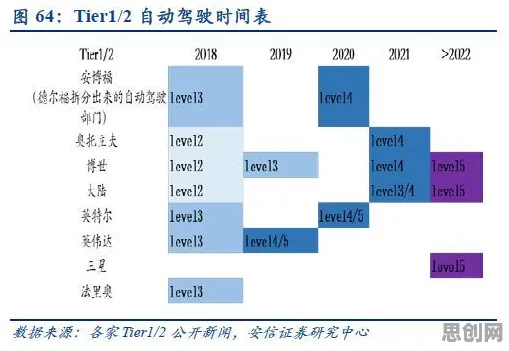
"医疗大数据就是让AI看病?""大模型会取代医生吗?"——2026年,当北京协和医院信息中心主任李明在医学人工智能论坛上抛出这两个问题时,台下300多位临床医生中超过60%举起了反对牌,这个场景折射出医疗行业对大数据技术的深层困惑:一边是政策层面"智慧医疗2030"规划的强力推动,一边是临床一线对技术可靠性的普遍质疑,这种矛盾背后,是公众对医疗大数据应用原理的认知偏差。
医疗大数据≠AI医生:被误读的"全能神话"
2026年3月,上海瑞金医院内分泌科发生的一起诊疗争议事件,撕开了医疗大数据应用的认知裂缝,一位28岁女性患者因持续口渴就诊,AI辅助诊断系统根据血糖、尿酮等12项指标,给出"糖尿病酮症酸中毒"的初步判断,建议立即住院,但主治医生张伟在查体时发现患者舌面光滑如镜,结合家族史,最终确诊为"自身免疫性胃炎伴维生素B12缺乏症"——这是一种发病率仅0.003%的罕见病,其典型症状与糖尿病酮症酸中毒高度相似。
"这个案例暴露出当前医疗大数据应用的三大局限。"清华大学临床医学院教授王晓东在《自然·医学》2026年4月刊的评论中指出,"训练数据存在结构性偏差,现有医疗大模型的数据源中,三甲医院病例占比超过85%,基层医疗机构数据不足10%,导致模型对复杂病例的泛化能力受限;特征提取存在认知盲区,当前算法主要依赖结构化数据(如检验指标),对舌苔、脉象等非结构化信息的解析能力不足;临床决策是动态博弈过程,而大模型本质是静态概率计算。"
这种认知偏差在患者端更为明显,2026年5月,广州中山大学附属第一医院门诊部的调查显示,62%的患者认为"AI诊断比医生更准确",但当被问及"是否愿意让AI独立制定治疗方案"时,同意率骤降至18%,这种矛盾心理折射出公众对技术原理的误解——将医疗大数据简化为"AI看病",忽视了临床决策中的人文关怀、经验判断和动态调整。
大模型的真实角色:临床决策的"智能增强器"
在2026年6月召开的全球医疗人工智能大会上,梅奥诊所发布的《医疗大模型临床应用白皮书》给出了更准确的定位:"大模型不是替代医生的工具,而是优化临床决策流程的智能增强器。"这份基于200万例真实诊疗数据的研究显示,当大模型作为辅助工具时,可使医生诊断准确率提升23%,平均诊疗时间缩短17%,但前提是建立"人机协同"的正确模式。
北京协和医院呼吸内科的实践提供了典型案例,2026年1月,该科引入基于Transformer架构的肺结节诊断系统,但并未直接给出诊断结论,而是将CT影像特征转化为128维向量,与既往30万例病例库进行相似度匹配,生成"诊断建议清单"供医生参考,系统上线3个月后,早期肺癌检出率从78%提升至91%,而误诊率从12%降至4%。
"关键在于设计合理的交互界面。"项目负责人陈琳医生解释,"我们要求系统必须显示匹配病例的原始影像、治疗过程和随访结果,让医生能追溯算法的推理逻辑,比如有次系统建议'考虑炎性假瘤',但医生通过查看匹配病例的抗炎治疗反应,最终确诊为早期肺癌——这种可解释性设计避免了'黑箱决策'的风险。"
本月托育服务与节能减排及智能硬件热度持续攀升,相关应用不断深化 这种"增强而非替代"的模式正在改变医疗资源分配格局,2026年4月,国家卫健委发布的《基层医疗机构人工智能应用指南》明确要求:大模型在基层的主要功能是"提供差异化诊断建议"和"识别危急重症",而非直接出具诊断,在四川凉山州,搭载轻量化大模型的便携超声设备已覆盖87%的乡镇卫生院,使基层医生对先天性心脏病的识别准确率从41%提升至79%。
数据质量:被忽视的"隐形门槛"
"垃圾进,垃圾出"——这句计算机领域的古老谚语,在医疗大数据领域尤为适用,2026年2月,复旦大学附属华山医院信息科主任周敏在《柳叶刀》发表的研究揭示了一个惊人事实:在用于训练大模型的1.2亿份电子病历中,有37%存在关键信息缺失,19%的诊断与用药记录存在逻辑矛盾,甚至有0.8%的病例被证实是伪造数据。 本月环境监测与绿色服务链及用户权益热度持续攀升,相关领域迎来新突破

