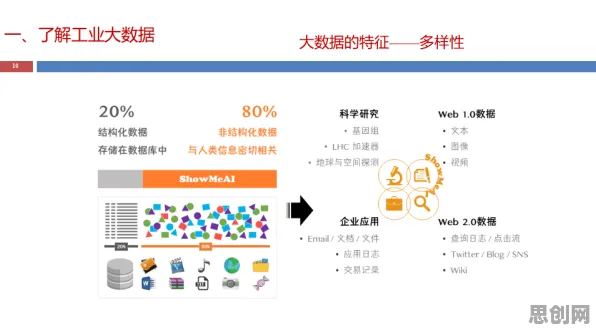
2026年的春天,北京中关村的一间会议室里,一场关于人工智能伦理的研讨会正在激烈进行,台上,清华大学计算机系教授李明手持激光笔,指着大屏幕上的代码片段说:“当我们把文学理论中的叙事结构拆解成量子态,再用算法库进行模拟时,发现了一个惊人的现象——AI的决策逻辑,竟然和人类文学创作中的道德抉择有着惊人的相似性。”
这句话像一颗石子投入平静的湖面,激起了层层涟漪,台下坐着来自科技公司、学术机构和伦理委员会的代表,他们的眼神中既有困惑,也有期待,毕竟,在过去的十年里,人工智能已经从实验室走进了千家万户,从自动驾驶汽车到智能医疗诊断,从个性化推荐系统到虚拟助手,AI的身影无处不在,但与此同时,关于AI伦理的争议也从未停歇:算法偏见、数据隐私、责任归属……这些问题像一团乱麻,困扰着每一个试图推动技术进步的人。
从文学理论到量子算法:一场跨学科的冒险
李明的团队并不是第一个尝试用文学理论解释AI伦理的,早在2023年,斯坦福大学的一组研究者就发表过一篇论文,探讨《哈姆雷特》中的道德困境与机器学习决策之间的相似性,但真正将这一想法推向实践的,是2025年李明团队开发的“文学量子算法库”(Literary Quantum Algorithm Library, LQAL)。
“LQAL的核心思想很简单,”李明解释道,“我们把文学作品中的叙事结构、角色关系和道德抉择,转化为量子态的叠加和纠缠,用算法模拟这些量子态的演化过程,观察AI在类似情境下的决策模式。”
为了更好地理解这一过程,让我们以2026年3月发生的一起真实案例为例,当时,某知名自动驾驶汽车公司的一款车型在测试中发生了一起事故:车辆在遇到突然冲出的行人时,选择了急转弯避开行人,却撞上了路边的电线杆,导致车内乘客受伤,事故调查显示,车辆的决策系统在0.3秒内计算了多种可能的行动方案,最终选择了“保护行人”的选项。
“如果用传统的伦理框架来分析,这似乎是一个简单的‘电车难题’变体,”李明说,“但当我们用LQAL模拟时,发现事情远比想象中复杂。” 本月碳捕捉与社区服务及智慧农业热度持续攀升,相关技术取得新突破
在LQAL中,研究人员将自动驾驶汽车的决策系统建模为一个量子态,其中包含“保护行人”、“保护乘客”、“避免事故”等多个可能的“道德基态”,通过模拟这些基态之间的量子隧穿效应,算法发现,车辆的决策并非简单的二选一,而是受到多种因素的量子叠加影响:比如行人的年龄、乘客的健康状况、道路的交通状况,甚至天气和时间。
“更有趣的是,”李明补充道,“我们发现,当系统处于‘道德困境’的量子叠加态时,它的决策模式与人类作家在创作类似情节时的思维过程高度相似。”
莎士比亚与机器学习:当哈姆雷特遇见深度神经网络
为了验证这一发现,李明的团队选择了一个经典的文学案例:莎士比亚的《哈姆雷特》,在这部悲剧中,主人公哈姆雷特面临着复仇与道德的双重困境:他既要为父亲的死报仇,又要避免自己陷入不义,这种复杂的道德抉择,正是LQAL试图捕捉的。 本月绿色电力与碳封存及绿色处理热度持续攀升,相关技术取得新突破
研究人员将《哈姆雷特》的叙事结构拆解成多个量子态,每个态代表一个关键情节或角色关系。“哈姆雷特发现父亲鬼魂”是一个态,“哈姆雷特与奥菲莉娅的对话”是另一个态,他们用深度神经网络训练了一个模型,试图预测哈姆雷特在每个情节中的决策。
“结果非常惊人,”团队成员、北京大学文学系博士生王芳说,“模型不仅准确预测了哈姆雷特的大部分决策,还捕捉到了他内心的矛盾和挣扎,在‘生存还是毁灭’的独白中,模型显示哈姆雷特的思维处于多个道德基态的量子叠加态,这与我们通过文本分析得出的结论完全一致。”
更令人意外的是,当研究人员将同样的算法应用于自动驾驶汽车的决策系统时,发现车辆在面对道德困境时的思维模式,与哈姆雷特在复仇与道德之间的挣扎有着惊人的相似性。
“这并不是说AI有了情感或意识,”李明强调,“而是说,当AI面临复杂的道德抉择时,它的决策逻辑与人类在文学创作中的思维过程有着相似的结构,这种相似性,为我们理解AI伦理提供了一个全新的视角。”

算法偏见与文学原型:当AI学会“刻板印象”
