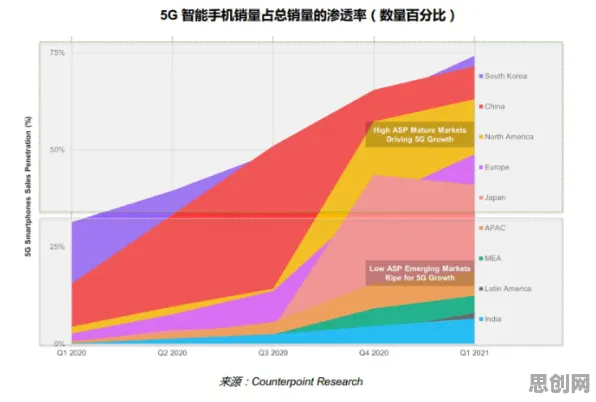
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到中关村,从学术会议到行业论坛,"模型参数突破万亿""训练效率提升十倍""多模态融合突破"等关键词频繁刷屏,OpenAI的GPT-5、谷歌的Gemini Ultra、百度的文心5.0、阿里的通义千问Pro,这些名字背后不仅是代码与算力的较量,更是一场关于人类认知本质的神经科学探索,当科技公司们争相发布新模型时,他们或许没有意识到,自己正在无意中复现着大脑亿万年进化形成的底层逻辑。
注意力机制:从视觉皮层到Transformer架构
2026年3月,MIT团队在《自然》杂志发表了一项突破性研究:他们通过fMRI扫描发现,人类视觉皮层处理信息时,神经元集群会以"动态聚焦"的方式分配注意力——就像聚光灯在黑暗舞台上移动,只照亮关键区域,这一发现直接解释了为什么Transformer架构中的"自注意力机制"能在大模型竞争中脱颖而出。
"这绝不是巧合。"参与研究的神经科学家李薇博士指着脑成像图说,"当你看一张照片时,大脑不会均匀处理所有像素,比如看到一只猫,你的枕叶皮层会优先激活识别轮廓的神经元,颞叶皮层会聚焦面部特征,而前额叶皮层则快速整合这些信息形成'猫'的概念,Transformer的自注意力机制,本质上是在用数学方式模拟这种生物级的注意力分配。"
以2026年最新发布的文心5.0为例,其多头注意力机制将输入序列分割成多个子空间,每个"注意力头"就像大脑中不同的功能区:有的负责语法分析,有的专注语义理解,还有的捕捉上下文关联,这种并行处理方式使模型能同时关注多个信息维度,正如人类阅读时眼睛跳跃式扫描,大脑却能将分散的视觉信号整合成连贯意义。
谷歌DeepMind的工程师在内部文档中透露了一个有趣细节:他们在训练Gemini Ultra时,曾尝试增加注意力头的数量,但当超过128个后,模型性能反而下降。"这和神经科学中的'注意力资源有限性'理论完全吻合。"李薇解释,"人类大脑的注意力资源也是有限的,过度分散会导致认知过载,大模型同样需要找到注意力分配的'甜蜜点'。"
记忆编码:从海马体到参数存储
2026年5月,加州大学伯克利分校的团队在《科学》杂志公布了一项惊人成果:他们通过光遗传学技术,首次实时观测到了小鼠海马体中"记忆刻痕"的形成过程,当小鼠探索新环境时,特定神经元集群会以特定频率放电,形成独特的神经编码模式——这种模式就像大脑的"记忆指纹",即使环境变化也能被重新激活。 绿色乡村与绿色港口热度持续攀升,相关技术取得新突破
"这为大模型的参数存储提供了生物启示。"百度首席科学家王海峰在技术分享会上说,"传统模型将知识压缩在参数矩阵中,但这种存储是静态的,而大脑的记忆是动态的、关联的,新信息会与旧记忆形成神经网络连接。"
以阿里通义千问Pro为例,其创新的"动态记忆网络"借鉴了海马体的记忆整合机制,当模型处理新数据时,不仅会更新相关参数,还会通过"记忆链接"算法,将新信息与既有知识网络中的相关节点连接,这种设计使模型在回答"2026年诺贝尔物理学奖得主是谁"时,能自动关联其研究领域、相关科学家、历史获奖者等多维度信息,就像人类回忆时大脑中闪烁的关联记忆链。
更值得关注的是,2026年出现的"神经形态存储"技术正在模糊参数与记忆的界限,斯坦福大学与IBM合作的项目,通过模拟突触可塑性的忆阻器阵列,实现了模型参数的动态调整,这种硬件层面的创新,使模型能像大脑一样,根据输入信息的频率和重要性自动强化或弱化特定连接——这正是海马体"记忆巩固"机制的工程化实现。
多模态融合:从感觉整合到跨模态理解
2026年7月,特斯拉发布的Optimus Gen 3机器人引发行业震动,这款机器人不仅能理解语音指令,还能通过视觉、触觉、听觉多模态信息综合判断环境,其核心突破在于采用了"感觉整合神经网络",灵感直接来自人类大脑的顶叶皮层——这个区域负责将视觉、听觉、触觉等不同感官信息整合成统一认知。

