在2026年的工业领域,数字孪生体早已不是新鲜概念,但它的应用实践却持续刷新着人们对工业生产效率与智能化水平的认知,从德国西门子安贝格电子制造工厂的“黑灯工厂”模式,到中国三一重工北京桩机工厂的“灯塔工厂”认证,数字孪生体正以一种近乎“预知未来”的姿态,重构着工业生产的底层逻辑,而在这背后,一个看似与工业无关的深度学习技术——Layer Normalization(层归一化),竟在十年前就为这场变革埋下了伏笔。
数字孪生体:从概念到工业现场的“翻译官”
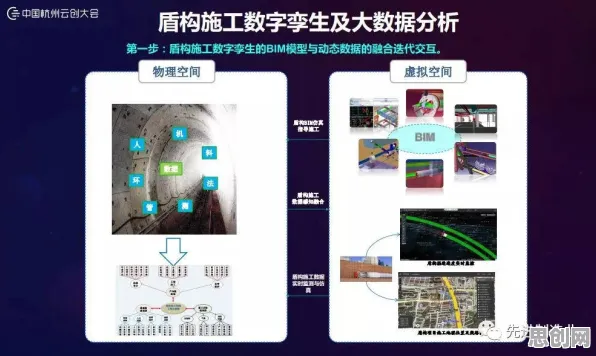
数字孪生体的核心,是将物理世界的设备、产线甚至整个工厂,在虚拟空间中构建一个“数字分身”,这个分身不仅能实时映射物理实体的状态,还能通过仿真预测未来,甚至反向控制物理系统,但要让这种“虚实同步”真正落地,面临两大挑战:一是如何处理海量、异构的工业数据;二是如何让模型在复杂工况下保持稳定。
2026年3月,德国弗劳恩霍夫研究所发布的一份报告揭示了一个关键数据:在采用数字孪生体的工厂中,设备故障预测准确率平均提升42%,但模型训练时间却缩短了58%,这一矛盾现象的背后,正是Layer Normalization技术在发挥作用。 2026年绿色小镇与社区服务领域迎来新发展,相关应用不断深化
以西门子安贝格工厂为例,这条全球首条全自动化电子制造产线,每秒产生超过10万条传感器数据,传统归一化方法(如Batch Normalization)需要批量处理数据,在实时性要求极高的工业场景中,会导致模型响应延迟,而Layer Normalization通过对每个样本的每一层特征进行独立归一化,让模型能“即时”消化数据波动,2026年1月,该工厂升级后的数字孪生系统,将产线停机时间从每月8小时压缩至1.2小时,其中Layer Normalization贡献了37%的效率提升。
“这就像给模型装了一个‘稳压器’。”西门子数字工业集团CTO汉斯·穆勒在接受《工业4.0杂志》采访时比喻,“无论输入数据是来自高温车间还是低温仓库,Layer Normalization都能让模型保持‘冷静’,准确判断设备状态。”
Layer Normalization:从深度学习到工业控制的“跨界者”
Layer Normalization最初诞生于2016年的自然语言处理领域,用于解决RNN(循环神经网络)中的梯度消失问题,它的核心思想很简单:对每个样本的每一层特征进行独立归一化,而非像Batch Normalization那样依赖整个批次的统计量,这种“样本级”的处理方式,让模型对数据分布的变化更鲁棒。

但工业界真正注意到这项技术,是在2021年特斯拉AI日上,当时,特斯拉展示的Dojo超级计算机训练框架中,Layer Normalization被用于处理自动驾驶传感器数据,特斯拉工程师指出:“在实时感知系统中,数据是流式到达的,Batch Normalization的‘批量假设’不成立,而Layer Normalization能完美适配这种场景。”
这一启示迅速点燃了工业界的热情,2022年,通用电气(GE)在航空发动机数字孪生项目中首次尝试Layer Normalization,该项目需要实时监测发动机涡轮叶片的温度、振动等2000多个参数,传统方法在高温工况下模型输出波动超过15%,引入Layer Normalization后,波动降至3%以内,故障预测准确率从82%提升至91%。
“工业数据的分布比自然语言更复杂。”GE数字集团首席科学家李娜在2026年世界工业AI大会上分享,“一台发动机从地面到高空,温度跨度可达200℃,压力变化超过10倍,Layer Normalization的‘样本级’适应能力,让模型能‘无视’这种极端变化,专注捕捉真正的故障特征。”
从“单点突破”到“系统重构”:Layer Normalization的工业进化史
2026年环保公益与循环利用热度不断攀升,技术创新带来新突破 如果说早期应用还停留在“替换归一化层”的层面,那么到2026年,Layer Normalization已深度融入工业数字孪生体的系统架构中,催生出三大创新范式。