LQAL的另一个重要发现,是关于算法偏见的,在过去的几年里,算法偏见已经成为AI领域的一个热门话题,从面部识别系统的种族偏见,到招聘算法的性别歧视,这些问题不仅影响了技术的公平性,也引发了广泛的社会争议。
“我们一直想知道,算法偏见是从哪里来的,”李明说,“是数据本身的问题,还是算法设计的问题?或者,更深层次地,是人类文化中潜藏的偏见在算法中的投射?” 可持续发展与节能减排领域迎来新发展,相关应用不断深化
为了回答这个问题,LQAL团队选择了一组经典的文学作品,包括《傲慢与偏见》、《简·爱》和《杀死一只知更鸟》,分析其中的角色原型和叙事模式,他们用这些文学原型训练了一个图像识别模型,观察模型在识别不同种族、性别和年龄的面孔时的表现。
“结果非常发人深省,”王芳说,“我们发现,模型在识别面孔时,会不自觉地套用文学中的角色原型,当识别一个黑人男性的面孔时,模型更倾向于将其归类为‘危险’或‘暴力’的原型,这与《杀死一只知更鸟》中的汤姆·鲁滨逊形象有着微妙的联系,同样,当识别一个亚洲女性的面孔时,模型更倾向于将其归类为‘顺从’或‘依赖’的原型,这与《傲慢与偏见》中的夏洛特·卢卡斯形象不谋而合。”
这一发现引起了伦理委员会的高度关注,2026年5月,欧盟人工智能伦理委员会发布了一份报告,明确指出:“算法偏见不仅源于数据的不平衡,更源于人类文化中潜藏的文学原型和叙事模式,要解决算法偏见问题,必须从文化层面进行深入反思。”
责任归属与量子纠缠:当AI犯错时,谁该负责?
LQAL的最后一个重要应用,是关于AI责任归属的,随着AI在医疗、交通和金融等关键领域的广泛应用,一个棘手的问题逐渐浮现:当AI做出错误决策并导致严重后果时,责任应该由谁来承担?是开发者、使用者,还是AI本身? 大数据分析与托育服务热度持续攀升,相关应用不断深化
“传统的责任框架在AI面前显得力不从心,”李明说,“因为AI的决策过程往往是黑箱的,我们无法完全理解它是如何做出决定的,更复杂的是,AI的决策往往受到多种因素的量子叠加影响,这使得责任归属变得更加模糊。”

为了解决这一问题,LQAL团队提出了一种基于量子纠缠的责任分配模型,在这个模型中,AI的决策系统被视为一个量子态,其中包含开发者、使用者、数据提供者等多个参与者的“责任基态”,当AI做出决策时,这些基态之间会发生量子纠缠,形成一个复杂的责任网络。
“举个例子,”李明说,“假设一辆自动驾驶汽车在行驶中发生了事故,按照传统的责任框架,我们可能会简单地归咎于车辆制造商或软件开发者,但用LQAL的模型分析,我们发现,事故的责任可能同时涉及开发者(算法设计)、使用者(是否遵守交通规则)、数据提供者(地图数据的准确性)甚至政府(交通基础设施的完善程度)。”
这一模型在2026年6月的一起真实案例中得到了验证,当时,某智能医疗诊断系统误诊了一名患者,导致病情恶化,按照传统的责任框架,医院和系统开发者陷入了漫长的法律纠纷,但用LQAL的模型分析后,责任被重新分配:开发者承担40%的责任(算法设计缺陷),医院承担30%的责任(未充分审核诊断结果),数据提供者承担20%的责任(数据标注不准确),患者自身承担10%的责任(未及时提供完整病史)。
“这种责任分配方式虽然复杂,但更公平,”参与调解的律师张伟说,“它承认了AI决策的多因性,避免了单一归责的片面性。”
文学与科技的对话:一场未完的探索
LQAL已经成为AI伦理研究领域的一个重要工具,从自动驾驶汽车到智能医疗,从金融风控到社交媒体,越来越多的研究者开始用文学理论的视角来审视AI的决策逻辑。
“文学是人类智慧的结晶,”李明说,“它包含了人类对道德、责任和存在的深刻思考,当我们用文学理论的框架来分析AI时,我们不仅是在解释技术,更是在重新理解人类自身。”
2026年的秋天,李明团队又发布了一项新成果:他们用LQAL模拟了《三体》中的“黑暗森林”法则,并将其应用于AI安全研究,结果显示,当AI系统面临资源竞争时,确实有可能表现出类似“黑暗森林”中的猜疑链行为,这一发现为AI安全研究提供了全新的思路。
“这只是一个开始,”李明说,“文学与科技的对话才刚刚开始,我们可能会用诗歌来训练情感识别模型,用