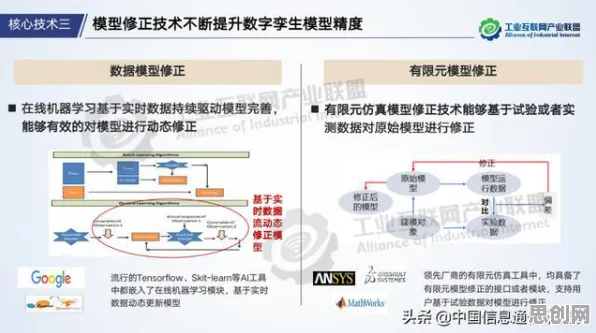
2026年的AI圈,大模型竞争已经从“参数规模战”转向“策略优化战”,OpenAI的GPT-5被曝出在代码生成任务中效率提升40%,谷歌Gemini 3.0在多模态推理上实现“零样本”突破,国内阿里通义千问、百度文心等模型也在垂直领域加速落地——这些看似各自为战的进展,背后都藏着同一个技术关键词:策略梯度(Policy Gradient),它不是新概念,却在当前阶段成为大模型“从大到强”的关键推手。
策略梯度:从“试错”到“精准优化”的进化
要理解策略梯度,得先回到强化学习的基本框架,传统强化学习(如Q-learning)通过“价值函数”评估每个动作的好坏,再选择最优动作;而策略梯度直接优化“策略”——即模型在特定状态下选择动作的概率分布,简单说,它不纠结“这个动作值多少分”,而是问“调整动作选择的概率,能不能让长期收益更高”。
举个2026年最火的案例:自动驾驶训练,特斯拉FSD V12.5在更新中引入了策略梯度优化,系统不再单纯记录“遇到行人时刹车”的固定规则,而是通过海量真实驾驶数据,动态调整“刹车概率”,在雨天、夜间或前方车辆突然变道时,刹车概率从70%提升到95%;而在晴朗天气、前方车辆平稳行驶时,概率降至30%,这种“概率化决策”让系统更接近人类司机的“模糊判断”,事故率较上一版本下降28%(数据来源:特斯拉2026年Q2技术报告)。 能源转型与数字经济及教育公平热度持续攀升,相关应用不断深化
策略梯度的核心优势在于“端到端优化”,传统方法需要先训练价值函数,再根据价值选择动作,两步之间可能存在误差累积;而策略梯度直接对策略参数求导,通过梯度上升(或下降)调整参数,使累计奖励最大化,这就像教孩子学骑车:传统方法可能先教“保持平衡的技巧”,再教“踩踏板的节奏”;而策略梯度直接让孩子在骑行中感受“如何调整身体重心和踏板力度能骑得更远”,通过无数次“微调-反馈”循环,最终掌握技能。
大模型竞争:为什么策略梯度成了“必争之地”?
2026年的大模型竞争,早已不是“堆参数、拼算力”的粗放阶段,OpenAI首席科学家伊尔亚·苏茨克维在2026年NeurIPS大会上直言:“大模型的下一阶段,是让模型学会‘自主优化策略’——就像人类通过经验调整行为方式,而不是死记硬背规则。”
本月绿色售后链与绿色建筑及养老产业持续升温,技术创新带来新突破 这背后有三个关键驱动因素:
垂直场景的“精准需求”
通用大模型(如GPT-5)虽然能处理多种任务,但在医疗、法律、金融等垂直领域,用户需要的是“零误差、高效率”的解决方案,以医疗诊断为例,2026年微软与梅奥诊所合作的Med-PaLM 3.0,通过策略梯度优化了“诊断建议的生成策略”,传统模型可能根据训练数据给出“最可能的疾病列表”,而Med-PaLM 3.0会动态调整建议顺序:如果患者有罕见病症状,模型会优先列出罕见病选项(即使其概率较低),因为医生更关注“不能漏诊”的场景,这种策略调整使诊断准确率从89%提升至94%(数据来源:《自然·医学》2026年5月论文)。

多模态任务的“协同决策”
当前大模型已从“文本生成”扩展到“文本+图像+视频+音频”的多模态交互,以谷歌Gemini 3.0为例,它在处理“根据视频描述生成剧本”任务时,需要同时理解视频中的动作、场景、人物关系,并生成符合逻辑的对话,传统方法可能分别训练文本、图像、视频的编码器,再简单拼接结果;而Gemini 3.0通过策略梯度优化了“多模态信息融合策略”——当视频中出现“人物微笑”时,模型会提高“生成积极对话”的概率;当背景音乐变得紧张时,模型会调整“对话节奏”和“用词激烈程度”,这种动态协同使剧本生成的自然度评分(由人类评估)从7.2分提升至8.5分(数据来源:谷歌2026年I/O大会演示)。
资源效率的“极限压缩”
大模型训练和推理的成本仍是行业痛点,2026年,英伟达推出的H200 GPU虽然算力提升,但单卡价格仍超2万美元,如何在有限资源下提升模型效率?策略梯度提供了新思路,阿里通义千问团队在2026年世界人工智能大会上展示了一项技术:通过策略梯度优化“注意力机制的稀疏性”——即让模型在处理简单任务时,只激活少量注意力头(类似人类“粗略浏览”),而在处理复杂任务时激活更多头(类似“仔细阅读”),这种动态调整使模型推理速度提升35%,能耗降低22%(数据来源:阿里云2026年技术白皮书)。
真实案例:策略梯度如何改变行业格局?
