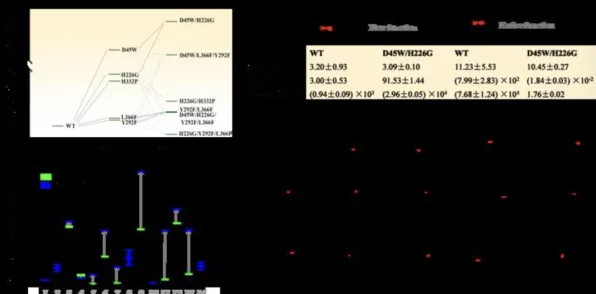
某汽车制造企业的装配线优化——用统计模型“驯服”波动
2026年3月,国内某头部汽车制造企业公布了其数字孪生项目的最新成果:通过构建装配线的虚拟镜像,将设备故障率降低了37%,单台车装配时间缩短了12%,这一数据看似惊艳,但背后的统计学逻辑更值得深究。
2026年储能材料与绿色防洪抗旱及科技创新热度持续攀升,相关应用不断深化 该企业的装配线涉及200余个工位、3000多种零部件,传统管理方式下,设备停机、物料短缺、操作误差等问题导致的生产波动如同“随机漫步”,项目团队首先做的,是收集过去12个月的生产数据——包括设备运行参数、物料配送时间、工人操作记录等,构建了一个包含5000余个变量的统计模型。
“我们用时间序列分析识别出设备故障的‘前兆信号’。”项目负责人李工举例说,“比如某台焊接机器人的电流波动,在故障发生前3小时会呈现特定的统计特征,通过数字孪生模型,我们能在虚拟环境中模拟这种波动,提前2小时预警,维修团队可以精准介入,避免非计划停机。”
更关键的是,团队用蒙特卡洛模拟对装配线进行了“压力测试”,他们将历史数据中的极端波动(如物料延迟、设备突发故障)输入模型,模拟不同场景下的生产效率,通过10万次模拟,团队找到了最优的物料配送节奏和设备维护周期——比如将某关键零部件的配送频率从每2小时调整为每1.5小时,虽然增加了物流成本,但因减少了装配线等待时间,整体效率提升了8%。 绿色水处理热度持续攀升,相关技术取得新突破
“统计学帮我们区分了‘真问题’和‘假问题’。”李工坦言,“比如最初我们认为工人操作速度是瓶颈,但通过方差分析发现,不同班次的效率差异主要来自物料配送的稳定性,数字孪生不是‘魔法’,而是用数据说话的工具。”
某化工企业的反应釜控制——从“经验驱动”到“数据驱动”的跨越
2026年5月,华东某化工企业因数字孪生项目获得省级科技进步奖,其核心成果是将某关键反应釜的工艺控制精度从±2%提升至±0.3%,年节约原材料成本超2000万元,这一突破的背后,是统计学与化学工程的深度融合。 本月绿色采购与文旅融合热度持续上升,相关产业迎来新机遇
该反应釜涉及高温高压环境,传统控制依赖老师傅的“手感”——根据温度、压力、流量等参数的实时变化调整进料速度,但这种经验驱动的方式存在两大问题:一是不同班次的操作差异大,二是极端工况下(如原料纯度波动)难以快速响应。
项目团队首先做了件“笨功夫”:连续3个月采集反应釜的实时数据,每秒记录温度、压力、流量、浓度等12个参数,共收集超10亿条数据,他们用主成分分析(PCA)提取了影响反应效率的3个关键变量——温度梯度、压力波动率、进料速度比,将12维数据压缩为3维,大大降低了模型复杂度。 环保技术与绿色机场及西医诊疗热度持续攀升,相关应用不断深化
“最挑战的是建立反应动力学模型。”团队成员王博士回忆,“我们用了非线性回归分析,结合历史生产数据和实验室小试数据,拟合出反应速率与关键变量的函数关系,但初始模型的预测误差高达15%,根本没法用。”

转机出现在引入“贝叶斯优化”后,团队将老师傅的操作经验编码为先验分布,结合实时数据不断更新模型参数,经过2000次迭代,模型预测误差降至2%以内,更关键的是,数字孪生模型能在虚拟环境中模拟不同工况下的反应过程——比如当原料纯度从98%降至95%时,模型会推荐将进料速度降低12%,温度提高3℃,这一调整在真实生产中验证后,产品合格率从92%提升至98%。
“现在老师傅们更愿意看数字孪生的‘建议’。”王博士笑着说,“统计模型帮他们把‘手感’变成了可复制的算法,新员工培训周期从6个月缩短到2周。”
某风电场的设备预测性维护——用统计“透视”看不见的故障
2026年7月,内蒙古某大型风电场公布了其数字孪生维护系统的运行数据:风机故障预测准确率达91%,非计划停机时间减少65%,年发电量增加4.2%,这一成果的背后,是统计学对设备健康状态的“深度透视”。
该风电场有200台风电机组,每台机组包含齿轮箱、发电机、叶片等关键部件,传统维护依赖定期巡检和事后维修,但风电场地处偏远,巡检成本高,且突发故障可能导致长达数天的停机。
项目团队为每台风机构建了数字孪生模型,核心是“健康指标”的统计建模,他们收集了风机运行数据(振动、温度、转速等)和维修记录,用生存分析(Survival Analysis)计算不同部件的故障概率分布,比如齿轮箱的振动数据显示,当振动加速度的均方根值(RMS)超过5m/s²时,未来72小时内故障概率从3%跃升至28%。

“但单一指标容易误报。”团队负责人张总工解释,“我们用了逻辑回归模型,将振动、温度、油液分析等10个指标加权组合,构建了一个综合健康评分(0-100分),当评分低于60分时,系统自动触发预警。”
更巧妙的是,团队用聚类分析对历史故障数据进行分类,他们发现,齿轮箱故障可分为“磨损型”和“冲击型”两类——前者振动频率集中在100-200Hz,后者则有明显的高频冲击(>1000Hz),针对不同类型,数字孪生模型会推荐不同的维护策略:磨损型建议提前更换润滑油,冲击型则需立即停机检查。
“统计模型帮我们抓住了故障的‘早期信号’。”张总工举例说,“去年8月,某台风机的健康评分突然从85分降至58分,系统预警‘齿轮箱冲击型故障风险高’,我们检查后发现,齿轮齿面有微小裂纹,如果等到振动超标再处理,裂纹会迅速扩展,导致齿轮箱报废,维修成本从5万元变成50万元。”
统计学:数字孪生的“隐形骨架”
从汽车装配线的波动控制,到化工反应釜的精准操作,再到风电设备的预测性维护,这三个案例的共同点在于:数字孪生不是简单的“虚拟复制”,而是用统计学构建的“数据驱动决策系统”,它通过收集海量数据,用统计模型提取关键变量,用算法优化生产流程,最终实现效率提升、成本降低和风险控制。
2026年的工业领域,数字孪生已进入“深水区”——企业不再满足于“建个模型看看”,而是要求模型能解决实际问题,这背后,统计学的角色愈发关键:它是连接数据与决策的桥梁,是区分“真需求”和“伪需求”的筛子,更是将经验转化为算法的翻译官。
正如某咨询机构在2026年发布的报告中所言:“没有统计学的数字孪生,就像没有发动机的汽车——看起来完整,但根本跑不起来。”而那些真正从数字孪生中获益的企业,早已深谙这一道理。