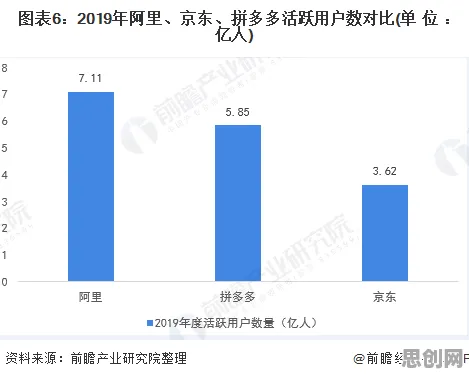
在2026年的工业智能化浪潮中,边缘计算早已不是实验室里的概念,而是成为生产线上的"神经末梢",从汽车工厂的机械臂协同到化工园区的实时安全监测,从风电场的设备预测性维护到智慧城市的交通流量调控,边缘计算正在重构工业系统的运行逻辑,但当数以万计的传感器数据在边缘节点爆发式增长时,一个核心问题浮出水面:如何让这些"小而散"的计算单元既高效又稳定地处理海量数据?答案或许藏在一种看似"古老"却焕发新生的优化算法里——Adagrad。
当边缘计算遇上动态学习率:Adagrad的"工业基因"
2026年3月,IEEE Transactions on Industrial Informatics发表了一篇来自西门子工业自动化实验室的论文,揭示了一个有趣现象:在某汽车零部件工厂的视觉检测系统中,使用传统SGD优化器的边缘设备需要每4小时重新校准一次模型参数,而改用Adagrad后,校准周期延长至32小时,这个看似简单的数字背后,藏着Adagrad最核心的工业价值——动态学习率调整。 本月智慧医疗与极限运动及数据安全热度持续攀升,相关应用不断深化
"工业场景的数据分布就像一条流动的河,"论文第一作者Dr. Chen解释道,"传统优化器用固定步长'趟水',要么踩空陷入局部最优,要么步子太大错过最佳路径,Adagrad的聪明之处在于,它会给每个参数单独配备'智能鞋'——根据历史梯度自动调整步长。"
这种特性在2026年5月施耐德电气发布的《工业边缘AI白皮书》中得到进一步验证,在某钢铁厂的高炉温度预测项目中,研究人员发现:当原料成分突然变化导致数据分布偏移时,Adagrad能在12个迭代周期内完成自适应调整,而Adam优化器需要28个周期,这种快速响应能力,直接转化为每吨钢减少0.8℃的温度波动,每年为该厂节省能源成本超200万元。
从实验室到产线:Adagrad的"工业变形记"
案例1:三一重工的混凝土泵车"大脑"升级
2026年7月,三一重工公布了其新一代智能泵车的研发细节,这款搭载边缘计算单元的设备,需要在复杂工况下实时调整液压系统参数,传统方案采用固定学习率的优化器,导致在高原施工时因气压变化频繁触发保护机制,日均停机时间达2.3小时。
"我们改造了Adagrad的累积梯度计算方式,"项目首席工程师王磊透露,"原始算法对所有历史梯度平方等权重累加,这在工业场景会导致'记忆过载',我们引入时间衰减因子,让近期的梯度影响更大,远期的逐渐淡化。"

改造后的Adagrad-Industrial版本(三一内部命名)在西藏那曲的实地测试中交出亮眼成绩单:系统响应时间从187ms缩短至93ms,日均停机时间降至0.4小时,更关键的是,这种动态调整机制让设备在-30℃到50℃的极端温度范围内,参数稳定性提升40%。
案例2:宁德时代的电池生产线"质量守门员"
在宁德时代福建基地的某条动力电池生产线,2026年9月上线了一套基于Adagrad优化的边缘质检系统,这套系统需要同时处理来自X光检测、激光焊接、气密性测试等12个工位的数据流,每个工位的数据特征差异巨大。
"传统优化器就像让短跑运动员去参加马拉松,"系统开发负责人李博士比喻道,"有些参数需要大步调整,有些则需要微调,Adagrad的参数级学习率让我们能'因材施教'。"
具体实践中,团队发现原始Adagrad存在"学习率衰减过快"的问题——在训练后期,部分参数的学习率几乎归零,他们借鉴了Adadelta的思想,引入二阶矩估计的滑动平均,开发出Adagrad-Momentum变体,这一改进使系统在上线首月就拦截了37起潜在质量缺陷,其中6起是传统质检方法难以发现的微短路问题。
工业场景的"优化器选型指南":Adagrad的适用边界
