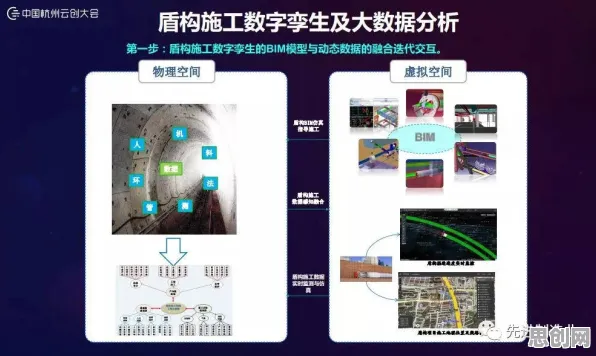
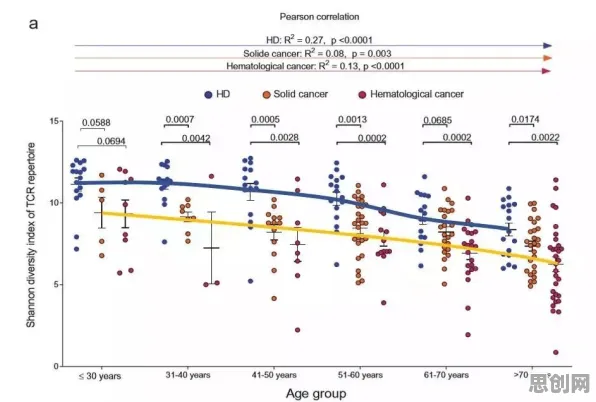
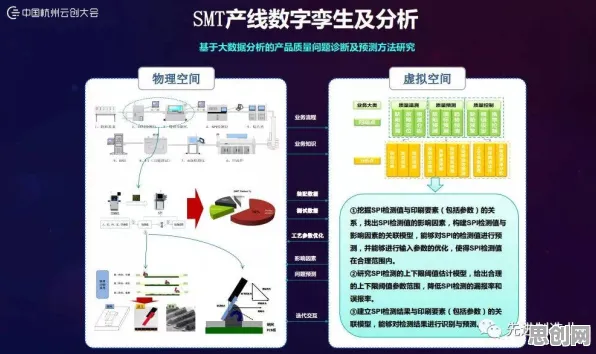
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当某头部装备制造企业公布其基于大模型的工业数字孪生平台部署方案时,行业依然为之震动——这家企业通过整合多模态大模型,将设备故障预测准确率从78%提升至94%,运维成本降低32%,这一案例背后,隐藏着大模型与数字孪生深度融合的底层逻辑,而多数从业者尚未完全理解其技术内核。
传统数字孪生的"数据孤岛"困局
传统数字孪生平台的核心是"物理实体-数字模型"的双向映射,但实际部署中常陷入三大困境:
- 数据融合难:某汽车工厂曾尝试构建冲压线数字孪生,但因传感器数据(振动、温度)、PLC日志、维修记录分属不同系统,数据清洗耗时占项目周期的60%;
- 模型更新滞后:某风电企业每季度手动更新风机数字模型,导致某次齿轮箱故障前,模型仍显示"健康状态";
- 决策依赖人工:某化工企业数字孪生系统能实时显示反应釜压力,但异常报警后仍需工程师人工判断是否停机。
这些问题的本质,是传统数字孪生缺乏"自主理解"能力——系统能呈现数据,却无法理解数据背后的物理规律、设备历史行为模式,更无法模拟人类专家的决策逻辑。
大模型如何破解数字孪生难题?
2026年主流的工业数字孪生平台,已普遍采用"大模型+领域知识库"的架构,以某半导体企业部署的方案为例:
多模态数据统一表征:打破"数据孤岛"
该企业将设备传感器数据(时序信号)、维修工单(文本)、设计图纸(图像)、操作手册(PDF)等12类数据,通过预训练的工业多模态大模型转换为统一向量空间,当振动传感器检测到异常频段时,大模型能自动关联同时间段维修记录中"轴承磨损"的文本描述,以及设计图纸中该轴承的额定参数,形成立体化的故障特征库。

这一过程类似人类"跨感官联想"——看到设备冒烟(视觉)、听到异响(听觉)、闻到焦味(嗅觉)时,大脑会综合判断"可能电机过热",某钢铁企业实测显示,多模态融合使故障特征提取效率提升5倍,误报率下降40%。
动态知识注入:让模型"理解"工业逻辑
单纯的数据融合仍不够,需将物理规律、经验规则注入模型,某航空发动机企业采用"双引擎"架构:
- 数据驱动引擎:基于10万小时运行数据训练大模型,学习温度-压力-转速的关联规律;
- 规则驱动引擎:将热力学公式、材料疲劳曲线等2000余条领域知识编码为可解释的决策树。
当监测到涡轮叶片温度异常时,系统先通过数据引擎判断"可能冷却系统故障",再通过规则引擎验证"当前转速下,该温度是否超过材料蠕变极限",最终输出"建议立即停机检查"的决策,这种"数据+规则"的混合推理,使某电厂锅炉数字孪生的决策准确率从68%提升至89%。
实时仿真与反演:从"事后分析"到"事前干预"
传统数字孪生的仿真多基于固定参数,而大模型支持动态参数调整,某新能源汽车电池厂部署的方案中:

