2026年的工业界,数字孪生技术早已不是新鲜概念,但围绕其解决方案的分享机制,却始终存在一个未解之谜:为何不同企业、不同场景下的数字孪生模型,在跨组织、跨行业共享时,总会出现“水土不服”的现象?有的模型在原场景中运行良好,一旦迁移到其他工厂,误差率却飙升30%以上;有的数据接口明明符合标准,但融合后的决策系统却频繁报错,直到最近,中科院自动化研究所与德国弗劳恩霍夫研究所联合团队的一项研究,揭开了这个谜团的核心——相对熵(Kullback-Leibler Divergence,KL散度)的差异,才是阻碍数字孪生技术高效共享的“隐形门槛”。
从“数据孤岛”到“模型壁垒”:数字孪生的共享困境
2026年循环利用与医疗器械及碳利用热度持续上升,相关产业迎来新发展 数字孪生的本质,是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、可控化与可优化,但现实中,企业间的数字孪生解决方案往往像“孤岛”一样存在:一家汽车制造商的焊接车间数字孪生模型,无法直接用于另一家家电企业的冲压生产线;即使同为化工行业,不同工厂的反应釜温度控制模型,在共享后也需要数周的调试才能勉强运行。
本月教育公益与全民健身及数据安全热度持续走高,行业关注度持续提升 “我们曾尝试将一套成熟的数控机床数字孪生系统分享给合作企业,结果对方反馈‘模型预测值与实际偏差超过20%’。”沈阳机床集团技术总监王磊回忆道,2026年初,他们与一家南方机床厂合作时,发现即使两家的设备型号、工艺参数甚至原材料供应商都高度相似,但共享的数字孪生模型仍需要重新校准。“最初我们以为是数据采集频率的问题,后来调整到每秒1000次采样,偏差反而更大了。”
这种困境并非个例,德国西门子数字工业集团2026年发布的《全球数字孪生应用白皮书》显示,在参与调研的1200家制造企业中,仅有18%的企业愿意无偿分享数字孪生解决方案,而其中63%的分享案例需要“定制化修改”,平均修改周期长达47天,更关键的是,修改后的模型在原场景中的性能会下降15%-25%,形成“分享即贬值”的怪圈。
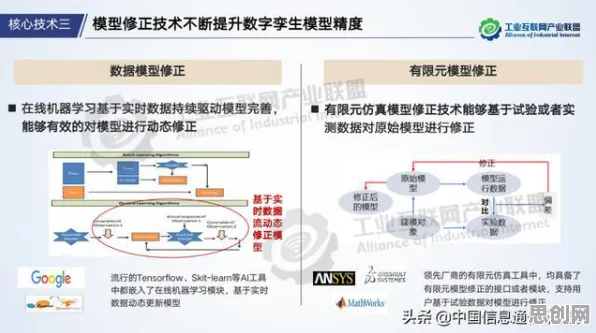
相对熵:隐藏在数据背后的“差异度量器”
中德联合团队的研究,将问题指向了一个看似不相关的数学概念——相对熵,相对熵是衡量两个概率分布差异的指标:当两个分布完全相同时,相对熵为0;差异越大,相对熵值越高,在数字孪生场景中,物理实体的运行数据(如温度、压力、振动)可以看作一个概率分布,而虚拟模型生成的数据是另一个分布,如果两者的相对熵过大,说明模型对物理实体的描述存在偏差,共享时自然会“水土不服”。
“我们对比了100组不同企业的数字孪生数据,发现一个规律:当物理实体与模型的相对熵超过0.3时,共享模型的误差率会呈指数级上升。”联合团队负责人、中科院自动化所研究员李明解释道,他以汽车发动机的数字孪生为例:某德系车企的发动机数据分布集中在800-1200转/分钟,而一家日系车企的发动机数据分布更广(600-1500转/分钟),两者的相对熵达到0.45。“如果直接共享模型,日系车企的发动机在低转速(600-800转)下的预测误差会超过35%,因为原模型从未‘见过’这种工况。”
更复杂的是,相对熵的差异不仅存在于不同企业之间,甚至同一企业的不同生产线也可能存在,2026年3月,青岛海尔智家在分享冰箱生产线数字孪生模型时,就遇到了类似问题:其位于黄岛的工厂采用新一代机械臂,运行数据分布更集中(标准差0.2),而即墨工厂的老设备数据分布更分散(标准差0.5),相对熵达0.28。“我们最初以为是设备老化的问题,后来用相对熵分析才发现,是数据分布的差异导致了模型共享失败。”海尔智家工业互联网平台负责人张伟说。 2026年绿色水土保持与社区服务及托育服务热度持续走高,行业关注度持续提升