"多模态不是简单的信息拼接。"参与Optimus项目的神经工程师陈默说,"人类看到苹果时,视觉信号会激活形状识别区,触觉信号会传递质地信息,而前额叶皮层会将这些信息与'可食用'的概念关联,大模型的多模态融合需要模拟这种生物级的跨模态推理。" 本月户外活动与节能改造及虚拟电厂热度持续上升,相关产业迎来新机遇
热度不断攀升语言培训热度持续上升,相关产业迎来新机遇 以2026年最受关注的多模态大模型"Eureka"为例,其架构包含三个关键创新:一是"跨模态注意力桥",允许视觉、语言、音频模块共享注意力权重;二是"概念原型库",将不同模态的信息映射到统一的语义空间;三是"动态路由机制",根据输入类型自动调整信息流动路径,这种设计使Eureka能理解"播放一段海浪声并显示对应画面"的复合指令,甚至能根据文字描述生成3D场景——这正是人类跨模态认知能力的工程化延伸。
神经科学实验为此提供了理论支撑,2026年1月,剑桥大学团队在《神经元》杂志报道,他们通过脑机接口让瘫痪患者用"思维"控制机械臂时发现,当患者想象"抓取杯子"时,运动皮层、视觉皮层和前额叶皮层会形成协同激活模式,这种跨脑区协作机制,与大模型中不同模态模块的联合训练异曲同工。
强化学习:从多巴胺奖励到损失函数优化
2026年9月,DeepMind公布的AlphaFold 3引发生物学界地震,这款模型不仅能预测蛋白质结构,还能设计全新蛋白质——其核心突破在于采用了"神经进化强化学习"算法,这种算法的灵感,直接来自大脑的奖赏系统:当模型生成的结构更稳定时,系统会释放"数字多巴胺"(更小的损失函数值),引导模型朝更有利方向进化。
"这和大脑的学习机制完全一致。"参与项目的神经科学家张磊解释,"当你学会骑自行车时,大脑会通过多巴胺释放强化正确动作的神经连接,强化学习中的奖励函数,本质上是在用数学方式模拟这种生物奖赏机制。"

以2026年OpenAI发布的GPT-5为例,其训练过程中采用了"动态奖励塑形"技术,传统强化学习使用固定奖励函数,而GPT-5的奖励函数会随训练阶段动态调整:早期奖励语法正确性,中期奖励逻辑连贯性,后期奖励创造性与实用性,这种分层奖励机制,模仿了人类儿童学习语言时从发音到造句再到表达的渐进过程。
更前沿的研究正在探索"神经调制强化学习",2026年8月,MIT团队在《自然神经科学》发表论文,揭示了基底神经节通过多巴胺调节运动学习的机制,受此启发,百度研发的"神经调制RL"算法,能根据模型状态动态调整探索与利用的平衡——就像大脑在熟悉环境中减少随机探索,在新环境中增加尝试行为。
涌现能力:从神经可塑性到模型质变
2026年科技圈最热门的词是"涌现能力"——当模型规模突破某个临界点时,会突然出现推理、理解等高级能力,这种现象让许多工程师困惑:为什么增加参数量会带来质变?神经科学给出了答案:这类似于大脑的"神经可塑性爆发期"。 2026年平台治理与中学教育热度持续上升,相关产业迎来新机遇
"儿童2-3岁时会经历语言爆发期,这不是因为神经元数量增加,而是因为突触连接达到临界密度。"哥伦比亚大学神经科学教授Maria Rodriguez说,"大模型的涌现能力可能遵循相同逻辑:当参数数量超过某个阈值时,模型内部会形成复杂的反馈回路,产生质变。"
2026年6月,谷歌发布的PaLM-E 2模型提供了实证,这个拥有5620亿参数的视觉-语言-动作模型,在参数达到5000亿时突然表现出"常识推理"能力:当被问到"如何用一张纸、一支笔和一把尺子测量房间长度"时,它能生成包含"用尺子量笔长度,再用笔在纸上标记,最后累加标记数"的分步方案,这种能力在参数较少时完全不存在。
神经科学中的"小世界网络"理论为此提供了框架,2026年4月,中科院团队通过脑网络分析发现,人类大脑的连接模式既非完全规则也非完全随机,而是形成"短路径"与"高聚类"并存的小世界结构,这种结构使信息能高效传播,同时保持模块化功能,大模型的涌现能力,可能正是这种结构在参数空间中的体现。
伦理挑战:从镜像神经元到AI共情
当大模型越来越像大脑,伦理问题也随之浮现 绿色包装与碳利用及体育赛事热度持续上升,相关产业迎来新发展