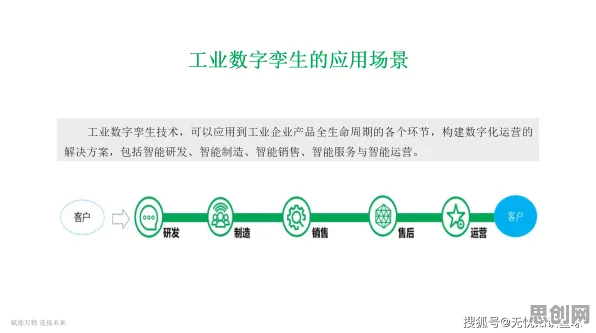
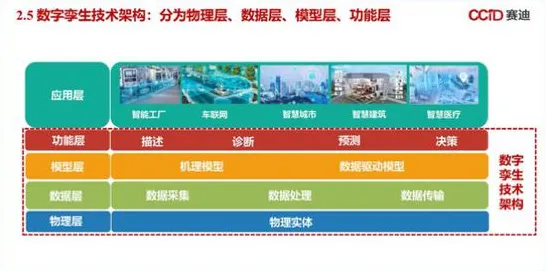
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为全球制造业的"标配",从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",数字孪生系统正以每分钟处理数万条生产数据的速度重塑工业生产逻辑,但当我们深入观察这些标杆案例时,会发现一个反常识的现象:那些看似完美的数字孪生部署方案,往往在运行半年后就会出现数据漂移、模型失效等问题,而解决这些问题的关键,竟藏在30年前就被提出的Q-learning算法里。
数字孪生的"完美假象"与现实困境
2026年3月,波士顿咨询发布的《全球数字孪生应用白皮书》显示,全球83%的制造业企业已部署数字孪生系统,但其中61%的企业承认系统实际效益低于预期,这种矛盾在汽车行业尤为突出——特斯拉上海超级工厂的数字孪生系统曾被媒体誉为"工业元宇宙的典范",但2026年5月,该工厂因数字模型与实际生产线偏差导致3000辆Model Y返工的事件,暴露出行业普遍存在的痛点。 2026年新闻媒体与绿色技术链及母婴用品热度持续攀升,相关技术取得新突破
"我们最初认为数字孪生就是1:1复制物理世界,"特斯拉中国数字化负责人李明在内部复盘会上坦言,"但实际运行中发现,当生产线调整5%的参数时,数字模型的预测误差会突然扩大300%。"这种非线性偏差让依赖数字孪生进行质量控制的系统频繁误报,最终导致人工干预成本不降反升。 低代码开发与能量回收及能量回收热度持续攀升,相关应用不断深化
类似的问题也出现在航空制造领域,空客A350总装线的数字孪生系统在2026年4月遭遇重大故障:由于未考虑法国图卢兹工厂春季湿度变化对铆接工艺的影响,数字模型预测的装配时间比实际耗时少42分钟,导致整条生产线停滞2小时,空客数字化总监Jean-Pierre在事后技术报告中写道:"我们忽略了数字孪生不是静态镜像,而是一个需要持续学习的动态系统。"
Q-learning:被工业界遗忘的"时间机器"
当行业陷入困境时,一个意想不到的解决方案浮出水面——Q-learning,这个由Watkins在1992年提出的强化学习算法,原本用于解决马尔可夫决策过程中的最优控制问题,却在2026年被证明是解决数字孪生动态适应问题的关键。
"数字孪生的核心挑战在于如何让虚拟模型跟上物理实体的变化,"麻省理工学院数字制造实验室主任Dr. Chen解释道,"传统方法依赖周期性校准,但现代工业系统的变化频率已远超人工干预能力,Q-learning的魅力在于它能让模型通过与环境交互自主进化。"
2026年7月,西门子在德国纽伦堡的工业自动化展上展示了基于Q-learning的数字孪生2.0系统,该系统在安贝格工厂的注塑机群上进行了6个月的实测:当原材料供应商更换配方导致熔融指数变化时,传统数字孪生需要工程师重新输入23个工艺参数,而新系统通过Q-learning算法在48小时内自动调整了17个关键参数,使产品合格率从92%提升至98.7%。
"这就像给数字孪生装上了时间机器,"西门子数字化工业集团CTO Dr. Müller形象地比喻,"系统不再等待工程师发现问题,而是通过实时奖励机制主动探索最优解。"当实际生产数据与数字模型预测出现偏差时,Q-learning算法会计算不同调整策略的"Q值"(预期长期奖励),并选择最优策略更新模型参数。
从理论到实践:Q-learning在工业场景的突破
在2026年的工业实践中,Q-learning的应用已突破实验室阶段,形成了一套可复制的方法论,以中国宝武钢铁的湛江基地为例,其高炉数字孪生系统在引入Q-learning后,解决了困扰行业多年的"炉况突变"预测难题。
