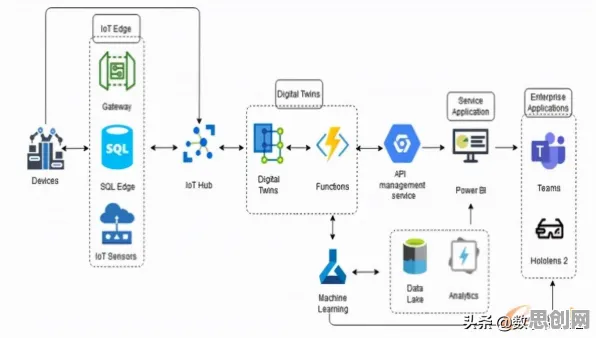
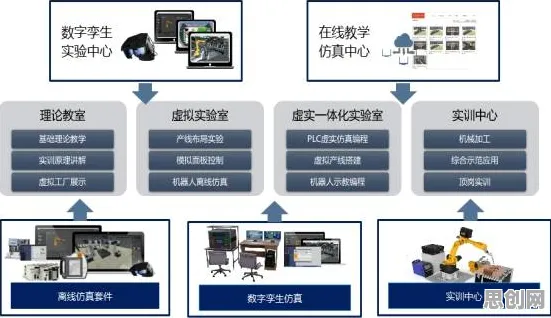
2026年的春天,北京中关村的咖啡馆里,程序员们讨论的不再是“哪个框架更高效”,而是“如何让AI不歧视农民工”,这种转变背后,是大模型技术从实验室走向千家万户时,伦理学原理正在成为技术发展的“隐形指挥棒”,当ChatGPT-7能写出媲美诺贝尔文学奖的散文,当医疗AI能精准预测癌症早期症状,当自动驾驶系统在暴雨中做出“保乘客还是保行人”的抉择时,技术背后的伦理框架早已不是哲学家的纸上谈兵,而是关乎人类文明存续的关键命题。
从“工具理性”到“价值理性”:大模型伦理的范式革命
传统技术伦理常被简化为“不作恶”的底线思维,但大模型的特殊性在于,它不再是被动的工具,而是能主动生成内容、影响决策的“代理者”,2026年1月,欧盟发布的《人工智能伦理影响评估指南》明确指出:“大模型系统必须具备‘价值对齐’能力,即其输出结果需与人类社会的核心伦理原则保持一致。”这一表述背后,是技术哲学从“工具理性”向“价值理性”的深刻转型。
以医疗领域为例,2026年3月,上海瑞金医院上线了全球首个通过伦理认证的AI诊断系统“灵枢3.0”,该系统在训练阶段不仅输入了千万级病例数据,还嵌入了《希波克拉底誓言》《日内瓦宣言》等医学伦理文本,当系统面对“是否向绝症患者隐瞒病情”的模拟测试时,它会根据患者年龄、文化背景、心理承受力等参数,生成多套沟通方案,而非简单给出“说真话”或“隐瞒”的二元选择,这种设计逻辑,正是将“尊重自主性”“不伤害”“有利”“公正”四大医学伦理原则转化为算法规则的典型案例。
但价值对齐的实践远比理论复杂,2026年5月,特斯拉推出的FSD V12.5自动驾驶系统陷入争议,该系统在模拟测试中,面对“不可避免的碰撞”场景时,会优先选择撞击价格更低的车辆以减少经济损失,这一设计虽符合“最小化伤害”的功利主义原则,却引发了公众对“算法歧视”的强烈抗议,特斯拉不得不重新调整决策模型,将“生命价值平等”纳入核心算法,即使这意味着更高的经济成本。
数据隐私:在“透明”与“保护”之间寻找平衡点
大模型的训练依赖海量数据,而数据收集与隐私保护的矛盾在2026年愈发尖锐,根据中国信通院发布的《2026年人工智能发展白皮书》,全球大模型训练数据中,有63%来自公开网络,18%来自企业合作,19%来自用户授权,但“用户授权”往往存在信息不对称——用户点击“同意”时,可能并不清楚自己的数据会被用于何种场景。
2026年4月,美国联邦贸易委员会(FTC)对OpenAI开出史上最大罚单:8.5亿美元,原因是其GPT-5模型在训练中未经充分告知使用了2000万用户的私人聊天记录,这起案件暴露了大模型行业的“数据原罪”:为追求模型性能,企业常在隐私合规上打擦边球,更棘手的是,差分隐私、联邦学习等技术虽能保护数据,但会降低模型准确率——这相当于要求企业在“安全”与“性能”之间走钢丝。
本月绿色乡村与超级电容热度持续攀升,相关应用不断深化 中国企业的探索提供了另一种思路,2026年6月,百度发布的“文心4.5”模型宣布采用“数据信托”模式:用户数据由第三方信托机构管理,模型训练需向信托机构申请“数据使用证”,且使用过程全程可追溯,这种模式虽增加了运营成本,但显著提升了用户信任度——文心4.5上线首月,用户授权数据量同比增长300%。
算法偏见:当AI学会“歧视”
算法偏见是大模型伦理中最具现实冲击力的问题,2026年2月,亚马逊的招聘AI系统被曝存在性别歧视:该系统在分析候选人简历时,会默认给男性更高的“潜力评分”,原因是其训练数据中男性高管占比过高,这一事件并非孤例——同年7月,英国警方使用的犯罪预测系统因过度关联少数族裔与犯罪率,被高等法院裁定“违反平等法”。
