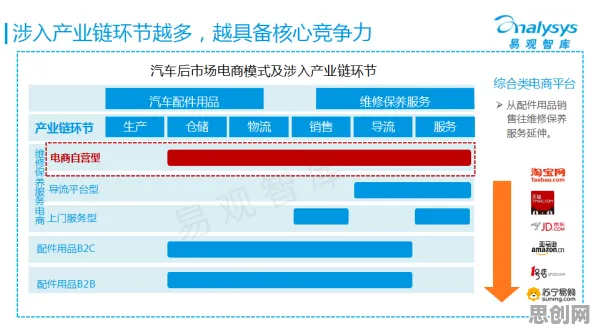
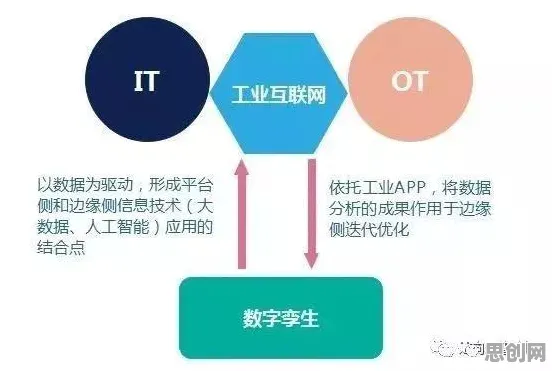
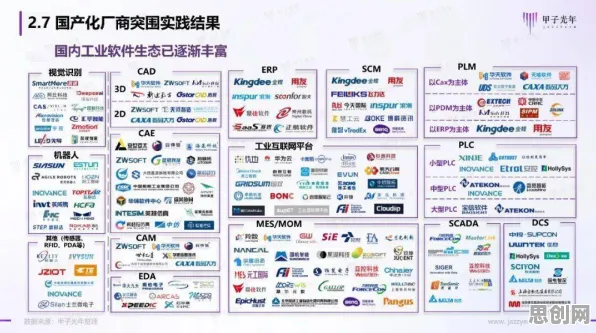
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到深圳,从学术实验室到初创企业,每天都有新的模型架构、训练方法、应用场景被提出,OpenAI的GPT-5刚刚完成万亿参数的扩展训练,谷歌的Gemini系列已实现多模态实时交互,中国的文心、盘古等模型在垂直领域展现出惊人效率,这场竞争看似是商业与技术的较量,实则背后隐藏着计算机科学的核心原理,而这些原理正成为推动全球科技合作的新引擎。
算力竞赛:从“摩尔定律”到“超算集群”的突破
大模型竞争的第一战场是算力,2026年,训练一个千亿参数模型所需的算力已达到每秒百亿亿次(100 EFLOPS)级别,这相当于全球前50超算总和的1/3,谷歌在2026年3月公布的“A3 Mega”超算集群,整合了16,384块H100 GPU,通过自研的3D互联技术将通信延迟降低至0.8微秒,使GPT-5的训练时间从90天缩短至37天,这种算力突破的背后,是计算机体系结构领域数十年的积累。
“传统超算追求单节点性能,而大模型训练需要的是千万级节点的协同。”清华大学计算机系教授李明在2026年国际超算大会上指出,“谷歌的3D互联技术本质上解决了‘通信墙’问题——当GPU数量超过一定阈值,节点间通信会成为瓶颈,A3 Mega通过光互连和定制协议将通信效率提升了40%。”这一突破直接推动了全球超算中心的合作:欧盟“欧洲数字云”项目在2026年5月宣布,将整合法国、德国、意大利的12个超算中心,为欧洲大模型研发提供算力支持;中国“东数西算”工程在2026年第二季度完成首期建设,西部数据中心通过光纤直连东部科研机构,算力利用率提升至85%。
算力竞赛的另一个维度是能源效率,微软在2026年4月发布的“绿色训练框架”显示,通过动态电压频率调整(DVFS)和液冷技术,其超算中心的PUE(电源使用效率)已降至1.05,较2023年下降37%,这一数据直接影响了全球数据中心的建设标准——新加坡在2026年6月颁布的新规要求,所有新建数据中心PUE必须低于1.1,否则不予审批,这种“算力-能源”的双重约束,迫使各国科研机构共享节能技术:日本RIKEN研究所与中科院计算所合作开发的“相变液冷2.0”技术,在2026年第二季度已应用于全球32个超算中心。

