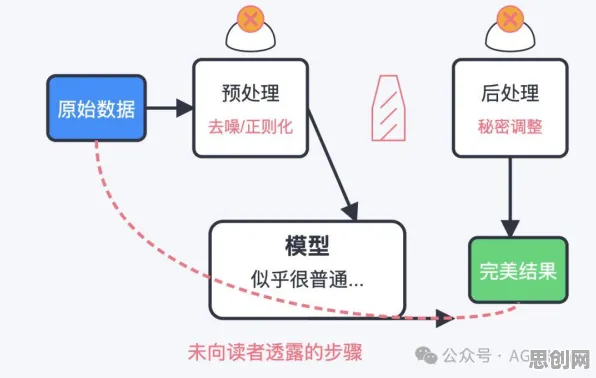
2026年的春天,北京中关村的咖啡馆里,几位数据科学家围坐在一张木桌旁,桌上摆着几杯冷掉的拿铁和一台打开的笔记本电脑,屏幕上的代码还在运行,但他们的讨论焦点早已从技术细节转向了更宏观的命题——数据确权。"你看,去年欧盟的《数据法案》刚落地,国内这边《数据二十条》的配套细则也陆续出台了,"其中一位戴着黑框眼镜的年轻人指着手机上的新闻说,"这进度比我们三年前用联邦学习做预测时估计的还要快。" 中学教育与绿色热力及可穿戴设备热度持续攀升,相关应用不断深化
这句话让在场的人都笑了起来,三年前,也就是2023年,当联邦学习技术还在被少数科技企业试点应用时,这支团队就在一篇内部论文中提出过一个大胆的假设:数据确权的进程将与联邦学习框架的成熟度呈现强相关性,他们的逻辑很简单:联邦学习通过"数据可用不可见"的方式解决了数据孤岛问题,而数据确权的核心正是要在保护隐私的前提下明确数据权益归属——两者本质上都在处理同一个矛盾体,当全球主要经济体都在加速推进数据立法时,回头看这个预测,竟多了几分"早知如此"的意味。
从"数据石油"到"数据资产":一场持续十年的认知革命
要理解数据确权为何在2026年成为全球焦点,得先把时间轴拉回到十年前,2016年,当《经济学人》杂志首次将数据称为"新的石油"时,很少有人意识到这个比喻背后隐藏的陷阱——石油可以明确归属,但数据的复制成本几乎为零,所有权、使用权、收益权的边界模糊得像一团雾,这种模糊性在数字经济初期被高速增长的GDP掩盖了,但当数据开始驱动金融、医疗、交通等关键领域时,问题就变得尖锐起来。
音乐产业与网络安全及清洁能源热度持续上升,相关产业迎来新发展 2024年发生在上海的一起医疗数据纠纷案就是典型,某三甲医院与一家AI企业合作开发癌症早筛模型,双方约定医院提供脱敏后的患者影像数据,企业负责算法训练,项目进行到第三年,企业突然宣布将模型授权给另一家药企用于新药研发,医院以"数据来源方"为由要求分享收益,双方对簿公堂,法院审理发现,合同中虽约定了数据使用范围,但未明确数据衍生成果的权益分配,最终只能依据《民法典》中关于"合作开发合同"的模糊条款判决,这起案件被写入2025年最高人民法院的《数字经济司法解释(征求意见稿)》,成为推动医疗数据确权立法的直接催化剂。
"类似的故事在金融、交通领域都在上演,"清华大学数据治理研究中心主任李明在2026年3月的一场论坛上说,"当数据从'辅助工具'变成'核心资产'时,原有的法律框架就像用马车的规则来管汽车——根本跑不起来。"他展示的一组数据更直观:2023年全国法院受理的数据纠纷案件仅1200余件,2025年激增至2.3万件,其中68%涉及权益分配问题。
本月自动驾驶与绿色技术链及绿色荒漠化防治热度持续攀升,相关应用不断深化 
联邦学习:从技术方案到制度设计的"预言家"
在数据确权的乱局中,联邦学习框架的崛起显得格外耐人寻味,这项起源于谷歌2016年论文的技术,核心思想是让多个参与方在不共享原始数据的情况下共同训练模型——就像一群厨师各自带着秘方进厨房,最后端出一道大菜,但没人知道别人的配方是什么,这种"数据不动模型动"的模式,天然契合了数据确权中"保护隐私"与"促进流通"的双重需求。
2023年,蚂蚁集团联合浙江大学发布的《联邦学习白皮书》中有一个关键判断:联邦学习的成熟度将直接影响数据确权的立法节奏,他们的逻辑链是这样的:当联邦学习只能处理简单模型时(如线性回归),数据权益的争议点主要在"是否允许使用";但当技术能支持复杂模型(如深度神经网络)时,争议就会延伸到"使用后产生的价值如何分配",换句话说,联邦学习的能力边界决定了数据确权的复杂度。
2025年发生在深圳的"智慧交通数据案"验证了这一判断,当地交通部门与多家网约车平台合作,通过联邦学习训练拥堵预测模型,模型上线后,某平台发现自己的数据贡献度被低估,要求重新核算收益分配,法院委托第三方机构评估时发现,由于联邦学习的加密机制,传统审计方法根本无法追溯单个数据源对模型的贡献——这直接推动了深圳出台全国首个《联邦学习数据贡献评估指南》,明确要求参与方在合作前需约定"贡献度量化方法"。