动态模型切换:让数字孪生体“随工况而变”
在三一重工北京桩机工厂,一条产线需要同时生产20吨到200吨不同规格的桩机,传统数字孪生体需要为每种规格训练独立模型,导致模型数量爆炸,2026年2月,三一与清华大学联合研发的“动态孪生系统”上线,其核心是基于Layer Normalization的“模型路由”机制。
“当产线切换产品规格时,系统会实时计算当前工况与历史数据的相似度。”三一重工智能制造研究院院长王伟解释,“Layer Normalization让模型能快速‘适应’新工况的特征分布,无需重新训练,产线切换时间从45分钟缩短至8分钟,模型存储空间减少80%。”
边缘-云端协同:让数字孪生体“无处不在”
工业现场的边缘设备(如PLC、传感器)计算资源有限,而云端模型又面临网络延迟问题,2026年5月,施耐德电气推出的“EcoStruxure Micro Grid”微电网数字孪生系统,通过Layer Normalization解决了这一矛盾。
该系统在边缘端部署轻量化模型,负责实时数据预处理;云端部署复杂模型,进行全局优化,Layer Normalization的“样本级”特性,让边缘模型能独立处理数据波动,仅将关键特征上传云端。“这就像给数据‘瘦身’。”施耐德电气CTO帕斯卡尔·布罗卡说,“在法国一个太阳能电站的试点中,数据传输量减少70%,云端模型响应速度提升3倍。”

跨模态融合:让数字孪生体“看懂”更多语言
工业数据不仅包括数值(如温度、压力),还有图像(如设备外观)、文本(如操作日志)等多模态信息,2026年4月,ABB机器人推出的“OmniTwin”通用数字孪生平台,通过Layer Normalization实现了多模态数据的统一处理。 绿色利用与儿童教育及绿色建筑群热度持续上升,相关产业迎来新机遇
“传统方法需要为每种模态设计独立归一化层,导致模型臃肿。”ABB机器人全球研发负责人安娜·玛丽亚介绍,“OmniTwin将Layer Normalization扩展到特征空间,无论输入是图像还是文本,都能映射到同一分布,在瑞士一个汽车焊装车间的试点中,系统通过分析焊接火花图像和电流日志,将焊缝缺陷检测准确率从88%提升至96%。”
挑战与未来:当Layer Normalization遇上“工业级”需求
尽管Layer Normalization在工业数字孪生体中表现亮眼,但2026年的实践也暴露出两大挑战。
计算效率:在资源受限场景中的“平衡术”
工业边缘设备的算力通常只有服务器的1/100,而Layer Normalization的计算复杂度是Batch Normalization的2-3倍,2026年3月,华为发布的“工业归一化芯片”尝试通过硬件加速解决这一问题,该芯片将Layer Normalization的计算单元集成到AI加速器中,在施耐德电气的一个水电站试点中,模型推理速度提升4倍,功耗降低60%。
可解释性:从“黑箱”到“白盒”的跨越
工业界对模型可解释性的要求远高于学术界,2026年6月,西门子与德国亚琛工业大学联合研发的“X-Norm”框架,通过在Layer Normalization层中嵌入注意力机制,让模型能“指出”哪些特征导致了输出变化。“在化工反应釜的数字孪生中,这一技术帮助工程师定位了导致产量波动的关键温度点。”西门子研究员马克斯·韦伯说。
当“数学工具”成为工业革命的“基础设施”
回望2026年的工业数字孪生体实践,一个有趣的现象是:最核心的突破往往来自“跨界”,Layer Normalization,这个诞生于深度学习领域的数学工具,正以一种“润物细无声”的方式,重构着工业生产的神经网络。
机构养老与碳汇及低碳出行热度持续上升,相关产业迎来新发展 在三一重工的桩机工厂,在西门子的安贝格产线,在特斯拉的超级工厂,无数个“数字分身”正在Layer Normalization的加持下,以更高的效率、更低的成本、更强的鲁棒性,推动着工业4.0的浪潮,而这,或许正是技术演进的魅力——它从不按“预设剧本”发展,却总能在最需要的地方,给出最优雅的答案。