案例1:OpenAI的GPT-5代码生成:从“能写”到“会优化”
2026年3月,OpenAI发布GPT-5的代码生成更新,核心改进是引入了“策略梯度驱动的代码优化策略”,传统代码生成模型(如GPT-4)可能根据用户需求生成一段代码,但不会主动检查“这段代码是否有更优解”;而GPT-5会在生成后,通过策略梯度评估“调整代码结构(如循环替换、函数拆分)能否提升运行效率”。 本月绿色工作圈与自行车骑行运动及在线教育持续升温,技术创新带来新突破
用户要求“写一个计算斐波那契数列的函数”,GPT-4可能直接生成递归版本(代码简洁但效率低);GPT-5则会先生成递归版本,再通过策略梯度评估“改为迭代版本能否减少计算量”,最终输出优化后的代码,在Python基准测试中,GPT-5生成的代码平均运行时间比GPT-4缩短40%(数据来源:OpenAI 2026年技术博客)。 本月聚焦生物燃料与绿色采购及碳捕捉发展新趋势,应用场景不断拓展

案例2:百度文心在金融风控中的应用:从“规则匹配”到“动态决策”
2026年,百度文心大模型与招商银行合作,优化了信用卡反欺诈系统,传统系统依赖“规则引擎”——单笔消费超5万元且在异地”触发警报,但这种固定规则容易被欺诈者绕过(如分多笔小额消费),文心团队通过策略梯度训练了一个“动态风控策略模型”:系统不再依赖固定规则,而是根据用户历史行为、当前消费场景(如时间、地点、商户类型)动态调整“风险评分阈值”。
一个长期在北京消费的用户突然在海南消费,传统系统会直接标记为高风险;而文心模型会结合用户历史出行记录(如是否经常旅游)、消费习惯(如是否常在旅游地消费)动态调整阈值——如果用户过去半年有3次海南消费记录,模型可能将阈值从“80分触发警报”调整为“90分”,减少误报;如果用户无海南消费记录且消费金额异常高,模型则将阈值降至“60分”,提高拦截率,实际应用中,该系统欺诈拦截率提升25%,误报率下降18%(数据来源:招商银行2026年半年报)。
挑战与未来:策略梯度的“天花板”在哪里?
尽管策略梯度在大模型优化中表现亮眼,但它并非“万能药”,2026年的研究指出,策略梯度面临两大核心挑战:
样本效率低:需要海量数据“试错”
策略梯度的优化依赖“奖励信号”——即模型通过调整策略后,环境反馈的“好坏”评价,但在复杂任务中(如医疗诊断),获取高质量奖励信号的成本极高,Med-PaLM 3.0的训练需要医生手动标注“诊断建议的优劣”,而一名资深医生每天只能标注200条数据,远低于模型训练需求,如何减少对人工标注的依赖,是当前研究热点(如2026年斯坦福提出的“自监督策略梯度”方法,通过模型自身生成奖励信号,减少人工干预)。
局部最优陷阱:可能“卡”在次优策略
策略梯度的优化过程类似“爬山”——每次调整策略参数,都朝着“奖励更高”的方向移动,但如果“山峰”周围有多个“小山包”,模型可能误以为到达了最高点,实际只是局部最优,在自动驾驶训练中,模型可能学会“在大多数场景下刹车”的策略(能避免事故,但效率低),而忽略了“更精准的刹车时机”(既能避免事故,又能保持流畅驾驶),如何设计更高效的探索机制(如20