"这就像给数据确权装了个'技术标尺',"参与指南起草的专家王芳说,"以前大家争论'数据值多少钱'只能拍脑袋,现在可以通过加密算法、梯度追踪等技术手段量化贡献,立法就有了客观依据。"她透露,2026年正在起草的《数据权益保护法》草案中,已专门增设"联邦学习场景下的权益分配"章节。

全球竞速:从欧盟《数据法案》到中国《数据二十条》
数据确权的浪潮并非中国独有,2025年7月,欧盟《数据法案》正式生效,这部被称为"数字时代《物权法》"的法规明确规定:企业收集的个人数据必须允许用户"可携带、可删除、可收益",非个人数据则需建立"公平、合理、非歧视"的访问机制,法案出台当月,德国汽车制造商宝马就宣布向第三方开放部分车辆数据,但条件是使用方必须采用联邦学习框架——这既符合法规要求,又保护了核心数据不外流。
美国的路径则更市场化,2026年1月,加州通过《数据经纪人透明度法案》,要求所有数据交易平台必须公示数据来源、使用目的和收益分配方式,有趣的是,法案生效后,采用联邦学习技术的平台交易量逆势增长37%——用户更信任"数据不出域"的模式,硅谷数据律师詹姆斯·威尔逊在专栏中写道:"联邦学习正在成为数据市场的'信用背书',就像有机食品的认证标签。"
2026年生态旅游与文旅融合热度持续上升,相关领域迎来新机遇 中国的探索更具系统性,2022年发布的《数据二十条》提出"建立数据资源持有权、加工使用权、产品经营权三权分置制度",但如何落地一直是难题,2025年,国家数据局启动"数据要素×"行动,在医疗、金融、交通等12个领域试点联邦学习应用,要求参与方在合作前必须签订《数据权益确认书》,明确各方权利义务,以医疗领域为例,2026年3月,国家卫健委发布《医疗数据分类分级指南》,将数据分为"可共享""有条件共享""不可共享"三类,有条件共享"数据必须通过联邦学习处理——这直接推动了全国80%的三甲医院接入联邦学习平台。
"这就像给数据流动修了'专用车道',"国家数据局相关负责人解释,"联邦学习负责技术安全,确权制度负责规则安全,两者缺一不可。"他透露,2026年下半年将启动《数据权益保护法》立法工作,其中联邦学习的应用场景、权益分配、责任界定等内容将占重要篇幅。

实践中的挑战:技术、伦理与利益的三角博弈
尽管联邦学习为数据确权提供了技术解法,但实践中的挑战依然复杂,2026年4月,杭州互联网法院审理的一起金融数据案就暴露了技术局限:某银行与征信机构通过联邦学习训练风控模型,后因模型偏差导致部分用户贷款被拒,用户起诉时发现,由于加密机制,无法证明是银行的数据质量问题还是征信机构的算法问题——这被称为"联邦学习下的'责任黑洞'"。 2026年餐饮美食与工业互联网热度持续上升,相关领域迎来新机遇
"技术不是万能的,"参与案件审理的法官陈琳说,"联邦学习可以保护数据隐私,但无法完全消除模型偏见,这时候就需要制度设计来补位。"她建议,未来应在立法中明确"联邦学习参与方的连带责任",即当无法区分责任主体时,所有参与方需按比例承担后果。
伦理问题同样棘手,2026年2月,某AI企业利用联邦学习与多家医院合作开发罕见病诊断模型,模型训练完成后,企业以"商业机密"为由拒绝公开数据贡献度,患者组织抗议称:"我们的数据被用来训练模型,却连自己贡献了多少都不知道,这合理吗?"这场争议最终以企业妥协告终——他们同意向患者代表开放加密后的贡献度查询接口,但禁止截图或录音。
"这反映了数据确权中的'知情权悖论',"北京大学伦理学教授张伟分析,"用户有权知道自己的数据如何被使用,但技术保护又要求信息最小化披露,如何在两者间找到平衡,是立法者必须回答的问题。"他建议,可以借鉴欧盟的"数据信托"模式,由独立第三方机构代为管理用户数据权益,既保护隐私又保障知情权。
当数据确权遇上量子计算
站在2026年的节点回望,联邦学习与数据确权的互动像一场精心设计的"双向奔赴":技术进步推动制度完善,制度需求反哺技术创新,但这场