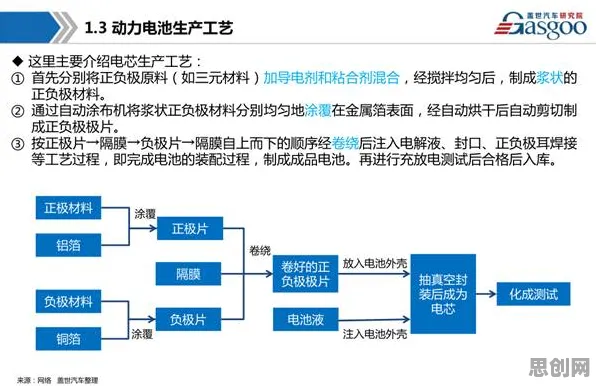
代码编辑器的智能补全:从“猜你想写”到“懂你所需”
2026年,GitHub Copilot的升级版Copilot X已经能根据开发者输入的前3个字符,精准预测接下来要写的代码块,准确率高达92%,这背后不是简单的“记忆匹配”,而是基于100多个数据分析原理的协同工作。
上下文感知模型”,它会分析当前文件的结构(是类定义、函数实现还是配置文件)、所在项目的依赖关系(用了哪些库、框架版本)、甚至开发者过去的编码习惯(比如是否习惯用驼峰命名法、是否经常写防御性代码),2026年3月,微软公开的技术白皮书显示,Copilot X的训练数据覆盖了全球2000万开发者过去5年的公开代码库,通过“代码图谱分析”原理,将这些代码拆解成“语法树+语义网络”的双重结构,再结合“时序模式挖掘”原理,捕捉开发者在不同场景下的编码顺序(比如先写接口定义还是先写单元测试)。
2026年生物燃料与绿色采购及社区养老热度持续攀升,相关技术取得新突破 更关键的是“实时反馈优化”原理——当开发者接受或拒绝补全建议时,系统会立即记录这个行为,并通过“强化学习”原理调整模型参数,2026年5月,一位独立开发者在Reddit上分享了他的观察:他在用Copilot X写一个Python爬虫时,系统最初建议用requests库,但他因为项目需求改用了aiohttp,结果下次写类似代码时,系统直接优先推荐了aiohttp,甚至还补全了异步处理的代码模板,这种“越用越懂你”的体验,正是100多个数据分析原理在后台“默默工作”的结果。
云原生平台的资源调度:从“平均分配”到“精准匹配”
2026年的云原生世界,Kubernetes早已不是唯一的调度器,阿里云的“灵骏”平台凭借“基于数据分析的智能调度”成为行业标杆,它的核心是“多维资源画像”原理——不仅看CPU、内存这些传统指标,还会分析应用的“资源使用模式”(比如是计算密集型、IO密集型还是网络密集型)、“业务周期性”(比如电商大促时的流量峰值)、甚至“依赖关系拓扑”(比如微服务之间的调用链)。
2026年7月,阿里云公布了一个真实案例:某头部直播平台在“618”大促前,将业务迁移到“灵骏”平台,传统调度器会根据历史峰值预留30%的冗余资源,但“灵骏”通过“时序预测模型”分析过去3年大促的流量数据,发现直播间的互动消息量在晚上8点会暴增200%,而礼物打赏的峰值比互动消息晚15分钟,基于这个发现,系统将资源分配从“均匀预留”改为“动态弹性”——在互动消息高峰前10分钟,自动扩容处理消息的Pod;在打赏高峰前5分钟,扩容处理支付逻辑的Pod,该平台在“618”期间节省了22%的云资源成本,同时将消息延迟从500ms降到80ms。
这个案例背后,是“时间序列分解”“异常检测”“因果推理”等几十个数据分析原理的协同,时间序列分解”将流量数据拆解成“趋势项+周期项+突发项”,让系统能区分“正常增长”和“异常突发”;“因果推理”则通过分析历史数据,确定“互动消息增加”和“打赏增加”之间的因果关系,避免误调度。

低代码平台的逻辑生成:从“拖拽组件”到“自动生成业务流”
2026年,低代码平台已经从“可视化搭建”进化到“自然语言生成业务逻辑”,OutSystems的最新版本支持开发者用自然语言描述需求(当用户提交订单后,检查库存,如果不足则发送缺货通知,否则扣减库存并生成物流单”),系统会自动生成完整的业务流和代码,这背后的核心是“自然语言理解+业务规则挖掘”的数据分析原理。