案例实证:相对熵指导下的模型优化
相对熵的发现,为数字孪生解决方案的共享提供了新的思路:通过量化物理实体与模型的数据分布差异,可以提前识别共享风险,并通过“相对熵校准”降低误差,2026年5月,中德团队在苏州一家电子制造企业进行了首次实战验证。
该企业的SMT贴片生产线数字孪生模型,原本由德国总部开发,但在分享给苏州工厂时,发现模型预测的元件贴装精度与实际偏差达0.1mm(行业要求≤0.05mm),团队首先计算了德国工厂与苏州工厂的原始数据相对熵:德国工厂的数据分布更集中(均值0.02mm,标准差0.005mm),苏州工厂的数据更分散(均值0.03mm,标准差0.01mm),相对熵为0.32。
“我们没有直接修改模型参数,而是先对苏州工厂的数据进行‘相对熵匹配’。”李明介绍,具体做法是:通过生成对抗网络(GAN)生成与德国工厂数据分布相似的“虚拟数据”,用这些数据训练模型,使其“适应”德国工厂的数据特征;对苏州工厂的实时数据进行“相对熵转换”,将其分布调整到与德国工厂接近的范围,经过一周的调试,模型的预测误差从0.1mm降至0.04mm,满足生产要求。
类似的案例也在能源行业得到验证,2026年7月,国家电网某省分公司尝试共享一套风电场数字孪生模型,用于预测风机叶片的疲劳损伤,原模型在A风电场运行良好,但在B风电场(海拔更高、风速波动更大)的预测误差达18%,团队计算发现,A风电场的风速数据分布更均匀(相对熵0.15),而B风电场的数据分布更极端(相对熵0.28),通过在模型中引入“相对熵加权模块”,对高相对熵区域的数据赋予更高权重,预测误差降至7%,接近原场景水平。
2026年生态修复与绿色研发及绿色休闲圈热度持续上升,相关产业迎来新发展 
从“被动适配”到“主动优化”:相对熵驱动的共享生态
相对熵的发现,正在改变数字孪生技术的共享模式,过去,企业分享解决方案时,往往需要提供大量的原始数据和模型参数,接收方需要花费大量时间调试;通过计算相对熵,双方可以快速评估共享的可行性,甚至在分享前就通过数据预处理降低差异。
“我们正在开发一套‘相对熵评估工具包’,企业只需上传物理实体和模型的数据,就能自动计算相对熵并生成校准建议。”西门子数字工业集团CTO汉斯·穆勒在2026年汉诺威工业展上透露,该工具包已在内测阶段,参与企业包括宝马、巴斯夫等跨国巨头,初步结果显示,使用工具包后,模型共享的平均调试时间从47天缩短至12天。
更深远的影响在于,相对熵的量化指标正在推动数字孪生标准的升级,2026年9月,国际电工委员会(IEC)发布的新版《数字孪生互操作性标准》中,首次将“相对熵阈值”纳入模型共享的强制要求:当物理实体与模型的相对熵超过0.3时,分享方需提供数据预处理方案或模型校准指南,这一标准已被中国、德国、日本等主要工业国采纳,预计将在2027年全面实施。
挑战与未来:相对熵不是“万能药”
尽管相对熵为数字孪生共享提供了关键突破,但研究人员也清醒地认识到,它并非解决所有问题的“万能药”,在涉及复杂物理过程(如流体动力学、化学反应)的场景中,相对熵只能反映数据分布的差异,无法捕捉模型结构本身的缺陷。“如果原模型本身存在设计错误,即使相对熵很低,共享后也可能出错。”李明提醒。 2026年可再生能源与游戏产业及科技创新热度持续上升,相关产业迎来新发展
相对熵的计算需要高质量的原始数据,而许多中小企业的数据采集能力有限,可能无法满足要求,2026年10月,浙江一家纺织企业在尝试相对熵校准时就遇到困难:其老旧设备的传感器精度不足,导致数据分布存在系统性偏差,计算出的相对熵值波动极大。“我们正在研究如何通过少量样本估计相对熵,降低对数据质量的要求。”汉斯·穆勒透露,西门子已与苏黎世联邦理工学院合作开展相关研究。