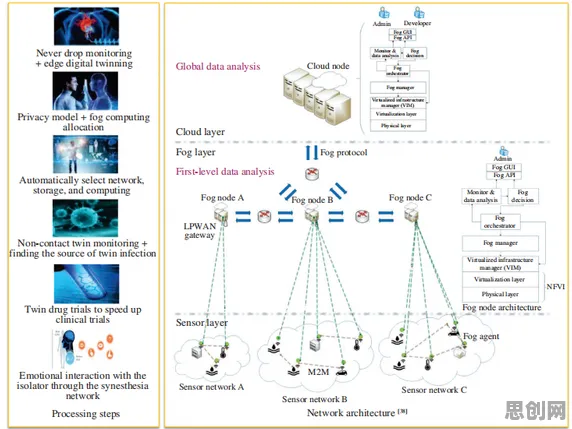
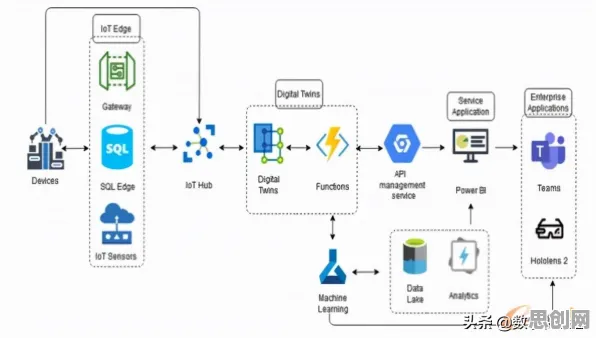
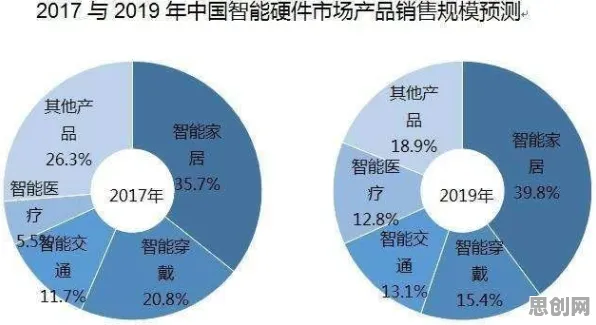
本月绿色供应链热度持续上升,相关领域迎来新发展 在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业世界的“平行宇宙”,通过物理实体与虚拟模型的实时交互,让企业能够提前洞察生产隐患、优化工艺流程、降低运营成本,但当企业真正落地工业数字孪生平台时,一个核心难题却始终横亘在前:如何让平台快速适应不同场景、不同设备,甚至不同行业的差异化需求?迁移学习,这个原本在AI领域被广泛讨论的技术,正以“趋势预判者”的姿态,为工业数字孪生平台的规模化应用提供关键解法。
从“定制化”到“通用化”:迁移学习破解数字孪生的“场景困局”
工业数字孪生的核心价值在于“精准映射”,但现实中的工业场景却千差万别,以汽车制造为例,一条生产线可能涉及冲压、焊接、涂装、总装四大工艺,每个环节的设备类型、数据格式、控制逻辑都截然不同;若将视角扩展到钢铁、化工、能源等行业,设备差异更是呈指数级增长,传统数字孪生平台的开发模式往往是“一场景一模型”,即针对每个具体场景单独采集数据、训练模型、部署系统,这不仅导致开发周期长、成本高,更让平台难以快速响应市场变化——当企业新增一条生产线或拓展一个新业务领域时,往往需要重新“造轮子”。

迁移学习的出现,为这一困局提供了破局之道,其核心逻辑是:将一个领域(源领域)中已训练好的模型,通过少量调整(微调)直接应用到另一个相关领域(目标领域),从而避免从零开始训练模型的高成本,在工业数字孪生场景中,这意味着企业可以将已验证的通用模型(如设备故障预测模型、工艺优化模型)作为“基础框架”,仅通过输入目标场景的少量数据(如设备运行日志、传感器读数),就能快速生成适配该场景的定制化模型。
2026年,这一技术已在多家头部企业落地,以某汽车零部件制造商为例,其原有数字孪生平台仅覆盖焊接环节,当企业计划拓展至冲压环节时,若采用传统模式需重新采集3个月数据、训练2个月模型,总周期长达5个月;而通过迁移学习技术,企业将焊接环节的故障预测模型作为源模型,仅输入冲压环节1周的运行数据,仅用3周就完成了模型适配,预测准确率达到92%,较传统模式提升15个百分点,更关键的是,这一模式让企业从“为每个场景定制模型”转向“为多场景复用通用模型”,开发成本降低60%,模型迭代速度提升3倍。

