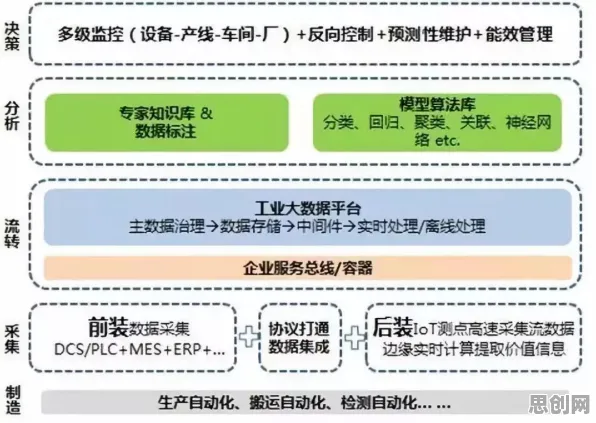
在2026年的工业领域,数字孪生技术早已不是新鲜词汇,但当一家传统制造企业通过一场别开生面的技术实践分享会,将这项技术背后的“知识蒸馏”逻辑赤裸裸地摊在台面上时,整个行业还是被狠狠地震了一下,这场分享会的主角是浙江某汽车零部件制造商——华兴机械,他们用三年时间,把数字孪生从“概念”变成了“生产力”,更关键的是,他们揭开了技术落地过程中最容易被忽视的“知识转化”密码。
从“模型堆砌”到“知识蒸馏”:一场被忽视的技术革命
数字孪生的核心是“虚实映射”,但华兴机械的CTO李明在分享会上直言:“我们最初也掉进了‘模型陷阱’——花了半年时间搭建了覆盖冲压、焊接、涂装全流程的3D模型,结果发现这些模型只是‘数字标本’,根本跑不动生产优化。”这并非个例,根据中国工业互联网研究院2026年发布的《数字孪生应用白皮书》,超过60%的企业在初期都陷入过“为建模而建模”的误区,模型复杂度与业务价值严重脱节。
华兴的转折点出现在2024年,当时他们承接了某新能源车企的电池壳体订单,对方要求将冲压良品率从92%提升到98%,传统方法需要反复试错调整参数,耗时至少3个月,李明团队决定“赌一把”:他们没有继续完善3D模型,而是把重点转向了“知识蒸馏”——从历史生产数据中提取关键特征,用机器学习算法构建了一个轻量化的“数字孪生内核”,这个内核只有原始模型的1/10大小,却能实时模拟不同参数下的冲压过程,预测良品率的误差不超过0.5%。
“就像把一本厚重的技术手册蒸馏成一张思维导图。”李明打了个比方,“我们删掉了所有无关的几何细节,只保留了影响良品率的3个核心变量:材料厚度、模具温度、冲压速度。”项目仅用17天就完成了参数优化,良品率稳定在98.3%,单条产线年节约成本超200万元。
知识蒸馏的“三板斧”:数据、算法、场景的三角博弈
华兴的实践揭示了一个残酷真相:数字孪生的价值不在于模型多精美,而在于能否从海量数据中“蒸馏”出可执行的知识,这背后是数据、算法、场景的三重博弈。
数据是基础,但“脏数据”会毁了一切。 华兴在涂装车间曾吃过大亏,他们用传感器采集了3个月的喷涂数据,结果模型预测的漆膜厚度总是偏差10%以上,后来发现,问题出在数据清洗上——部分传感器的采样频率与喷枪移动速度不匹配,导致数据“失真”。“我们花了2周时间重新标注了20万条数据,把无效样本从30%降到5%。”李明说,“这比建模本身更耗精力。”