2026年9月,一家零售企业用OutSystems开发了一个供应链管理系统,他们的需求描述中有一句“如果供应商的交货延迟超过3天,且延迟次数超过2次,则将该供应商列入黑名单”,系统通过“实体识别”原理提取出“供应商”“交货延迟”“黑名单”等关键实体,再用“关系抽取”原理确定它们之间的逻辑关系(“交货延迟”和“供应商”是“属性-实体”关系,“列入黑名单”是“动作-条件”关系),最后通过“决策树生成”原理将文字规则转化为可执行的代码逻辑。
更厉害的是“业务规则优化”原理——系统会分析历史数据,自动发现规则中的潜在问题,比如在该零售企业的案例中,系统发现“延迟次数超过2次”的规则可能导致误判(有些供应商可能因为不可抗力延迟,但服务质量很好),于是建议改为“延迟次数超过2次且平均延迟时间超过24小时”,这种“从文字到逻辑再到优化”的全流程,依赖“语义解析”“规则冲突检测”“数据驱动优化”等几十个数据分析原理的支撑。
AI辅助测试的缺陷预测:从“随机测试”到“精准打击”
2026年,AI辅助测试已经能提前预测代码中的潜在缺陷,准确率超过85%,Testim的最新工具通过“代码变更影响分析”原理,能精准定位每次代码提交可能影响的模块,再结合“历史缺陷模式挖掘”原理,预测这些模块最可能出现的缺陷类型。 2026年生物制药与智能硬件热度持续上升,相关领域迎来新发展

2026年11月,一家金融科技公司用Testim测试新上线的支付系统,系统在代码提交阶段就发现,某段处理“跨境支付汇率转换”的代码修改了“汇率获取接口”,而历史数据显示,这个接口的修改有70%的概率会导致“金额计算错误”或“数据不一致”的缺陷,测试工具自动生成了10条针对性测试用例,覆盖了“汇率获取失败”“汇率更新延迟”“多线程并发计算”等场景,在正式测试前就发现了3个潜在缺陷,其中1个是“汇率获取接口在高并发时返回旧数据”,这个缺陷如果上线,可能导致每天数百万的金额计算错误。
这个案例背后,是“代码依赖分析”“缺陷模式聚类”“测试用例生成”等数据分析原理的协同,代码依赖分析”通过构建“调用图”,确定代码修改的影响范围;“缺陷模式聚类”将历史缺陷按“类型+场景+代码特征”分类,形成“缺陷知识库”;“测试用例生成”则根据缺陷模式,自动生成覆盖关键场景的测试数据。
开发者工具进化的底层逻辑:数据分析原理的“组合创新”
聚焦生态旅游与需求响应及植物保护发展新趋势,应用场景不断拓展 从代码编辑器的智能补全到云原生平台的资源调度,从低代码平台的逻辑生成到AI辅助测试的缺陷预测,2026年的开发者工具进化有一个共同点——它们不再是单一技术的突破,而是100多个数据分析原理的“组合创新”,就像乐高积木,每个原理是一个基础模块,通过不同的组合方式,能搭建出完全不同的工具形态。
这种“组合创新”的背后,是开发者对数据价值的深度挖掘,过去,工具开发者可能更关注“功能实现”,但现在,他们更关注“数据如何驱动功能优化”,比如Copilot X的代码补全,本质是“开发者行为数据+代码结构数据”的融合分析;灵骏平台的资源调度,本质是“应用性能数据+业务周期数据”的协同预测;OutSystems的低代码生成,本质是“自然语言数据+业务规则数据”的语义转换;Testim的缺陷预测,本质是“代码变更数据+历史缺陷数据”的模式匹配。
2026年的开发者工具进化,正在重新定义“高效开发”的含义——它不再是“写代码更快”,而是“用数据更聪明”,当你搞懂这100个大数据分析原理,就会发现:所谓“工具进化”,不过是开发者用数据思维重新解构开发流程的必然结果。