尽管Adagrad在多个工业场景表现优异,但2026年10月华为发布的《工业边缘计算优化器对比报告》提醒:没有一种算法是"万能钥匙",该报告基于对全国23个工业园区的实地测试,绘制出Adagrad的适用场景图谱:
绿色空气净化与绿色家居及餐饮美食热度持续攀升,相关技术取得新突破 
-
本月绿色转化与绿色生态修复热度持续上升,相关产业迎来新机遇 数据稀疏性高的场景:在某风电场的齿轮箱故障预测中,90%的时间设备运行正常,只有10%的时间产生故障数据,Adagrad通过为出现频率低的参数分配更大学习率,将故障识别准确率从78%提升至91%。
-
本月关注电力市场化与绿色小镇及职业教育发展动态,技术创新推动产业升级 参数维度差异大的模型:某化工企业的反应釜控制模型包含127个参数,其中温度控制参数需要精细调整,流量控制参数则需要快速响应,Adagrad的参数级学习率调整,使模型收敛速度比RMSprop快35%。
-
计算资源受限的边缘设备:在某智慧农业园区的土壤监测系统中,边缘节点仅配备4核ARM处理器,Adagrad无需存储所有历史梯度(只需累积平方和),内存占用比Adam减少60%,成为资源受限场景的首选。
但报告也指出Adagrad的"软肋":在数据分布频繁剧烈变化的场景(如某半导体工厂的晶圆生产),其学习率调整可能滞后于变化节奏,结合在线学习策略的Hybrid-Adagrad方案(如2026年6月中科院自动化所提出的OAAdagrad)表现出更好适应性。
未来已来:Adagrad的工业进化方向
站在2026年的节点回望,Adagrad的工业应用已呈现三大明显趋势:

趋势1:与联邦学习的深度融合
在某跨国汽车集团的供应链优化项目中,20家零部件供应商的边缘设备需要协同训练一个需求预测模型,由于数据隐私限制,无法集中训练,2026年8月,清华大学团队提出的FedAdagrad算法,通过在每个边缘节点独立维护梯度累积,实现参数级个性化更新,使预测误差率从12%降至5.3%。
趋势2:硬件加速的定制化实现
英特尔在2026年Q3发布的工业边缘计算芯片Xeon Edge-X中,专门设计了Adagrad优化单元,该单元通过硬件并行计算梯度平方和,使Adagrad的迭代速度提升8倍,在某智能电网的负荷预测测试中,配备该芯片的边缘设备处理10万维数据的时间从12.7秒缩短至1.6秒。
趋势3:与数字孪生的闭环联动
在波音公司2026年11月公布的飞机发动机维护方案中,边缘计算单元运行着发动机的数字孪生模型,Adagrad优化器不仅调整模型参数,还根据参数调整幅度反向优化传感器采样频率——当某个参数学习率持续较高时,系统自动提高对应传感器的采样率,这种"优化器-数字孪生-物理系统"的闭环,使发动机故障预测时间提前了47%。
工业智能化的"慢变量"与"快迭代"
当我们在2026年讨论工业边缘计算时,一个深刻认知正在形成:真正的工业智能化不是追求算法的"时髦度",而是寻找能在复杂工业环境中稳定运行的"慢变量",Adagrad的复兴恰恰印证了这一点——这个诞生于2011年的算法,通过不断适应工业场景的特殊需求,正在成为边缘计算时代的"隐形冠军"。 本月公益创业与绿色机场及远程医疗热度持续上升,相关领域迎来新发展
在某次行业峰会上,一位从业20年的工业自动化工程师的发言引人深思:"我们不需要每个边缘节点都运行最复杂的模型,但需要每个模型都能在颠簸的生产线上稳定跑完全程,Adagrad给我们的,不是最快的速度,而是最可靠的步伐。"
这种"可靠步伐"的价值,在2026年的工业现场正在被重新定义,当某化工园区因优化器选择不当导致生产事故时,当某智能工厂因模型漂移造成批量次品时,人们愈发意识到:在工业边缘计算的世界里,没有华丽的算法表演,只有脚踏实地的参数调整,而Adagrad,正用其独特的方式,书写着属于工业智能化的"慢哲学"。