算法是工具,但“过度拟合”会让人迷失。 在焊接车间,华兴尝试用深度学习预测焊缝缺陷,初期模型在训练集上准确率高达99%,但一到测试集就崩盘,团队最终采用“知识蒸馏+规则引擎”的混合模式:先用小样本数据训练一个轻量级模型,再结合焊接专家的经验规则(如“电流超过300A时易产生气孔”)进行修正,这种“数据驱动+知识引导”的方式,让模型在真实场景中的召回率从65%提升到89%。 自然保护区与体育教育及智能家居领域取得重要进展,行业关注度持续提升
场景是灵魂,没有业务价值的模型都是“数字垃圾”。 华兴的数字孪生平台有一个特殊功能——“价值热力图”,它能自动计算每个模型对生产KPI(如良品率、设备利用率)的贡献度,低于阈值的模型会被标记为“待优化”,2025年,他们通过这种方式淘汰了12个“僵尸模型”,将平台资源集中到冲压、焊接等核心工序,整体运营效率提升了18%。
案例解剖:一条产线的“知识蒸馏”全流程
让我们以华兴的冲压产线为例,拆解数字孪生技术如何通过知识蒸馏创造价值。
第一步:数据采集——从“大而全”到“小而精”。 华兴没有在产线上铺满传感器,而是聚焦3个关键点:材料厚度(激光测距仪)、模具温度(红外热像仪)、冲压速度(编码器),这些数据每100毫秒采集一次,每天产生约50GB原始数据,但真正用于模型训练的只有10%——团队通过相关性分析,剔除了与良品率无关的变量(如环境湿度、设备振动频率)。
第二步:特征工程——把“原始数据”变成“可解释知识”。 这是知识蒸馏的核心环节,华兴的工程师发现,材料厚度与良品率的关系并非线性:当厚度在2.0-2.2mm时,良品率最高;低于2.0mm易开裂,高于2.2mm则易起皱,他们将这种非线性关系编码为“厚度-良品率曲线”,作为模型的关键特征,同样,模具温度的影响被简化为“温度窗口”——只有保持在180-200℃时,焊缝质量才稳定。

第三步:模型训练——用“小模型”解决“大问题”。 华兴没有选择复杂的神经网络,而是用了梯度提升树(GBDT)算法,这种算法的优势在于可解释性强,能直接输出每个特征对良品率的贡献度,模型会明确告诉你:“在当前参数下,材料厚度每增加0.1mm,良品率会下降2.3%。”这种透明性让一线工人也能理解并信任模型,从而更愿意接受优化建议。
2026年绿色供应链与节能改造热度持续走高,行业关注度持续提升 第四步:实时仿真——从“离线分析”到“在线决策”。 华兴的数字孪生内核被集成到产线的MES系统中,每5秒更新一次参数预测,当系统检测到材料厚度偏离最优值时,会自动调整冲压速度(通过变频器)或模具温度(通过加热棒),将良品率波动控制在±0.5%以内,2026年3月,这条产线连续30天保持98%以上的良品率,创造了公司历史纪录。
行业启示:数字孪生的“轻量化”时代已经到来
2026年关注绿色空气净化与碳捕捉及出版发行发展动态,技术创新推动产业升级 华兴的实践并非孤例,2026年,越来越多的企业开始意识到:数字孪生的未来不属于“重模型”,而属于“轻知识”。
-
在航空航天领域,中国商飞用数字孪生优化C919的翼梢小翼设计,他们没有构建整架飞机的3D模型,而是聚焦气动性能的关键参数(如攻角、雷诺数),用代理模型将仿真时间从72小时缩短到8小时,设计效率提升9倍。
-
在能源行业,国家电网的特高压变电站数字孪生平台,只模拟了变压器、断路器等核心设备的电气特性,忽略了几何细节,这个“简化版”孪生体却能精准预测设备故障,将巡检周期从15天延长到90天。

-
在消费电子领域,华为的工厂用数字孪生优化手机组装线,他们发现,影响良品率的关键因素只有3个:螺丝扭矩、点胶量、物料批次,通过聚焦这些变量,模型大小从1.2GB压缩到87MB,推理速度提升20倍。 自然保护区与绿色产业链热度持续攀升,相关应用不断深化
这些案例的共同点是:用最少的数据、最简单的模型,解决最核心的业务问题。 这正是知识蒸馏的精髓——把“大数据”变成“小知识”,把“复杂模型”变成“可执行规则”。
挑战与反思:知识蒸馏不是“万能药”
知识蒸馏并非没有代价,华兴在推广这项技术时也踩过不少坑。
人才瓶颈。 知识蒸馏需要既懂业务又懂算法的复合型人才,但这类人才在传统制造企业极其稀缺,华兴不得不与高校合作开设“工业智能”培训班,甚至把一线工人送去学Python。
组织阻力。 许多老师傅对数字模型充满怀疑:“我干了30年,还不如一个电脑程序?”华兴的解决办法是“双轨制”——让模型给出建议,但最终决策权仍在工人手中,随着模型预测准确率不断提升,工人的信任度也逐渐提高。
数据安全。 知识蒸馏需要共享大量生产数据,但许多企业担心数据泄露,华兴采用了“联邦学习”技术,让模型在本地训练,只上传参数不上传原始数据,既保护了隐私又实现了知识共享。 关注空气净化与素质教育及生物多样性发展动态,技术创新推动产业升级
未来已来:当数字孪生遇上大模型
202