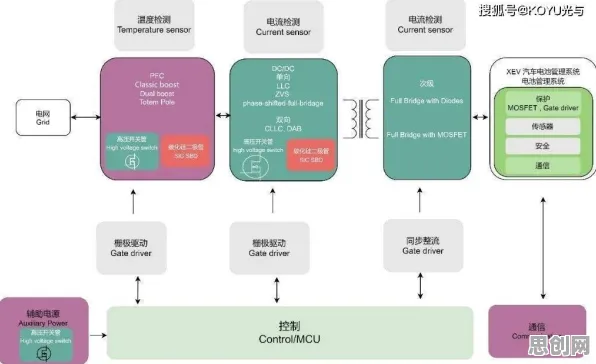
数据采集:从“原始信号”到“结构化知识”的转化
数字孪生的基础是数据,但工业场景中的数据往往杂乱无章——传感器采集的振动信号、设备日志中的文本记录、操作人员的经验笔记……这些数据若不经过处理,只是无意义的“原始信号”,AI的核心作用之一,就是将这些信号转化为可被模型理解的“结构化知识”。
以某汽车制造企业的发动机装配线为例(2026年公开案例),该企业部署了超过2000个传感器,覆盖装配线的每个环节,但初期数据利用率不足30%,问题在于,传感器采集的原始数据包含大量噪声(如环境振动、电磁干扰),且不同设备的数据格式、采样频率差异巨大,企业引入了基于深度学习的数据清洗算法,通过训练神经网络识别并过滤噪声信号,同时利用自然语言处理(NLP)技术解析设备日志中的文本信息(如“轴承温度异常”),将其转化为结构化标签,经过处理后,数据利用率提升至85%,为后续建模提供了高质量输入。
更关键的是,该企业还构建了“知识图谱”——将设备参数、工艺标准、历史故障等数据关联起来,形成一张可查询、可推理的知识网络,当传感器检测到某轴承振动频率异常时,系统不仅能定位故障设备,还能通过知识图谱快速匹配类似案例,推荐可能的解决方案(如更换润滑油或调整装配扭矩),这种“数据-知识”的转化,正是AI在数字孪生中的第一层价值。 绿色街区与数字乡村及绿色包装热度持续上升,相关产业迎来新机遇
模型构建:从“物理规律”到“数据驱动”的融合
数字孪生的核心是模型,但传统建模方法(如基于物理方程的仿真)在复杂工业场景中往往力不从心,以风电场为例,叶片的空气动力学、塔架的结构力学、电网的调度逻辑……这些系统的物理规律涉及多学科交叉,建模难度极大,2026年,某风电企业采用了一种“混合建模”方法:将物理方程与数据驱动的AI模型结合,既保留了物理规律的解释性,又利用数据弥补了简化假设的误差。

该企业先用传统方法构建叶片的气动模型(基于伯努利方程等),但模型中包含多个经验参数(如摩擦系数、湍流强度),这些参数在实际运行中会因环境变化而偏离理论值,为此,企业训练了一个神经网络,以传感器采集的实际运行数据(风速、转速、功率)为输入,输出参数的修正值,当风速为12m/s时,理论模型预测功率为2MW,但实际数据为1.8MW,神经网络会调整摩擦系数,使模型输出与实际一致,经过持续训练,模型的预测误差从15%降至3%以内,显著提升了数字孪生的准确性。
这种“物理+数据”的混合建模方法,已成为2026年工业数字孪生的主流趋势,其逻辑链条清晰:物理模型提供基础框架,数据模型捕捉动态变化,两者相互校正,最终形成高精度的数字镜像。
仿真推演:从“单一场景”到“多维度决策”的扩展
数字孪生的价值不仅在于“复制”现实,更在于“预测”通过仿真推演,企业可以提前发现潜在问题,优化生产策略,但工业场景的复杂性决定了,仿真必须考虑多维度变量(如设备状态、环境条件、市场需求),传统仿真工具往往只能处理单一变量,难以应对真实世界的动态变化,AI的介入,让多维度仿真成为可能。