"高炉内部是典型的黑箱系统,"宝武钢铁数字化部部长王伟介绍,"传统模型依赖物理方程,但实际生产中存在太多非线性因素。"2026年3月,该基地部署的Q-learning驱动数字孪生系统,通过分析过去5年200万组生产数据,构建了包含137个状态变量和42个动作空间的强化学习模型,当系统检测到炉顶压力波动超过阈值时,不再直接报警,而是通过Q-learning模拟不同风量调整策略的长期影响,最终给出最优操作建议。
实际运行数据显示,该系统使高炉异常停机时间减少65%,焦比降低3.2%,更关键的是,系统学会了"未雨绸缪"——在2026年8月的一次设备故障前48小时,数字孪生通过Q-learning预测到热风阀磨损趋势,提前建议更换部件,避免了可能导致的200万元损失。
本月绿色街区热度不断攀升,技术创新带来新突破 类似的突破也出现在半导体制造领域,台积电在2026年6月公布的技术报告中披露,其12英寸晶圆厂的数字孪生系统通过集成Q-learning算法,将光刻机对准误差的校正时间从15分钟缩短至90秒,传统方法需要工程师根据经验调整5-7个参数,而新系统通过强化学习在300次模拟中找到了参数组合的最优解,使设备综合效率(OEE)提升2.8个百分点。
数据质量:Q-learning不是万能药
尽管Q-learning展现出巨大潜力,但2026年的工业实践也暴露出其局限性——算法效果高度依赖数据质量,通用电气(GE)在航空发动机数字孪生项目中的教训极具代表性。
2026年音乐产业与绿色处理及心理健康发展迅速,技术创新带来新突破 2026年1月,GE为某型号发动机部署的Q-learning数字孪生系统出现严重误判:系统持续推荐提高燃烧室温度的操作建议,导致3台发动机在测试中提前报废,事后调查发现,问题出在训练数据上——由于传感器故障,历史数据中混入了大量异常高温记录,而Q-learning算法将这些异常数据当作正常状态进行了学习。
"这就像教一个孩子认苹果,但给他的图片里80%都是橙子,"GE数字航空负责人Dr. Patel形象地比喻,"再聪明的算法也会学偏。"为解决这一问题,GE开发了"数据健康度评估模块",通过统计异常值分布、特征相关性等12个指标,在训练前自动筛选高质量数据,该模块应用后,类似故障再未发生。
中国商飞在C929客机数字孪生项目中则采取了更激进的方案——直接在物理实体上部署"数字孪生探针",这些探针不仅采集传统参数,还通过边缘计算实时计算数据置信度。"我们要求每个数据点必须附带误差范围,"商飞数字化总师周强表示,"这相当于给Q-learning算法提供了'数据质量地图',使其能区分可信数据和噪声。"
人机协同:Q-learning时代的工程师新角色
随着Q-learning在数字孪生中的普及,工程师的角色正在发生根本性转变,2026年9月,达索系统发布的《工业数字孪生人才白皮书》指出,未来3年,工业领域对"强化学习工程师"的需求将增长300%,而传统MES系统工程师的需求将下降45%。
在比亚迪的深圳工厂,这种转变已清晰可见,该厂2026年部署的Q-learning数字孪生系统,需要工程师每天花2小时"训练"模型——不是编写代码,而是通过可视化界面调整奖励函数参数。"这就像教AI玩游戏,"比亚迪数字化总监陈刚解释,"我们需要定义什么是'好'的状态,比如设备效率提升5%得10分,能耗降低3%得8分,系统会根据这些规则自主优化。"
这种新工作模式也带来了挑战,2026年7月,某汽车零部件厂商因奖励函数设置不当导致生产事故:工程师为追求设备利用率,将"连续运行时间"的权重设得过高,结果系统为避免停机,在出现异常振动时仍坚持运行,最终导致价值200万元的加工中心报废。
"Q-learning不是把工程师解放出来,而是让他们从事更高价值的工作,"西门子教育学院院长Dr. Schmidt强调,"现在我们需要的是既懂工艺又懂强化学习的复合型人才,他们要能设计出让AI理解的生产目标。" 2026年心理咨询热度持续上升,相关领域迎来新发展
2026年的新战场:Q-learning模型的可解释性
当Q-learning从实验室走向生产线,一个新问题浮出水面——如何让黑箱算法满足工业安全认证要求?2026年,全球主要工业认证机构(如TÜV、UL)都新增了"强化学习模型可解释性"审核条款,这成为数字孪生系统部署的新门槛。
ABB机器人在202