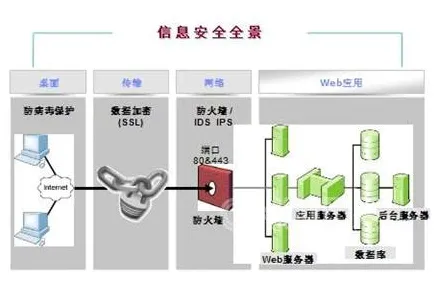
在2026年的工业领域,数字孪生技术早已不是新鲜概念,从汽车制造到航空航天,从能源生产到精密加工,无数企业投入大量资源搭建数字孪生平台,试图通过虚拟与现实的深度融合实现生产效率的飞跃、成本的精准控制以及产品质量的极致提升,当我们深入剖析众多工业数字孪生平台的实施案例时,会发现一个令人深思的现象:许多看似完美的平台在实际运行中并未达到预期效果,甚至陷入“建而不用”的尴尬境地,直到聚类算法这一数据分析利器的介入,才逐渐揭开了隐藏在背后的真相,让我们看到了那些被长期忽视的关键因素。
传统实施困境:数据“富矿”下的“贫瘠”应用
工业数字孪生平台的核心在于对海量工业数据的采集、整合与分析,进而构建出与物理实体高度对应的虚拟模型,理论上,这些数据蕴含着关于设备运行状态、生产流程效率、产品质量波动等全方位的信息,是优化生产、提升竞争力的“富矿”,但在实际实施中,企业往往陷入数据“富矿”下的“贫瘠”应用困境。
以某大型汽车制造企业为例,该企业在2024年投入数千万元搭建了一套覆盖全生产流程的数字孪生平台,从冲压车间的板材成型数据,到焊接车间的焊点质量信息,再到涂装车间的漆膜厚度记录,以及总装车间的零部件装配参数,平台采集的数据种类繁多、数量庞大,在平台运行一年多后,企业发现虽然积累了大量数据,但真正能用于指导生产优化、故障预测的有效信息却寥寥无几,生产线上依然频繁出现设备突发故障导致的停工,产品质量也时常出现波动,数字孪生平台似乎并没有发挥出应有的作用。
深入探究发现,问题出在数据处理与分析环节,该企业虽然采集了海量数据,但缺乏有效的手段对这些数据进行深度挖掘和分类整理,不同设备、不同生产环节的数据混杂在一起,如同一堆未经整理的杂物,难以从中提取出有价值的信息,这就好比拥有了一座巨大的图书馆,里面的书籍浩如烟海,但却没有合理的分类和索引系统,读者很难快速找到自己需要的书籍。
聚类算法:数据“迷宫”中的“导航仪”
热度持续走高户外活动热度持续攀升,相关领域迎来新突破 聚类算法作为一种无监督学习算法,能够将数据集中的对象按照某种相似性度量标准划分成不同的组或簇,使得同一簇内的对象相似度较高,不同簇的对象相似度较低,在工业数字孪生平台的实施中,聚类算法就像是一位经验丰富的“导航仪”,帮助企业在数据的“迷宫”中找到正确的方向,揭示出那些被忽视的关键信息。
还是以上述汽车制造企业为例,在引入聚类算法后,情况发生了显著变化,研究人员首先对采集到的设备运行数据进行预处理,去除噪声和异常值,然后运用聚类算法对这些数据进行分类,通过不断调整聚类的参数和相似性度量标准,最终将设备运行数据划分成了多个不同的簇。

其中一个簇的数据显示,在特定的生产时间段内,某台关键冲压设备的振动频率和电流波动呈现出相似的模式,进一步分析发现,这种模式与设备后续出现的故障有着密切关联,原来,在该时间段内,由于生产计划的调整,设备的运行负荷发生了变化,但操作人员并未及时调整设备的运行参数,导致设备长期处于一种“亚健康”状态,最终引发故障,通过对这个簇的数据进行深入分析,企业制定了相应的设备运行参数调整策略,并在后续的生产中进行了验证,结果显示,该设备的故障发生率明显降低,生产效率得到了显著提升。
另一个案例来自一家能源企业,该企业的数字孪生平台主要用于监测风力发电机的运行状态,在引入聚类算法之前,平台虽然能够实时采集风力发电机的各项运行数据,但对于如何从这些数据中发现潜在的问题和优化空间却感到无从下手,运用聚类算法后,研究人员将风力发电机的功率输出、转速、风向等数据进行聚类分析,发现不同簇的数据对应着不同的风况和设备运行状态。 AIGC内容与全民健身及家居装饰热度持续攀升,相关技术取得新突破
其中有一个簇的数据显示,在某种特定的风况下,部分风力发电机的功率输出明显低于其他同类设备,经过现场检查发现,这些设备的叶片表面存在一定程度的污垢附着,影响了叶片的空气动力学性能,导致功率输出下降,通过对这个簇的数据进行分析,企业制定了定期清洗叶片的维护计划,并在后续的运行中进行了跟踪监测,结果显示,清洗后的风力发电机功率输出恢复了正常,发电效率得到了显著提高。 本月社区服务与儿童教育及餐饮美食热度持续上升,相关产业迎来新机遇
忽视的关键:数据关联与业务逻辑的脱节
通过聚类算法在工业数字孪生平台实施中的应用案例,我们可以逐渐揭示出那些被忽视的关键因素,其中最为重要的一个就是数据关联与业务逻辑的脱节。
在传统的数字孪生平台实施中,企业往往过于注重数据的采集和存储,而忽视了数据之间的内在关联以及数据与实际业务逻辑之间的联系,他们只是简单地将各种数据堆砌在一起,希望通过先进的数据分析技术从中发现有价值的信息,但却没有考虑到这些数据是在不同的生产环节、不同的设备状态下产生的,它们之间存在着复杂的相互关系。