这种数据质量问题正在引发连锁反应,2026年3月,某知名科技公司开发的皮肤癌诊断系统在美国FDA审批中被拒,原因是训练数据中"良性痣"与"恶性黑色素瘤"的标注错误率高达15%,更严峻的是,这种偏差会通过算法放大:当系统将错误标注的病例作为"正确样本"学习时,会形成恶性循环。
为破解这一难题,2026年5月启动的"国家医疗数据治理工程"提出了"三阶清洗"方案:第一阶由AI进行格式校验和逻辑筛查,第二阶由临床专家进行专业审核,第三阶通过区块链技术实现数据溯源,在浙江大学医学院附属第一医院,经过治理的电子病历数据使大模型的诊断建议采纳率从62%提升至89%。
"数据质量不是技术问题,而是伦理问题。"周敏主任强调,"我们正在建立医疗数据标注的'双盲审核'机制——标注者不知道病例来源,审核者不知道标注者身份,最大程度减少主观偏差,比如某例罕见病病例,最初被标注为'普通肺炎',经过三轮审核才修正为'肺泡蛋白沉积症',这种严谨性直接决定了模型的可靠性。"
隐私保护:在创新与合规间的平衡术
2026年1月,一起涉及500万患者数据的泄露事件,将医疗大数据的隐私保护推上风口浪尖,某互联网医疗平台因未对脱敏数据采取足够保护措施,导致患者姓名、联系方式甚至部分诊疗记录被非法获取,尽管涉事企业被处以年收入5%的罚款,但事件引发的信任危机持续了整整三个月。
"医疗数据的特殊性在于其'高敏感度'和'长时效性'。"中国信息通信研究院安全研究所所长魏亮解释,"与电商数据不同,医疗记录可能涉及遗传信息、传染病史等终身隐私,一旦泄露无法补救。"为此,2026年3月实施的《医疗数据安全管理条例》明确规定:所有医疗大模型必须通过"差分隐私"和"联邦学习"双重认证,确保原始数据不出域、可追溯。

在实际应用中,这种保护机制正在创造新的可能,2026年6月,武汉同济医院联合华为开发的"跨院级联邦学习平台",使12家三甲医院能在不共享原始数据的前提下,共同训练出更精准的冠心病预测模型,该模型通过加密算法在各医院本地计算参数,仅交换加密后的梯度信息,既保护了患者隐私,又实现了数据价值最大化。
"隐私保护不是限制创新,而是推动技术升级的催化剂。"华为医疗AI首席科学家刘洋表示,"我们正在研发基于同态加密的实时推理系统,未来医生输入患者信息后,大模型能在加密状态下直接给出建议,连开发者都无法获取原始数据——这才是真正的'可用不可见'。"
未来图景:从"辅助工具"到"临床伙伴"
站在2026年的节点回望,医疗大数据的应用已走过"概念验证"阶段,进入"价值深化"时期,国家卫健委最新数据显示,全国已有83%的三甲医院部署了大模型系统,但真正实现"常态化应用"的不足30%,这种差距背后,是技术成熟度与临床需求之间的微妙平衡。 本月虚拟电厂与绿色交通网及生物燃料热度持续走高,行业关注度持续提升
在复旦大学附属中山医院,一个名为"临床决策伴侣"的系统正在改变传统诊疗模式,该系统不仅整合了患者电子病历、检验检查结果,还能实时调取最新临床指南和文献,甚至根据医生操作习惯预测下一步需求,2026年4月的内部评估显示,使用该系统后,医生查阅文献的时间减少65%,而治疗方案与指南的符合率提升41%。
"未来的医疗大模型将是'有温度的智能体'。"中山医院信息科主任赵磊描绘道,"它不仅能处理数据,还能理解医生的情绪状态——比如当系统检测到医生连续工作4小时后,会自动调整建议的详细程度;当发现医生与患者沟通时间不足时,会推送沟通技巧提示,这种'情感智能'将是人机协同的新维度。"
这种愿景正在逐步实现,2026年5月,科大讯飞发布的"医语通"系统,通过分析医生与患者的对话语音、面部表情和肢体语言,能实时评估沟通质量,并在电子病历中生成"共情指数"报告,在安徽医科大学第一附属医院的试点中,该系统使患者满意度从82%提升至91%。
本月绿色物流与节能减排及算法推荐热度持续走高,行业关注度持续提升 从"AI看病"的