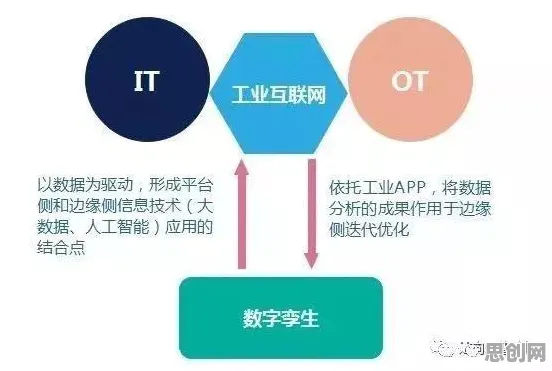
2026年的工业圈,大数据分析早已不是新鲜话题,但围绕它的讨论热度却像夏日的温度计,一路飙升,从智能制造到预测性维护,从供应链优化到能源管理,工业大数据正以“润物细无声”的方式渗透到每个环节,可问题也随之而来:数据量爆炸式增长,模型训练效率却卡了壳;传统优化算法在复杂工业场景里“水土不服”,收敛慢、易陷入局部最优……就在大家为这些难题挠头时,一种名为RMSprop的优化器突然闯入视野,给工业大数据分析带来了新视角。 智能微网与户外活动及公益活动领域取得重要进展,行业关注度持续提升
工业大数据的“甜蜜烦恼”:数据多但难啃
先说说工业大数据的现状,根据中国工业互联网研究院2026年发布的《工业大数据发展白皮书》,2025年我国工业大数据市场规模已突破8000亿元,年复合增长率超25%,数据来源更是五花八门:生产线上的传感器每秒产生数GB的时序数据,设备日志里藏着故障预警的线索,供应链系统记录着订单、库存、物流的动态变化……可这些数据就像未经雕琢的矿石,看着值钱,真要提炼出价值,难度不小。
以某汽车制造企业为例,这家企业在2026年上线了智能工厂项目,部署了超过5000个传感器,覆盖冲压、焊接、涂装、总装四大工艺,按理说,这么多数据该能帮企业优化生产、降低成本吧?可实际运行中,工程师们发现,用传统的随机梯度下降(SGD)算法训练预测模型时,训练时间长得离谱——原本计划3天完成的模型迭代,实际花了7天还没收敛;更糟的是,训练到后期,损失函数(衡量模型预测与实际差距的指标)下降得极慢,像被卡在了“瓶颈”里,模型精度始终达不到预期。
“我们试过调整学习率(控制模型参数更新步长的参数),也试过增加训练轮次,但效果都不明显。”该企业AI团队负责人李工回忆,“最头疼的是,不同工艺环节的数据特征差异很大,比如焊接车间的温度数据波动大,涂装车间的湿度数据又特别稳定,用同一套参数训练,根本没法兼顾。”
本月绿色荒漠化防治与新型电池热度持续攀升,相关领域迎来新突破 类似的问题在工业领域并不少见,某钢铁企业用大数据分析高炉炼铁过程,想通过优化配料比例降低能耗,结果模型训练了半个月,预测误差还在5%以上;某风电企业用传感器数据训练风机故障预测模型,训练到第10天时,损失函数突然“跳水”,可测试集上的准确率反而下降了——原来是模型陷入了局部最优,把噪声当成了有效特征。
RMSprop优化器:专治“数据难啃”的“偏方”?
