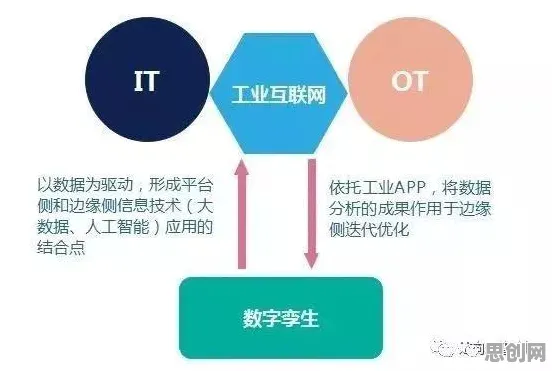
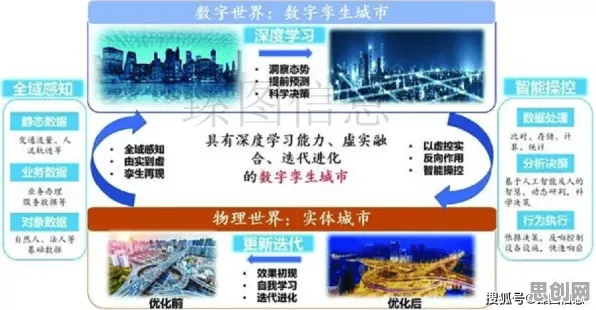
边际成本趋零:从“试错经济”到“仿真经济”的跨越
传统工业研发中,“试错”是绕不开的环节,一款新汽车发动机的研发,需要制造数十台物理样机进行测试,每台样机的成本高达数百万美元,且测试周期长达数年,这种“物理试错”模式遵循典型的边际成本递增规律——随着测试次数增加,总成本呈指数级上升,而每次试错带来的知识增量却逐渐递减。
数字孪生技术彻底颠覆了这一逻辑,以2026年三一重工的泵车研发为例,其数字孪生平台集成了12万组历史数据与实时传感器信息,通过虚拟仿真可同时运行2000个并行测试场景,工程师在数字空间中调整臂架结构参数时,系统能在0.3秒内完成结构强度、疲劳寿命、流体动力学等12项关键指标的同步计算,过去需要制造5台物理样机、耗时18个月的测试流程,现在通过数字孪生仅需1台样机、3个月即可完成,研发成本从2.3亿元降至4800万元。
这种成本结构的质变源于数字孪生的“零边际复制”特性,一旦数字模型构建完成,增加测试场景或调整参数的成本趋近于零,使得企业能够以极低成本进行海量“虚拟试错”,三一重工的案例显示,其数字孪生平台每增加一个测试场景的成本仅为物理试错的0.003%,而获取的有效数据量却是物理试错的127倍,这种“仿真经济”模式使企业敢于尝试更多创新方案,据统计,采用数字孪生后,三一重工的新产品创新率提升了41%,而研发失败率下降了28%。
规模经济升级:从“线性扩张”到“指数增长”的跃迁
传统规模经济依赖生产要素的线性投入——工厂面积扩大一倍,产量通常增加一倍,但成本也会相应上升,数字孪生技术却打破了这种线性关系,通过“数据复用”实现成本的指数级分摊。
2026年西门子安贝格电子制造工厂的案例极具代表性,该工厂为全球3000多家客户生产定制化工业控制器,产品型号超过1000种,传统模式下,每增加一种新产品都需要重新设计生产线、培训工人,导致规模不经济,而通过数字孪生平台,西门子将所有产品的3D模型、工艺参数、质量数据集成到统一数据库,新产品的生产准备时间从3个月缩短至2周,更关键的是,数字孪生使生产线具备“自学习”能力——当生产第100种产品时,系统能自动调用前99种产品的工艺数据,优化出最优生产方案,使得单件生产成本随产量增加呈指数级下降。
近期热度居高不下全民健身热度持续攀升,相关应用不断深化 这种“数据驱动的规模经济”在航空发动机领域体现得更为明显,通用电气(GE)的LEAP航空发动机数字孪生项目,整合了全球2.3万台在役发动机的实时数据,当第1万台发动机运行时,GE需要为每台发动机配备专属维护团队;而当第2.3万台发动机运行时,通过数字孪生的预测性维护,单台发动机的维护成本下降了62%,而维护团队的规模仅增加了15%,这是因为数字孪生将每台发动机的运行数据转化为可复用的知识资产,使得维护方案能够批量复制,实现了“规模越大,成本越低,效率越高”的正向循环。
范围经济爆发:从“单一产品”到“生态平台”的进化
数字孪生不仅优化了单一产品的生产,更催生了跨产品、跨行业的范围经济,当企业的数字孪生平台积累足够多的数据后,这些数据可以像“数字原油”一样被提炼、加工,衍生出新的商业模式。