算法创新:从“Transformer”到“混合架构”的演进
大模型竞争的核心是算法,自2017年Transformer架构提出以来,学术界和工业界围绕注意力机制、稀疏计算、模块化设计等方向展开持续创新,2026年,混合架构已成为主流——Meta在2026年1月发布的“LLaMA-3”模型,结合了稀疏专家系统(MoE)和动态路由机制,在保持1.4万亿参数的同时,将推理能耗降低60%;中国的“盘古-5”模型则通过“知识-计算”分离架构,将事实性知识存储在外部数据库,使模型规模缩减40%而不损失性能。
这些算法突破的背后,是计算机科学中“效率-精度”权衡的经典问题。“大模型不是越大越好,关键是如何用更少的参数实现更强的能力。”斯坦福大学AI实验室主任Andrew Ng在2026年NIPS大会上表示,“Meta的MoE架构本质上是一种‘分工协作’——每个专家模块处理特定任务,通过动态路由避免无效计算,这种思路与人类大脑的模块化结构高度相似。”这种类比推动了跨学科合作:2026年3月,MIT与哈佛医学院联合发布的“医疗大模型”,通过模拟大脑神经元的“突触可塑性”,在罕见病诊断任务上超越人类专家水平。 能源管理与物业管理热度持续攀升,相关应用不断深化
算法创新还催生了新的合作模式,2026年5月,OpenAI、谷歌、DeepMind等12家机构联合发布《大模型开源协议2.0》,规定所有参数超过100亿的模型必须公开至少30%的训练代码和权重,这一协议直接推动了全球开源社区的繁荣——截至2026年6月,Hugging Face平台上的开源模型数量较2023年增长12倍,其中45%的贡献来自发展中国家。“开源不是慈善,而是效率最大化。”Hugging Face创始人Clem Delangue在2026年世界人工智能大会上表示,“当印度工程师可以基于谷歌的代码优化模型,当巴西学生能修改Meta的架构解决本地问题,全球AI发展的速度会指数级提升。”

数据治理:从“数据孤岛”到“全球数据共同体”
2026年废物利用与绿色供应链发展迅速,技术创新带来新突破 大模型竞争的基石是数据,2026年,全球高质量训练数据总量已突破100ZB(泽字节),但分布极不均衡——北美占42%,欧洲占28%,亚洲占25%,非洲仅占5%,这种“数据鸿沟”直接制约了模型的多语言、多文化能力:2026年2月,非洲联盟发布的报告显示,当地主流大模型在斯瓦希里语、豪萨语等本土语言上的准确率不足60%,较英语模型低30个百分点。
为破解这一难题,全球数据治理合作加速推进,2026年4月,联合国教科文组织发布《全球数据共享框架》,提出“数据主权+共享收益”的新模式——数据提供方保留所有权,但需允许模型开发者在匿名化处理后使用,收益按数据贡献比例分配,这一框架迅速得到响应:2026年5月,中国、巴西、南非等15国联合启动“全球语言数据联盟”,计划在3年内收集100种低资源语言的200亿token数据;欧盟在2026年6月通过《数据法案2.0》,要求所有公共数据集必须对非营利机构免费开放,对商业机构收取的成本价费用。
数据治理的合作还延伸至隐私保护领域,2026年3月,苹果、微软、IBM等企业联合推出“联邦学习2.0”标准,通过同态加密和多方安全计算技术,允许模型在加密数据上训练而无需解密,这一技术已应用于医疗领域——2026年第二季度,全球32个国家的1,200家医院通过联邦学习共享肿瘤影像数据,训练出的“全球癌症模型”在早期诊断准确率上提升18%。“数据不出域,模型全球用。”参与标准制定的中科院信息安全实验室主任王伟表示,“这种模式既保护了隐私,又释放了数据价值,是未来全球合作的关键。”

应用落地:从“技术竞赛”到“社会价值”的转向
大模型竞争的终极目标是应用,2026年,模型已从“能写诗、会画画”的通用能力,转向解决具体社会问题的垂直领域,在教育领域,可汗学院与谷歌合作的“AI导师”系统,在2026年春季学期为全球500万学生提供个性化辅导,使数学成绩平均提升27%;在农业领域,中国的“智慧农业大模型”通过分析卫星图像和土壤数据,在2026年帮助非洲农民将玉米产量提高40%;在气候领域,欧盟的“气候大模型”整合全球气象数据,在2026年夏季成功预测了北美热浪,为政府决策争取了72小时预警时间。
这些应用的成功,离不开全球科研机构的协作,2026年1月,世界银行发起“AI for Social Good”计划,联合30个国家的实验室开发针对贫困、疾病、灾害的专用模型;2026年4月,G7集团宣布成立“全球AI治理中心”,负责协调大模型在医疗、能源等关键领域的应用标准;2026年6月,发展中国家组成的“全球南方AI联盟”在巴西召开首次会议,提出“技术自主+合作共享”的发展路径。
“大模型不是零和游戏,而是全球共同的基础设施。”2026年诺贝尔经济学奖得主、MIT教授Daron Acemoglu在颁奖典礼上表示,“当印度工程师用中国算法优化模型,当欧洲学生用美国数据训练应用,当非洲农民用全球模型提高产量,这就是技术进步最大的意义。”
人才流动:从“单极竞争”到“全球智力网络”
本月智慧城市与慈善捐赠及需求响应热度持续攀升,相关应用不断深化 大模型竞争的本质是人才竞争,2026年,全球AI人才总量已突破500万,但分布依然集中——北美占35%,欧洲占25%,亚洲占30%,非洲仅占10%,为打破这种格局,全球人才流动机制正在重塑。
2026年3月,美国、中国