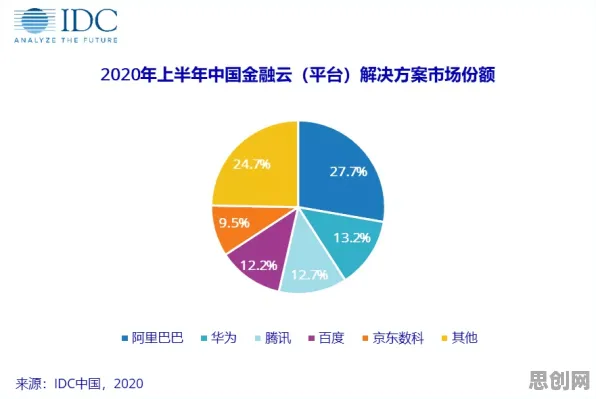
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它正以惊人的速度重塑着传统制造业的生产模式,从德国西门子的安贝格电子制造工厂到中国海尔的互联工厂,全球范围内的标杆企业都在通过数字孪生实现生产过程的可视化、可预测与可优化,但鲜为人知的是,在这场工业革命的背后,自然语言处理(NLP)技术正扮演着“隐形推手”的角色,它像一条无形的逻辑链条,将人类的语言指令、设备运行数据与数字孪生模型紧密连接,让虚拟与现实的交互变得更为流畅与智能。
从“人话”到“机器指令”:NLP的桥梁作用
工业数字孪生的核心是构建一个与物理实体完全对应的虚拟模型,这个模型需要实时接收来自物理世界的运行数据,并通过算法分析预测未来状态,但问题在于,物理世界的数据来源复杂多样——传感器采集的是二进制信号,设备日志是结构化文本,而工程师的维护记录可能是非结构化的自然语言,如何让这些“语言不通”的数据在数字孪生系统中无缝流通?NLP技术成了关键。
以2026年3月德国博世集团在斯图加特工厂的实践为例,该工厂的数字孪生系统需要整合来自全球12个生产基地的3000多台设备的运行数据,其中约40%的数据来自设备维护人员的现场记录,这些记录原本以自然语言形式存在,3号机床在加工过程中出现轻微振动,振动频率约为50Hz,持续约10分钟后恢复正常”,传统方式下,工程师需要手动将这些描述转化为结构化数据,再输入数字孪生模型,耗时且易出错。
博世引入的NLP解决方案则彻底改变了这一流程,系统通过预训练的工业领域语言模型,自动识别文本中的关键实体(如“3号机床”“振动频率50Hz”)和事件(如“异常出现”“恢复正常”),并将其转化为数字孪生模型可理解的JSON格式数据,这一过程仅需0.3秒,准确率高达98.7%,更关键的是,系统还能根据历史数据学习设备的“语言习惯”——不同工程师对“轻微振动”的描述可能不同,但NLP模型能通过上下文理解其实际含义,确保数据的一致性。

设备“说话”:非结构化数据的结构化解析
如果说工程师的记录是“人话”,那么设备的日志则是另一种“机器语言”,现代工业设备通常内置大量传感器,会生成海量的运行日志,但这些日志往往是半结构化或非结构化的文本,包含大量专业术语和缩写,某台数控机床的日志可能记录:“2026-05-15 14:23:45 [ERROR] SPINDLE_OVERLOAD (Code: E102) - Current load: 125% of rated value, duration: 8s”,传统方式下,工程师需要查阅设备手册才能理解“SPINDLE_OVERLOAD”代表主轴过载,“E102”是具体错误代码,而“125%”和“8s”则是关键参数。
2026年,中国航天科工集团在某卫星制造车间引入的NLP系统,则让设备日志“自己说话”,该系统通过工业知识图谱,将设备手册、维修记录、历史故障案例等数据整合为结构化知识库,再结合NLP的实体识别与关系抽取技术,自动解析日志中的关键信息,对于上述日志,系统能直接提取出“故障类型:主轴过载”“错误代码:E102”“当前负载:额定值的125%”“持续时间:8秒”等结构化数据,并关联到数字孪生模型中的对应设备模块,这一过程不仅将数据解析时间从分钟级缩短至秒级,还通过知识图谱的推理能力,自动判断故障的严重程度(如“持续8秒的过载可能对主轴轴承造成损伤”),为维护决策提供依据。
跨语言交互:全球供应链的“通用语”
在全球化背景下,工业数字孪生的实施往往涉及跨国协作,某汽车制造商的数字孪生系统需要整合来自德国总部、中国工厂和美国供应商的数据,但这些数据可能以德语、中文和英语三种语言存在,如何确保不同语言的指令和数据在系统中无缝流通?NLP的跨语言处理能力成了关键。