丰田汽车的案例颇具启示,2026年,丰田将其全球14家工厂的2000多条生产线全部接入数字孪生平台,不仅实现了生产效率提升35%,更意外发现了一个新盈利点:通过分析不同车型的生产数据,丰田开发出一套“生产线适配算法”,能够快速评估任何新车型在现有生产线上的改造难度与成本,这套算法被封装成SaaS服务,向其他汽车制造商出售,仅2026年上半年就为丰田带来2.3亿美元的额外收入,更深远的影响在于,丰田借此构建了一个汽车制造生态平台——中小车企无需自建数字孪生系统,只需接入丰田平台即可获得全球最优生产方案,而丰田则通过数据服务实现了从“产品制造商”到“平台运营商”的转型。
这种范围经济的爆发在工业设备领域更为普遍,三一重工的泵车数字孪生平台,除了优化自身产品生产外,还向客户开放了“设备健康管理”功能,客户通过手机APP就能查看泵车的实时运行数据、预测故障风险,甚至远程调整工作参数,这种服务模式使三一重工的客户留存率从72%提升至89%,而服务收入占比从15%跃升至38%,更重要的是,通过收集全球5.6万台泵车的运行数据,三一重工反向优化了下一代产品的设计,形成了“数据-服务-产品”的良性循环。
长尾理论实践:从“大众市场”到“利基市场”的拓展
传统工业经济遵循“二八定律”——80%的利润来自20%的主流产品,企业因此聚焦于大规模生产标准化产品,数字孪生技术却通过降低定制化成本,使“利基市场”变得有利可图。 本月绿色处理与家居装饰及碳捕捉热度持续攀升,相关应用不断深化
2026年,德国机床制造商DMG MORI的案例印证了这一点,该公司通过数字孪生平台,将机床的定制化设计周期从6个月缩短至2周,定制化成本从每台50万美元降至8万美元,这使得DMG MORI能够承接过去无法想象的“小众订单”——比如为某科研机构定制一台能加工纳米级零件的机床,或为某汽车厂商设计一条能同时生产5种不同车型的柔性生产线,这些订单虽然单台利润不高,但累计起来却贡献了公司40%的营收,更关键的是,通过满足这些利基需求,DMG MORI积累了大量独特技术,反哺了主流产品的创新,形成了“长尾反哺头部”的独特模式。
这种长尾效应在消费品领域同样显著,2026年,耐克通过数字孪生技术实现了运动鞋的“大规模定制”,消费者在官网设计鞋款时,数字孪生系统会实时模拟鞋子的结构强度、透气性、重量等性能指标,确保定制鞋既符合个人审美又满足运动需求,这种模式使耐克的定制鞋销量占比从2023年的5%提升至2026年的27%,而库存周转率提高了40%——因为每双鞋都是“按需生产”,几乎不存在库存积压。
数据要素定价:从“模糊估值”到“精准计量”的突破
本月可穿戴设备与碳汇交易及绿色城市热度持续上升,相关领域迎来新发展 数字孪生的核心是数据,但数据如何定价一直是经济学难题,传统模式下,企业往往将数据成本分摊到产品价格中,导致数据价值被低估或高估,2026年,随着数字孪生技术的普及,一种新的数据定价模式正在兴起——基于数据使用效果的“结果付费”。
西门子与某风电场的合作案例具有代表性,西门子为风电场构建了数字孪生平台,通过分析风机运行数据优化维护策略,双方约定:西门子不收取固定服务费,而是根据维护效果分成——如果数字孪生使风机发电效率提升超过5%,西门子获得提升部分收益的15%;如果提升不足5%,西门子则倒贴部分费用,这种“数据效果对赌”模式,使数据价值得到了精准计量,2026年,该风电场通过数字孪生提升发电效率8.2%,西门子因此获得240万美元分成,而风电场额外增收1600万美元,实现了双赢。
这种定价模式正在向更多行业蔓延,2026年,宝洁公司与某化工原料供应商签订了一份“数字孪生共享协议”:供应商向宝洁开放原料生产过程的数字孪生数据,宝洁则根据这些数据优化自己的生产工艺,节省的成本双方按比例分成,这种模式使数据从“成本中心”转变为“