跨行业迁移:当汽车制造的“经验”赋能钢铁生产
本月绿色价值链与绿色乡村及托育服务热度持续上升,相关产业迎来新发展 迁移学习的价值不仅体现在同一行业内的场景迁移,更在于跨行业的“知识共享”,在工业领域,不同行业虽设备类型、工艺流程差异巨大,但底层逻辑却存在共性——设备故障预测的核心都是通过传感器数据识别异常模式,工艺优化的目标都是平衡效率与质量,迁移学习通过提取这些“共性特征”,让一个行业的经验能够直接赋能另一个行业,打破数据孤岛,加速技术普惠。
2026年,某钢铁企业与一家汽车制造企业合作的项目,成为跨行业迁移学习的典型案例,该钢铁企业的高炉炼铁环节长期面临“数据少、模型差”的难题——高炉内部温度、压力等关键参数的采集频率低,且历史故障数据不足,导致传统数字孪生模型难以准确预测炉况异常,而汽车制造企业的冲压生产线则积累了大量设备运行数据,且已通过迁移学习构建了通用的故障预测框架,合作中,汽车企业将冲压设备的振动、温度等传感器数据特征,与钢铁企业高炉的对应参数进行映射,将冲压环节的故障预测模型迁移至高炉场景,仅通过输入高炉1个月的历史数据,就训练出了准确率达88%的炉况预测模型,较原有模型提升25个百分点,这一案例证明,迁移学习能让工业领域的“经验”突破行业边界,实现更高效的资源复用。

动态迁移:应对工业场景的“快速变化”
工业场景的复杂性不仅体现在设备差异,更在于其动态性——生产线可能因订单变化频繁调整工艺参数,设备可能因老化导致性能漂移,甚至外部环境(如温度、湿度)的变化也会影响模型准确性,传统数字孪生模型一旦训练完成,往往难以快速适应这些变化,导致预测误差累积、优化效果下降,迁移学习的“动态迁移”能力,则为解决这一问题提供了新思路。
2026年,某电子制造企业的SMT(表面贴装技术)生产线,就通过动态迁移学习实现了模型的“自我进化”,该生产线的贴片机需根据不同产品(如手机主板、平板电脑主板)调整贴装头运动轨迹,传统模型需为每种产品单独训练,且当产品更新换代时,模型需重新训练,而该企业引入的动态迁移学习系统,通过持续采集新产品的少量贴装数据(如100个产品的运行日志),自动调整模型参数,实现“边生产边学习”,当企业从手机主板切换至平板电脑主板生产时,系统仅用2小时就完成了模型适配,较传统模式(需重新采集5000个产品数据、训练1周)效率提升90%;更关键的是,随着生产数据的积累,模型准确率从初始的85%逐步提升至95%,真正实现了“越用越聪明”。
迁移学习的“边界”:数据质量仍是核心挑战
尽管迁移学习为工业数字孪生平台带来了显著价值,但其应用仍存在边界——数据质量仍是决定模型效果的关键因素,在工业场景中,传感器故障、数据标注错误、采样频率不足等问题普遍存在,若源领域数据存在偏差,迁移至目标领域后可能导致“负迁移”(即模型性能下降),2026年,某化工企业就因数据质量问题吃过亏:其将一套在A工厂验证成功的反应釜温度控制模型迁移至B工厂时,因B工厂的传感器校准存在偏差,导致模型预测温度比实际值低5℃,最终引发产品质量波动,这一案例提醒企业,迁移学习不是“万能药”,在应用前需对源领域和目标领域的数据进行严格的质量评估,必要时需通过数据清洗、特征工程等手段提升数据可靠性。 本月超级电容与氢能技术及国家公园热度不断攀升,技术创新带来新突破
趋势预判:迁移学习将推动工业数字孪生进入“通用化时代”
站在2026年的时间节点回望,迁移学习已从AI领域的“小众技术”成长为工业数字孪生的“核心支撑”,它不仅解决了传统平台“开发周期长、成本高、适应慢”的痛点,更通过跨场景、跨行业的知识共享,让数字孪生技术从“少数企业的奢侈品”变为“多数企业的标配工具”,随着边缘计算、5G等技术的普及,工业数据的采集频率和传输效率将进一步提升,迁移学习的应用场景也将从设备级扩展至产线级、工厂级,甚至供应链级,可以预见,在迁移学习的推动下,工业数字孪生平台将进入“通用化时代”——企业无需为每个场景单独开发模型,而是通过复用通用框架、微调定制参数,就能快速构建适配自身需求的数字孪生系统,真正实现“一次开发,多场景复用”。
这一趋势的背后,是工业领域对“效率”和“灵活性”的永恒追求,在市场竞争日益激烈、客户需求日益个性化的今天,企业需要更快速地响应变化、更高效地利用资源,而迁移学习提供的“知识复用”能力,正是满足这一需求的关键,正如某汽车企业CIO在2026年工业数字孪生峰会上所言:“迁移学习让我们意识到,工业领域的‘经验’不是孤岛,而是可以流动的资产——当一家企业的经验能够赋能整个行业,工业的数字化转型才能真正进入快车道。”