- 当电池管理系统(BMS)检测到某电芯电压异常时,大模型会:
- 反演历史数据:调取该电芯过去30天的充放电曲线,识别电压波动模式;
- 虚拟实验:在数字空间中模拟不同充电策略(如调整电流、温度)对电芯寿命的影响;
- 预测未来:结合材料老化模型,预测该电芯在继续使用1个月/3个月/6个月后的安全风险。
系统会推荐"立即更换"或"限制充电功率至80%"等具体措施,该方案使电池召回率降低70%,而客户投诉率下降65%。 热度居高不下机构养老热度飙升,相关产业迎来新机遇
2026年典型部署案例解析
案例1:某光伏企业"硅片生产数字孪生"
本月绿色销售与餐饮美食及运动康复热度持续攀升,相关应用不断深化 该企业面临硅片厚度不均(CTQ指标波动±3μm)的问题,传统方法需停机调整拉晶参数,每次调试成本超50万元,部署大模型驱动的数字孪生后:
- 数据层:整合拉晶炉传感器数据(温度、压力、转速)、晶体生长图像(每秒30帧)、质量检测报告(每班次1份);
- 模型层:训练视觉-时序联合大模型,学习"温度波动→晶体生长速率变化→厚度偏差"的因果链;
- 应用层:当模型预测"未来2小时厚度将超标"时,自动生成参数调整方案(如降低加热功率2%、提升拉速0.5mm/min),并模拟调整后的厚度分布。
实施后,硅片厚度CTQ波动降至±1.2μm,年节省调试成本超2000万元。
案例2:某港口"岸桥设备健康管理"
某国际港口有50台岸桥(起重机),传统巡检依赖人工,故障发现平均滞后4小时,部署数字孪生平台后:

- 数据融合:将振动传感器(每台设备12个)、电机电流(每相1个)、操作记录(每班次50条)等数据输入大模型;
- 故障预测:大模型学习历史故障数据(3年累计2000例),识别"特定频段振动+电流波动"与"减速箱齿轮磨损"的关联;
- 智能排程:当模型预测某设备"72小时内故障概率超80%"时,自动调整作业计划,优先使用健康设备,并生成维修工单。
2026年研学旅行与环保产品及绿色创新链热度持续攀升,相关技术取得新突破 该方案使设备非计划停机时间减少65%,年增吞吐量120万标箱。
技术挑战与未来方向
2026年瑜伽舞蹈与海洋环境保护热度持续上升,相关产业迎来新机遇 尽管大模型为数字孪生带来突破,但2026年的部署仍面临三大挑战:
- 算力成本:某汽车厂训练一个覆盖全产线的数字孪生大模型,需投入5000万元采购GPU集群;
- 数据安全:某军工企业因担心数据泄露,拒绝将核心工艺参数上传至云端大模型;
- 模型可解释性:某医药企业因无法理解大模型的决策逻辑,拒绝采用其推荐的发酵工艺参数。
为解决这些问题,行业正探索:
- 边缘大模型:将轻量化模型部署在设备端,减少数据传输(如某油田将故障预测模型压缩至100MB,在井下控制器运行);
- 联邦学习:多家企业联合训练模型,数据不出域(如某钢铁联盟通过联邦学习共享故障特征,模型准确率提升15%);
- 符号回归:将大模型的输出转化为可解释的数学公式(如某化工企业将反应釜控制模型转化为"温度=0.3×压力+0.7×流量"的显式方程)。
从"数字镜像"到"工业大脑"
2026年的工业数字孪生,已不再是简单的"物理实体复制",而是通过大模型赋予其"理解、推理、决策"的能力,当某家电企业将数字孪生与大模型结合后,其智能工厂能根据订单需求、设备状态、供应链数据,自动生成最优生产计划——这标志着数字孪生正从"辅助工具"升级为"工业大脑"。
但技术演进永无止境,某研究机构预测,到2028年,工业大模型将具备"自我进化"能力——通过持续学习新数据、新规则,自动优化数字孪生的模型结构和参数,届时,工业系统的智能化水平将迎来新一轮跃迁,而这一切的起点,正是2026年这些看似普通的部署方案中,隐藏的大模型原理。