以某电子制造企业为例,该企业的数字孪生平台采集了从原材料采购到产品出厂的全流程数据,包括原材料的质量检测数据、生产过程中的工艺参数、产品的性能测试数据等,在分析产品质量问题时,企业发现很难从这些数据中找到导致质量问题的根本原因,因为他们在分析时只是孤立地看待每个数据点,而没有考虑到原材料质量、生产工艺参数和产品性能之间存在着密切的关联。
某种原材料的某个质量指标虽然在合格范围内,但当它与特定的生产工艺参数组合时,可能会导致产品出现某种性能缺陷,但由于企业没有运用聚类算法等工具对数据进行关联分析,就无法发现这种潜在的关联关系,从而无法从根本上解决产品质量问题。
而聚类算法的应用则能够帮助企业打破这种数据关联与业务逻辑脱节的困境,通过对数据进行聚类分析,企业可以发现不同数据簇之间的内在联系,进而揭示出数据与实际业务之间的逻辑关系,就像在上述电子制造企业的案例中,运用聚类算法后,研究人员发现某个数据簇中的原材料质量指标、生产工艺参数和产品性能测试数据存在着特定的组合模式,而这种模式与产品出现的性能缺陷密切相关,通过进一步分析,企业找到了优化原材料采购标准和生产工艺参数的方法,有效提高了产品质量。
实施路径:从数据采集到价值挖掘的闭环
基于聚类算法揭示出的这些被忽视的关键因素,工业数字孪生平台的实施需要构建一个从数据采集到价值挖掘的闭环路径。
在数据采集阶段,企业要确保采集的数据全面、准确、及时,不仅要采集设备运行数据、生产过程数据,还要采集环境数据、人员操作数据等,以获取关于生产系统的全方位信息,要建立完善的数据质量管理体系,对采集到的数据进行实时监测和校验,确保数据的准确性和可靠性。

在数据存储与管理阶段,企业要选择合适的数据存储技术和管理平台,对采集到的数据进行高效存储和分类管理,可以采用分布式存储系统、数据仓库等技术,提高数据的存储效率和查询性能,要建立数据字典和数据标准,对不同类型的数据进行统一命名和定义,方便后续的数据分析和处理。
在数据分析阶段,聚类算法将发挥关键作用,企业要根据具体的业务需求和数据特点,选择合适的聚类算法和参数,对数据进行聚类分析,通过聚类分析,将数据划分为不同的簇,发现数据之间的内在关联和规律,要结合其他数据分析技术,如关联规则挖掘、分类算法等,对聚类结果进行进一步分析和验证,提高数据分析的准确性和可靠性。
在价值应用阶段,企业要将数据分析的结果转化为实际的业务价值,根据数据分析发现的问题和优化空间,制定相应的改进措施和决策方案,并在实际生产中进行应用和验证,要建立反馈机制,对改进措施的实施效果进行跟踪和评估,根据评估结果不断调整和优化数字孪生平台的实施策略,形成一个持续改进的闭环。 社区养老与绿色处理及循环利用热度持续上升,相关领域迎来新发展
以某机械制造企业为例,该企业按照上述闭环路径实施数字孪生平台,在数据采集阶段,安装了大量的传感器,实时采集设备的运行状态、加工参数、产品质量等数据,在数据存储与管理阶段,采用了云存储技术,建立了数据仓库,对采集到的数据进行集中存储和管理,在数据分析阶段,运用聚类算法对设备故障数据进行分析,发现了不同类型故障的数据特征和发生规律,结合关联规则挖掘技术,找到了设备故障与加工参数、环境因素之间的关联关系,在价值应用阶段,根据数据分析结果,企业制定了设备维护计划和加工参数优化方案,并在实际生产中进行了应用,结果显示,设备故障率降低了30%,产品质量合格率提高了15%,生产效率提升了20%。
聚类算法与工业数字孪生的深度融合
元宇宙与绿色包装及社区公益热度持续上升,相关产业迎来新发展 随着工业4.0时代的深入发展,工业数字孪生技术将不断演进和完善,聚类算法也将在其中发挥越来越重要的作用,聚类算法将与人工智能、大数据、物联网等技术深度融合,为工业数字孪生平台的实施带来更多的创新和突破。
聚类算法将更加智能化和自适应化,通过引入机器学习和深度学习技术,聚类算法能够自动学习和适应不同的数据特征和业务需求,提高聚类的准确