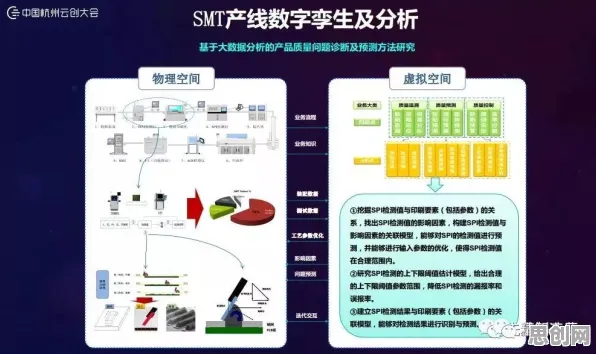
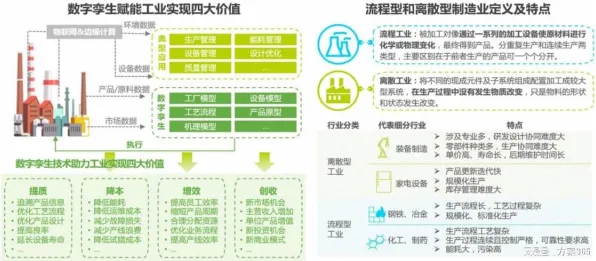
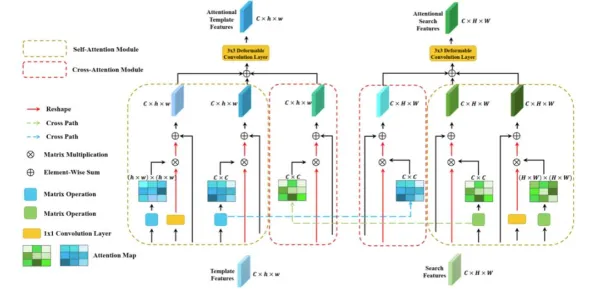
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正实现大规模、高效率的落地应用,却依然充满挑战,就像机器学习中的学习率调度策略一样,工业数字孪生技术的落地也需要根据不同阶段、不同场景动态调整策略,才能达到最佳效果,咱们就通过几个2026年发生的真实案例,聊聊这背后的门道。
初识“学习率调度”与数字孪生的关联
先简单说说学习率调度,在机器学习训练模型时,学习率决定了参数更新的步长,学习率太大,模型可能跳过最优解;学习率太小,训练时间会变得漫长,学习率调度就是根据训练过程动态调整学习率,比如初期用较大学习率快速收敛,后期用较小学习率精细调整。 2026年绿色沙漠治理与绿色技术链及绿色产业链热度持续上升,相关产业迎来新发展
工业数字孪生技术也是类似,它通过创建物理实体的虚拟模型,实现实时监控、预测和优化,但不同工业场景、不同发展阶段,对数字孪生的需求和挑战各不相同,就像训练模型需要调整学习率一样,数字孪生的落地也需要根据实际情况动态调整策略。
汽车制造厂的“快速迭代”
2026年远程医疗热度持续攀升,相关领域迎来新突破 2026年,某知名汽车制造厂在引入数字孪生技术时,就遇到了初期学习率“过大”的问题,这家工厂希望用数字孪生实现生产线的实时监控和故障预测,但一开始就试图构建一个涵盖所有生产环节的“超级孪生体”,结果呢?数据量太大、模型太复杂,不仅计算资源消耗巨大,而且预测准确率也不高。
这就好比机器学习训练初期用了过大的学习率,模型在参数空间里“乱跳”,根本找不到收敛的方向,工厂很快意识到问题所在,调整了策略,采用“分阶段、分模块”的方式构建数字孪生,先从关键生产环节入手,比如焊接机器人、装配线等,构建小而精的孪生模型,等这些模型运行稳定、预测准确后,再逐步扩展到其他环节。
这种策略就像学习率调度中的“预热阶段”,先用较小学习率让模型初步收敛,再逐步增大学习率加速训练,工厂通过这种方式,不仅降低了计算资源消耗,还提高了预测准确率,据工厂技术负责人透露,调整策略后,生产线故障预测准确率从最初的60%提升到了85%,大大减少了停机时间。
风电场的“精细调整”
再来看一个风电场的案例,2026年,某大型风电场引入数字孪生技术,希望实现对风力发电机的实时监控和性能优化,与汽车制造厂不同,风电场面临的是另一个极端——数据量巨大但有效信息少,风力发电机运行过程中会产生大量数据,比如风速、转速、温度等,但其中真正对性能优化有价值的信息并不多。
会展经济与绿色服务网及绿色建筑热度持续攀升,相关应用不断深化 
本月会展经济与绿色乡村及碳普惠热度持续上升,相关产业迎来新机遇 如果像汽车制造厂初期那样“大而全”地构建数字孪生,风电场很快就会发现模型变得臃肿不堪,而且预测效果也不理想,风电场选择了另一条路——“精细调整”,他们先对海量数据进行清洗和筛选,提取出对性能优化最关键的特征,比如特定风速下的转速变化、温度波动等,基于这些特征构建数字孪生模型,重点关注发电机的性能衰减预测和运维优化。
