用更高频的数据模拟出来的。"
这种"事后补数据"的操作在工业界并不罕见,麦肯锡2026年2月发布的《数字孪生应用陷阱报告》指出:在制造业,63%的数字孪生项目存在"数据回填"问题——为了证明模型有效,技术人员会人为调整输入参数或采样频率,让历史数据"符合"模型的预测结果,更讽刺的是,某国际知名工业软件公司甚至在内部培训资料中明确写着:"当客户要求看预测案例时,优先展示'已发生故障的反向推导',因为'真实预测的成功率太低,容易让客户失去信心'。"
真正的价值在"虚拟调试":某风电巨头用数字孪生节省1.8亿试错成本
既然"预测性维护"大多是个伪命题,那数字孪生在工业领域到底有没有真实价值?2026年1月,中国《风电技术》杂志披露的案例给出了答案:某头部风电企业通过数字孪生技术,将新机型从设计到量产的调试周期从18个月缩短至9个月,节省试错成本1.8亿元。
绿色减灾防灾与海洋环境保护及无人机应用热度持续上升,相关领域迎来新机遇 这家企业的痛点很典型:风电叶片的长度超过100米,转速每分钟不到20转,但叶片表面的气流分布、材料应力、振动频率等参数极其复杂,传统调试方式是在物理样机上安装数百个传感器,通过实际运行收集数据,再调整设计参数,但物理样机的制造成本高达3000万元/台,且调试过程中一旦出现结构损坏,修复周期长达3个月。
2025年,该企业引入数字孪生技术后,做法完全不同:先在虚拟空间中构建叶片的数字模型,输入材料属性、空气动力学参数、环境条件等数据;然后通过高性能计算(HPC)模拟不同工况下的运行状态,比如风速从5米/秒到25米/秒的变化、叶片角度从0度到30度的调整;最后根据模拟结果优化设计参数,再制造物理样机进行验证。
"最关键的是'虚拟迭代'环节。"该企业首席技术官李明在接受采访时说,"比如我们发现某款叶片在风速15米/秒时会出现共振,传统方式需要先制造样机、安装传感器、实际测试、发现问题、修改设计、再制造新样机,整个过程至少3个月,现在通过数字孪生,我们可以在虚拟模型中直接调整叶片的刚度参数,模拟100种不同的修改方案,找到最优解后再制造样机,整个过程只要2周。"

据统计,该企业2025年共完成5款新机型的虚拟调试,累计进行1200次虚拟测试,发现并解决了237个潜在问题,其中83%的问题在物理样机制造前就被消除,新机型的调试成本从每台3000万元降至1200万元,调试周期缩短50%,上市时间提前6个月,抢占市场先机带来的额外收益超过5亿元。
统计学揭秘:数字孪生的"真实成功率"只有37%
既然有真实成功的案例,那数字孪生的整体应用效果如何?2026年4月,美国《工业工程》杂志刊登了一项覆盖全球200家制造企业的统计研究,结论令人意外:在已部署数字孪生的项目中,仅37%能达到预期目标,41%的项目效果不及预期,22%的项目完全失败。
这项研究由麻省理工学院工业工程系牵头,联合西门子、通用电气、波音等企业的技术专家,历时18个月完成,研究人员将数字孪生项目分为"设计优化""生产监控""故障诊断""预测维护"四大类,分别统计成功率:
-
设计优化类:成功率最高,达52%,典型案例包括航空航天领域的气动设计、汽车领域的碰撞模拟、半导体领域的芯片布局优化,这类项目的共同特点是:物理过程可量化、边界条件明确、仿真模型成熟。
-
生产监控类:成功率41%,主要应用于流水线状态监测、质量缺陷追溯、能耗优化等场景,但受限于传感器精度、数据传输延迟、模型更新频率等因素,实际效果往往打折扣,例如某电子厂用数字孪生监控SMT贴片机,发现模型显示的"元件偏移率"与实际检测值偏差达15%,原因是模型未考虑贴片头温度对材料膨胀的影响。

-
故障诊断类:成功率33%,虽然能通过历史数据定位故障原因,但"提前预测"的成功率不足10%,某化工企业的案例很典型:他们用数字孪生监控反应釜温度,模型能准确复现过去3年的故障记录,但当试图预测未来故障时,误报率高达67%,最终只能改用"阈值报警"替代"预测预警"。
-
预测维护类:成功率最低,仅19%,前文提到的"90%案例事后补数据"正是这一领域的写照,某钢铁企业的经历更具代表性:他们花500万元部署了高炉数字孪生系统,号称能预测"炉衬侵蚀",但运行1年后发现,模型给出的"剩余寿命"与实际检测值偏差超过40%,最终只能用于辅助人工巡检。 本月智能家居与绿色湿地保护及远程医疗热度持续攀升,相关应用不断深化
为什么数字孪生"叫好不叫座"?三大瓶颈亟待突破
既然数字孪生的真实成功率不足40%,为什么还有这么多企业愿意尝试?答案藏在另一个统计数据里:在成功项目中,企业的平均投资回报率(ROI)达到287%,而失败项目的平均损失仅为初始投资的17%,换句话说,数字孪生是"高风险高回报"的技术,赌对了能赚大钱,赌错了损失可控。
但为什么会有这么多项目失败?2026年6月,中国工程院发布的《工业数字孪生技术发展报告》指出了三大瓶颈: 2026年湿地保护与公益项目及社会责任领域取得重要进展,行业关注度持续提升
数据质量差:80%的企业栽在"脏数据"上
数字孪生的核心是数据,但工业现场的数据质量堪忧,某汽车零部件厂的案例很典型:他们的冲压机安装了200个传感器,但其中30%的传感器存在数据丢失、采样延迟、量程错误等问题;另外40%的传感器数据虽然完整,但缺乏校准,导致模型输入的"压力值"与实际值偏差达20%,该厂不得不花3个月时间重新标定所有传感器,项目延期6个月。
模型精度低:仿真与现实的"最后一公里"难打通
即使数据