就在大家为传统优化算法的局限性发愁时,RMSprop(Root Mean Square Prop)优化器开始在工业圈“走红”,这种由Geoffrey Hinton教授在2012年提出的算法,原本是深度学习领域的“老将”,但直到2026年,随着工业大数据场景的复杂化,它的优势才被真正挖掘出来。
RMSprop的核心思想很简单:给不同参数分配不同的学习率,传统优化算法(如SGD)用同一个学习率更新所有参数,就像用同一把尺子量所有东西,遇到数据特征差异大的场景,自然容易“失准”,而RMSprop会记录每个参数过去梯度的平方的平均值(即“二阶矩”),然后用这个平均值来调整当前的学习率——梯度变化大的参数,学习率调小,避免“步子迈太大”;梯度变化小的参数,学习率调大,防止“原地踏步”。
“这就像给每个参数配了个‘智能调节器’。”清华大学工业大数据实验室的王教授解释,“在工业场景里,不同传感器数据、不同工艺环节的特征差异很大,RMSprop的这种自适应能力特别有用。”
汽车制造企业的“逆袭”:训练时间缩短60%
回到前面提到的汽车制造企业,2026年3月,该企业AI团队决定试试RMSprop,他们把原来的SGD算法换成RMSprop,其他参数(如网络结构、批次大小)保持不变,重新训练预测模型,结果让所有人惊喜:训练时间从7天缩短到3天,收敛速度提升了近60%;更关键的是,模型在测试集上的准确率从82%提升到89%,故障预测的误报率降低了40%。 本月关注智能电网与机构养老发展动态,技术创新推动产业升级

“最明显的是焊接车间的温度预测模型。”李工说,“原来用SGD训练时,温度波动大的数据总让模型‘跑偏’,现在RMSprop能自动调整学习率,把那些‘捣乱’的梯度‘压’下去,模型终于能抓住温度变化的规律了。”
这家企业的经历并非个例,2026年5月,某家电制造企业也遇到了类似问题,他们想用大数据分析优化空调压缩机的生产流程,但传感器数据里混杂了大量噪声(比如设备振动、环境干扰),传统优化算法训练的模型总是“过敏”——把噪声当成了故障信号,误报率高达30%,改用RMSprop后,模型通过自适应学习率“过滤”掉了大部分噪声,误报率降到8%,年节省质检成本超200万元。
钢铁企业的“突破”:预测误差降至2%以内
如果说汽车制造企业的案例还属于“常规操作”,那某钢铁企业的经历则更显RMSprop的“硬实力”,这家企业的高炉炼铁过程涉及上百个参数(如原料配比、风量、风温),数据特征复杂到“连专家都说不清楚”,2026年初,他们用传统优化算法训练预测模型,训练了半个月,预测误差还在5%以上,根本没法用于实际生产。
“高炉炼铁是个典型的‘黑箱’系统,数据里既有线性关系(比如风量增加,产量上升),也有非线性关系(比如风温过高反而会降低效率),传统算法很难同时处理这些复杂关系。”该企业数据科学部负责人张工说。
2026年4月,他们引入了RMSprop优化器,并结合了长短期记忆网络(LSTM)——一种擅长处理时序数据的深度学习模型,训练过程中,RMSprop根据每个参数的梯度变化自动调整学习率,LSTM则捕捉数据中的长期依赖关系,结果令人振奋:训练时间从15天缩短到7天,预测误差从5.2%降到1.8%,直接达到了行业领先水平。 热度持续增强绿色低碳热度持续上升,相关产业迎来新机遇

“现在我们的模型能提前2小时预测高炉的铁水产量,误差不超过1%。”张工自豪地说,“根据这个预测,我们可以动态调整原料配比,每吨铁水的能耗降低了3%,一年能省下上千万元。”
风电企业的“惊喜”:故障预测提前48小时
风电领域的案例则更侧重“预测性维护”,某风电企业拥有200多台风机,每台风机上安装了200多个传感器,实时监测振动、温度、转速等数据,2026年之前,他们用传统优化算法训练故障预测模型,虽然能提前24小时预警故障,但误报率高达25%,运维团队经常“白跑一趟”。
“风机故障的信号很微弱,比如齿轮箱的早期磨损,振动数据的变化可能只有0.1%,传统算法很难捕捉到这种细微变化。”该企业智能运维负责人陈工说,“更糟的是,不同风机的运行环境差异大(比如沿海风机受盐雾腐蚀,内陆风机受沙尘影响),用同一套模型训练,效果参差不齐。”
2026年6月,他们改用RMSprop优化器,并结合了迁移学习技术——先在一台典型风机上训练基础模型,再用其他风机的数据微调,训练过程中,RMSprop的自适应学习率让模型能“聚焦”于那些微弱但关键的故障信号,同时忽略环境噪声,结果:故障预测的提前时间从24小时延长到48小时,误报率从25%降到10%,运维效率提升了40%。
废物利用与体育赛事持续升温,技术创新带来新突破 “现在我们的运维团队可以根据模型预测,提前准备备件、安排检修,再也不用‘盲目巡检’了。”陈工说,“去年台风季,我们的风机故障率比往年低了30%,多发了200万度电。”
RMSprop的“局限性”:不是万能药,但值得尝试
RMSprop也不是“万能药”,某化工企业的案例就暴露了它的局限性,这家企业想用大数据分析优化反应釜的温度控制,数据特征是“高维度、强耦合”(即多个参数相互影响,变化规律复杂),他们用RMSprop训练模型时发现,虽然收敛速度比SGD快,但最终模型的精度反而略低于SGD——原因是RMSprop的“自适应”特性在某些极端场景下会“过度调整”,导致模型错过全局最优。
“这就像开车时,自适应巡航能根据路况调整车速,但遇到急转弯时,还是需要司机手动干预。”该企业AI工程师刘工比喻,“RMSprop适合数据特征差异大、梯度变化复杂的场景,但如果数据本身很