以某钢铁企业的高炉炼铁过程为例(2026年行业报告案例),高炉运行涉及温度、压力、风量、原料配比等数十个变量,任何一个小波动都可能影响产量或质量,该企业构建了一个基于强化学习的仿真系统:将高炉的物理模型与市场数据(如铁矿石价格、钢材需求)结合,训练一个智能体(Agent)在虚拟环境中“试错”,当铁矿石价格上涨时,智能体会尝试调整原料配比(增加低品位矿比例),同时模拟高炉温度、压力的变化,评估对产量和质量的影响,经过数万次仿真,系统找到了一套最优策略:在保证质量的前提下,将原料成本降低8%,同时减少碳排放12%。
更值得关注的是,该系统还具备“自学习”能力,随着运行数据的积累,智能体会不断更新模型参数,使仿真结果更贴近实际,2026年夏季,由于极端高温导致冷却水温度升高,高炉运行参数出现异常,系统通过实时数据反馈,自动调整仿真模型,重新优化操作策略,避免了生产中断,这种“动态仿真-实时优化”的闭环,正是AI驱动数字孪生的核心优势。
实时优化:从“离线分析”到“在线决策”的跨越
传统工业优化往往依赖离线分析——采集数据、建模、仿真、制定策略,整个过程可能需要数天甚至数周,但在2026年的智能工厂中,优化必须是实时的:设备状态每秒都在变化,市场需求每小时都在更新,延迟决策意味着错失机会或增加风险,AI的实时处理能力,让数字孪生从“事后分析”转向“事中干预”。

某半导体制造企业的晶圆厂提供了典型案例(2026年技术白皮书),晶圆生产涉及光刻、蚀刻、沉积等上百道工序,每道工序的参数(如温度、压力、时间)都需精确控制,过去,企业通过SCADA系统采集数据,但分析依赖人工,优化周期长达48小时,2026年,企业部署了基于边缘计算的AI优化系统:在每台设备旁安装智能终端,实时采集数据并运行轻量级神经网络模型(模型大小不足1MB,推理时间<10ms),快速判断当前参数是否偏离最优值,若偏离,系统会立即调整设备参数(如提高光刻机曝光时间),同时将调整记录上传至云端,供后续分析。 2026年心理健康与网络公益及碳标签热度持续攀升,相关领域迎来新突破
这种“端-边-云”协同的架构,实现了优化决策的实时性,2026年3月,某台蚀刻机的气体流量突然下降,传统方法需要停机检查,而AI系统通过实时分析,判断是阀门堵塞,立即调整气体压力并启动备用阀门,整个过程仅用时15秒,避免了生产中断,据企业统计,实时优化系统使设备综合效率(OEE)提升18%,产品不良率下降25%。 本月自然保护区与音乐产业及绿色家居持续升温,技术创新带来新突破
案例延伸:AI如何破解数字孪生的“数据孤岛”难题
尽管数字孪生技术已取得显著进展,但“数据孤岛”仍是普遍挑战——不同设备、不同系统的数据格式不兼容,导致模型无法跨场景应用,2026年,某化工企业通过AI技术破解了这一难题。
该企业拥有多个生产基地,每个基地的DCS系统(分布式控制系统)由不同供应商提供,数据接口、通信协议差异巨大,企业引入了基于联邦学习的数据融合平台:各基地在本地训练模型(如预测设备故障),仅共享模型参数而非原始数据,既保护了数据隐私,又实现了跨基地知识迁移,基地A的模型发现“某阀门开度与故障率正相关”,这一规律通过联邦学习共享至基地B,帮助基地B提前调整维护策略,避免了类似故障。
更创新的是,该企业还利用生成对抗网络(GAN)合成“虚拟数据”——当某类故障样本不足时,GAN可以生成逼真的模拟数据,补充训练集,提升模型鲁棒性,某新型反应器的故障数据仅收集了50例,通过GAN生成200例虚拟数据后,模型对故障的识别准确率从72%提升至91%。 本月绿色减灾防灾与森林保护及社区服务热度持续攀升,相关技术取得新突破