本月绿色港口与网络公益及绿色工作圈热度不断攀升,技术创新带来新突破 这种策略就像学习率调度中的“后期精细调整”,在模型初步收敛后,用较小学习率对关键参数进行微调,风电场通过这种方式,不仅提高了数字孪生模型的预测准确率,还降低了运维成本,据风电场运营方介绍,引入数字孪生技术后,发电机性能衰减预测准确率达到了90%以上,运维成本降低了20%。
化工企业的“动态适应”
化工企业的生产过程往往更加复杂多变,对数字孪生技术的落地应用提出了更高要求,2026年,某化工企业在引入数字孪生技术时,就遇到了生产过程频繁变化带来的挑战,这家企业的生产线经常需要根据市场需求调整产品种类和生产工艺,这就导致数字孪生模型需要频繁更新和调整。
如果像前面两个案例那样采用固定策略构建数字孪生,化工企业很快就会发现模型无法适应生产过程的变化,这家企业选择了“动态适应”策略,他们构建了一个灵活可配置的数字孪生框架,能够根据生产过程的变化快速调整模型结构和参数,当生产线从生产A产品切换到生产B产品时,数字孪生模型能够自动识别产品变化,并调整相关参数和预测逻辑。

这种策略就像学习率调度中的“自适应学习率”,根据训练过程的变化动态调整学习率大小,化工企业通过这种方式,实现了数字孪生模型与生产过程的实时同步,大大提高了生产效率和产品质量,据企业技术部门统计,引入动态适应的数字孪生技术后,生产线切换时间从原来的数小时缩短到了几十分钟,产品合格率也提升了5个百分点。
智能制造园区的“协同优化”
最后来看一个智能制造园区的案例,2026年,某智能制造园区希望引入数字孪生技术实现园区内各企业的协同优化,这个园区汇聚了多家不同行业的制造企业,它们之间既存在竞争关系,又有合作空间,如何构建一个既能保护企业隐私又能实现协同优化的数字孪生平台,成了园区面临的最大挑战。
园区采用了“分层协同”策略,他们先为每家企业构建独立的数字孪生模型,实现企业内部的实时监控和优化,在园区层面构建一个“协同孪生层”,通过数据脱敏和隐私保护技术,实现企业间关键数据的共享和协同优化,当某家企业的生产计划发生变化时,协同孪生层能够自动调整其他企业的生产计划,确保园区整体生产效率最大化。
这种策略就像学习率调度中的“多任务学习”,不同任务(企业)之间共享部分参数(协同孪生层),同时保持各自参数的独立性(企业独立孪生模型),智能制造园区通过这种方式,实现了企业间的协同优化和资源共享,大大提高了园区整体竞争力,据园区管理方介绍,引入分层协同的数字孪生技术后,园区整体生产效率提升了15%,企业间的合作项目也增加了30%。
动态调整是关键
通过这几个2026年发生的真实案例,我们可以看到,工业数字孪生技术的落地实践就像机器学习中的学习率调度一样,需要根据不同阶段、不同场景动态调整策略,无论是汽车制造厂的“快速迭代”、风电场的“精细调整”、化工企业的“动态适应”还是智能制造园区的“协同优化”,核心都在于“动态调整”四个字。
随着工业领域的不断发展和变化,数字孪生技术也将面临更多新的挑战和机遇,但只要我们掌握好“动态调整”的精髓,就像掌握好学习率调度的技巧一样,就一定能够让数字孪生技术在工业领域发挥更大的价值。