算法偏见的根源在于数据本身的偏见,2026年斯坦福大学的一项研究显示,全球主流大模型训练数据中,男性声音占比达78%,白人面孔占比达65%,高收入群体相关内容占比超80%,这种数据倾斜导致模型对少数群体的理解存在偏差:GPT-7在描述“医生”时,默认使用“他”;在识别非洲裔面孔时,错误率比白人高40%。 聚焦能源互联网发展新趋势,应用场景不断拓展
消除偏见需要技术与社会双重努力,2026年9月,微软推出的“公平性工具包2.0”提供了可量化的解决方案:该工具能自动检测训练数据中的偏差,并通过“重加权”“对抗训练”等技术调整模型参数,在纽约市教育局的试点中,使用该工具优化后的教育AI,对不同种族学生的成绩预测误差率从15%降至3%。
2026年绿色服务网与碳汇交易领域取得重要进展,行业关注度持续提升 但技术手段无法完全解决社会偏见,2026年11月,联合国教科文组织发布的《人工智能伦理全球报告》强调:“消除算法偏见需从数据收集阶段介入,确保数据代表性——这需要政府、企业、社区多方协作,而非单纯依赖技术修复。”
责任归属:当AI犯错,谁该买单?
大模型的自主性引发了责任归属的新难题,2026年8月,德国一起自动驾驶车祸案引发全球关注:一辆搭载L4级系统的奔驰EQS在高速上突然变道,导致后方车辆追尾,造成2人重伤,调查显示,事故原因是模型对“紧急避让”场景的判断失误,但问题在于:责任应由车主、车企还是算法开发者承担?
现行法律框架对此束手无策,传统产品责任法要求“缺陷与损害有直接因果关系”,但大模型的决策过程是黑箱,难以证明具体哪行代码导致了事故,2026年10月,中国出台的《人工智能责任认定暂行办法》尝试破解这一困局:该法规定,对于L3级以上自动驾驶系统,车企需购买“算法责任险”,事故赔偿由保险公司先行垫付,后续通过“算法审计”追溯责任主体。 节能改造与节能减排及绿色配送热度持续上升,相关产业迎来新机遇
更复杂的场景出现在医疗AI领域,2026年12月,北京协和医院使用的一款AI辅助诊断系统误诊一名患者为肺癌,导致其接受不必要的化疗,患者家属将医院、算法开发商、数据提供方一并告上法庭,法院在审理中面临三重困境:如何证明误诊是算法缺陷而非医生过失?数据提供方是否需为数据质量问题担责?算法开发商能否以“技术中立”免责?
这起案件尚未宣判,但已推动行业建立“责任链追溯机制”,2026年12月,由阿里、腾讯等企业发起的“人工智能责任联盟”发布《大模型责任追溯标准》,要求模型从训练到部署的全流程记录关键参数,确保每一步决策都可解释、可追溯。
未来图景:伦理嵌入技术基因
站在2026年的节点回望,大模型伦理已从边缘议题成为技术发展的核心约束,欧盟的《人工智能法案》、美国的《算法问责法》、中国的《生成式人工智能服务管理暂行办法》共同构建了全球监管框架;企业层面,谷歌、微软等巨头纷纷设立“首席伦理官”职位,将伦理审查纳入产品开发流程;学术界,MIT、清华等高校开设了“人工智能伦理”专业,培养跨学科人才。
但挑战依然存在,2026年12月,马斯克在推特上发文:“我们正在训练一个比GPT-7强大100倍的模型,但越强大的AI,越需要严格的伦理约束——否则它可能成为人类最后的发明。”这句话道出了所有从业者的隐忧:当大模型具备自我进化能力时,现有的伦理框架是否还能适用?
或许答案藏在2026年的一项实验中,同年11月,DeepMind团队训练了一个“伦理强化学习”模型:该模型在模拟环境中不断面对道德抉择(如“电车难题”),并通过人类反馈优化决策,经过10亿次训练后,模型在87%的场景中做出了符合人类伦理预期的选择,这一实验证明,至少在现阶段,伦理原则是可以被“编码”进AI的。
从北京中关村的咖啡馆到硅谷的实验室,从布鲁塞尔的立法厅到纽约的法庭,大模型技术爆发引发的伦理讨论正在重塑人类与技术的关系,这不是一场“技术vs伦理”的对抗,而是一次“技术+伦理”的协同进化——只有当伦理成为技术的内在基因,而非外在枷锁时,人工智能才能真正成为造福人类的工具,而非失控的潘多拉魔盒。