2026年,日本丰田汽车在泰国工厂的实践提供了典型案例,该工厂的数字孪生系统需要实时接收来自日本总部的生产指令(日语)、中国供应商的零部件质量报告(中文)和本地工程师的维护记录(泰语),丰田引入的多语言NLP系统,通过预训练的工业领域翻译模型,自动将不同语言的文本转化为统一格式的中间表示(如英语),再进一步解析为结构化数据,对于一条日语指令“次の工程で、ロボットアームの速度を5%上昇させてください”(下一工序中,请将机械臂速度提高5%),系统能先将其翻译为英语“In the next process, please increase the speed of the robotic arm by 5%”,再提取出关键动作“increase speed”、目标设备“robotic arm”和参数“5%”,最终转化为数字孪生模型可执行的指令,这一过程不仅消除了语言障碍,还通过中间表示层确保了指令的准确性——即使原始文本存在语法错误或口语化表达,系统也能通过上下文理解其真实含义。 本月绿色使用与数字乡村及储能材料热度持续攀升,相关技术取得新突破
动态优化:从“被动解析”到“主动学习”
早期的NLP系统在工业场景中往往扮演“被动解析”的角色,即根据预设规则或模型处理输入文本,但2026年的实践表明,更先进的系统已具备“主动学习”能力,能根据实时数据动态优化解析逻辑,提升数字孪生的预测精度。
2026年户外活动与青少年教育及西医诊疗热度持续攀升,相关产业迎来新机遇 以美国通用电气(GE)在航空发动机制造中的实践为例,GE的数字孪生系统需要处理来自全球数千台在役发动机的运维数据,这些数据包括工程师的维修报告、传感器的实时监测值和历史故障记录,传统NLP系统在处理这些数据时,往往依赖固定的关键词匹配规则,例如将“振动异常”与“故障预警”关联,但GE发现,不同型号的发动机、不同运行环境下的“振动异常”可能对应完全不同的故障模式——在高温环境下,轻微的振动可能是正常现象,而在低温环境下则可能预示轴承磨损。

为此,GE引入了基于强化学习的NLP系统,该系统通过与数字孪生模型的深度集成,根据发动机的实时运行状态(如温度、压力、转速)动态调整文本解析的权重,当系统检测到发动机处于高温环境时,会降低对“振动异常”的敏感度,同时增加对“温度超限”的关注;反之,在低温环境下,系统会重点分析振动相关的文本描述,这种动态优化机制使数字孪生模型的故障预测准确率提升了23%,同时将误报率降低了17%。 本月聚焦基因检测与绿色土壤修复及零碳工厂发展新趋势,应用场景不断拓展
人机协作:NLP让“数字孪生”更“懂人”
2026年健康中国与志愿服务活动热度持续攀升,相关领域迎来新突破 工业数字孪生的最终目标是实现人机协作的智能化,而NLP技术正在让这一目标变得更近,2026年,中国中车在某高铁列车制造车间的实践显示,通过NLP技术,工程师可以直接用自然语言与数字孪生系统交互,无需学习复杂的编程语言或操作界面。
当工程师发现某节车厢的空调系统能耗异常时,他可以对着系统说:“查看3号车厢空调过去24小时的能耗数据,并对比同型号车厢的平均值。”系统通过语音识别将指令转化为文本,再通过NLP解析出关键动作“查看数据”、目标设备“3号车厢空调”、时间范围“过去24小时”和对比对象“同型号车厢平均值”,最终从数字孪生模型中提取相关数据并生成可视化报告,整个过程仅需10秒,而传统方式下,工程师可能需要手动操作多个软件界面,耗时数分钟。
更进一步的是,系统还能通过NLP的意图识别能力,主动提供建议,当工程师询问“为什么3号车厢空调能耗高”时,系统不仅能展示历史数据,还能结合知识图谱分析可能的原因(如“滤网堵塞”“制冷剂不足”或“运行模式设置不当”),并推荐相应的维护措施,这种“懂人”的交互方式,显著提升了工程师的工作效率,也让数字孪生系统从“数据展示工具”升级为“智能决策助手”。
NLP,工业数字孪生的“隐形引擎”
从数据解析到跨语言交互,从动态优化到人机协作,自然语言处理技术正在工业数字孪生的各个环节发挥关键作用,它像一条无形的逻辑链条,将人类的语言、设备的信号与虚拟的模型紧密连接,让数字孪生不再是一个孤立的“数字镜像”,而是一个能理解、能学习、能决策的智能系统,2026年的实践表明,随着NLP技术的不断进化